

At GitGuardian, we love PostgreSQL. Since our inception in 2017, it has enabled us to serve hundreds of thousands of users and store billions of records. It supports both our self-hosted offering and our SaaS platform. Calling it "mission-critical" would be almost an understatement.
While our self-hosted solution has been supporting PostgreSQL versions 13 to 16 to meet our customers' requirements, our SaaS deployment was still on version 13 a few months ago. This version's end-of-life (EOL) was rapidly approaching.
Delaying the upgrade was now becoming a security concern. It would have meant missing out on crucial security updates from the very active community. For a security company, this made the upgrade a top priority.
And I couldn't be more excited!
Upgrading three major versions was set to introduce a bunch of new features. It would likely bring some performance improvements too.
In this blog post, I'll present the framework we used to benchmark PostgreSQL version 16. I'll let you read this article and draw your own conclusions, but here's a spoiler: yes, this major version upgrade brought significant performance improvements. Let's dive in and see how.
A refresher on PostgreSQL release cycle (and how upgrading works)
For those unfamiliar with SQL technology, here's a quick recap: SQL is a declarative language, which means you don't describe exactly how the database management system (DBMS) should compute the result. Instead, you tell the software what result you want. It's then the software's job to give you the correct result as quickly as possible.
Regarding the PostgreSQL development lifecycle, let me offer a quick refresher:
- PostgreSQL software versions are expressed as two numbers separated by a dot. The first number is the major version, and the second is the minor version.
- Every year, the community builds and distributes a new major version. It brings new functionality to every aspect of our beloved database. The latest was version 16, first released in September 2023. The next one will be PostgreSQL 17, coming in a few months. Check out the impressive feature list!
- At least quarterly, a new minor version is released for every supported major version. These updates correct bugs and address security issues discovered since the previous release.
How do we ensure a smooth upgrade to a new major version?
- Read all the release notes carefully and check for changes that could impact you.
- Evaluate the impact for developers
- Test your stack using the new major version.
- Test possible upgrade strategies, from simplest to most complex:
- Logical dump/restore
- pg_upgrade
- Logical replication The more complex strategies usually result in shorter downtime. Choose the one that suits your needs.
- Write an upgrade procedure and ensure it's flawless by testing it several times.
We also have a nightly test matrix running to ensure we don't break compatibility with self-hosted supported versions.
Some sanity checks worth remembering:
- Make sure to create a backup before the big upgrade day (and test it)!
- Run your chosen and tested upgrade strategy.
Et voilà, you've got your shiny PostgreSQL running for another handful of years.
The Benchmark
Now to the fun part. Creating the query set allowing consistent benchmark required many iterations.
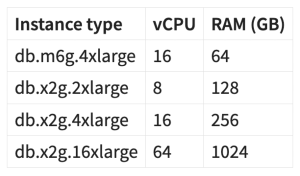
Our SaaS PostgreSQL instance is hosted on RDS. Version 13 was using a db.m6g.4xlarge instance with 16 vCPU and 64 GB of RAM. We were experiencing cache effects on multiple queries: the first run would take several seconds, while subsequent runs took only a few hundred milliseconds. We developed load testing for larger instances to better understand the impact on our workload. Here is a table of the instances we tested:
First attempt: getting all long queries from production
We created a query set containing all of the following:
- DML queries (
SELECT,INSERT,UPDATE, andDELETE) - Transaction commands (
BEGIN,SAVEPOINT,COMMIT, andROLLBACK) - Cursor commands
We initially attempted to split the queries using their logged process IDs (PIDs), aiming to replay them in order and within the correct transaction. However, this approach required too many concurrent clients. Instead, we opted to use the logged client IP addresses.
We activated query logging by setting log_min_duration_statement to 0. This logging ran for 30 minutes on a Monday afternoon, starting at 3:00 PM Paris time.
Testing with this first scenario was inconclusive. The transactions often resulted in errors: write queries created duplicates, and other queries in the transaction were canceled. Recreating the database in the correct state for each run was cumbersome.
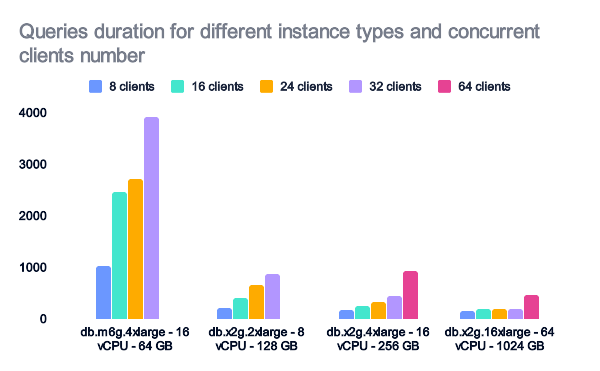
The duration was very similar for each instance, and no bottleneck was apparent.
Second attempt: creating a reproducible and scalable query set
We retrieved all the SELECT logged queries on a Monday. These included queries lasting more than 1 second and a small sample (1/10000th) of queries lasting more than 5 ms.
Since we only collected SELECT queries, we could run them in any order and in auto-commit mode. We had the flexibility to choose any number of concurrent clients to run them. We removed the FOR UPDATE clause from queries that were using it.
While running the queries, we noticed poor performance for several of them. These queries were stacking up and blocking the script from running. We optimized these problematic queries.
We logged all query durations to build pgbadger reports, capturing the Total query duration and the script duration (time between the first and last query). The Top / Histogram of query times proved particularly interesting, as it showed the dispersion of query durations.
RAM upgrade impact
Unsurprisingly, by adding more RAM, the cache more often contains the searched data. This boosted performance:
The performance results could be directly linked to the total amount of data read during the tests.
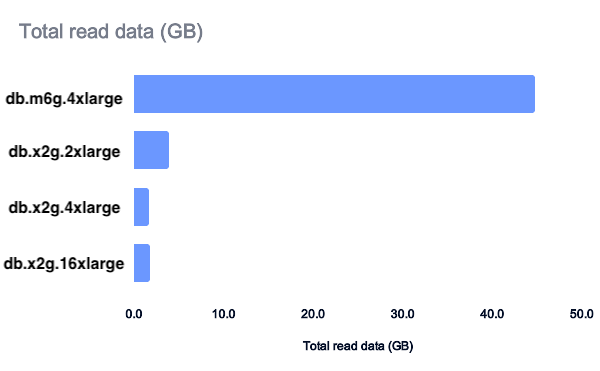
The test suite highlighted the effect of long-running queries. While 128GB of RAM might have sufficed, it would have halved our vCPU count. The benefit of doubling the CPU was noticeable under high load, so we opted to upgrade our instance to a db.x2g.4xlarge. This maintained the same number of vCPUs while quadrupling the RAM to 256 GB.
Performance Impacts
Having the test suite gave us a good opportunity to check our queries against the new versions to ensure there were no regressions. We tested query set 2 on db.m6g.4xlarge and db.x2g.4xlarge instances using PostgreSQL versions 13 through 16. To our surprise, we got a performance boost simply by using the newer versions.
PostgreSQL 13 to 16 features
Here's an extract of the performance improvements in the new versions:
PostgreSQL 14:
- Allows
ANALYZEto do page prefetching, controlled bymaintenance_io_concurrency.- Analysis time on PostgreSQL 13: 85 minutes
- Analysis time on PostgreSQL 14: 11 minutes
- Improves I/O performance of parallel sequential scans.
PostgreSQL 15:
- Improves performance for sorts that exceed work_mem
- Improves performance and reduces memory consumption of in-memory sorts
PostgreSQL 16:
- Allows parallelization of
FULLand internal rightOUTERhash joins - Allows parallelization of FULL and internal right
OUTERhash joins - Allows aggregate functions
string_agg()andarray_agg()to be parallelized - Allows incremental sorts in more cases, including
DISTINCT - Adds the ability for aggregates with
ORDER BYorDISTINCTto use pre-sorted data
Test results
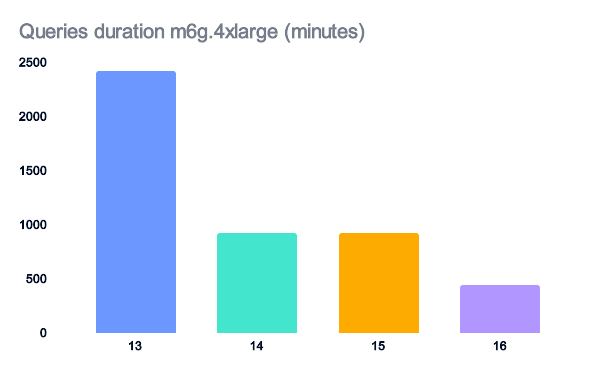
Upgrading to version 14 has a huge impact on systems with limited memory, doubling performance by 2.6 times.
Version 16 provides another substantial performance boost, doubling speed again.
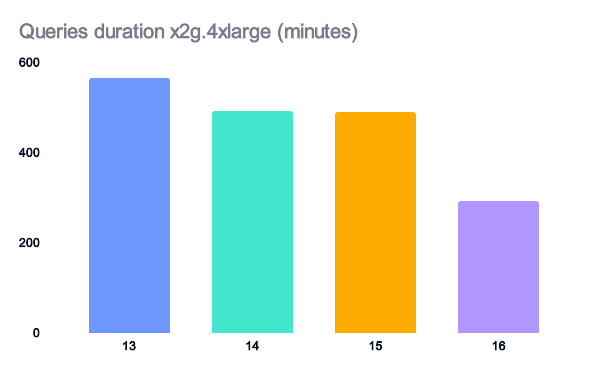
On a system with enough memory, each new version still shows noticeable performance improvements.
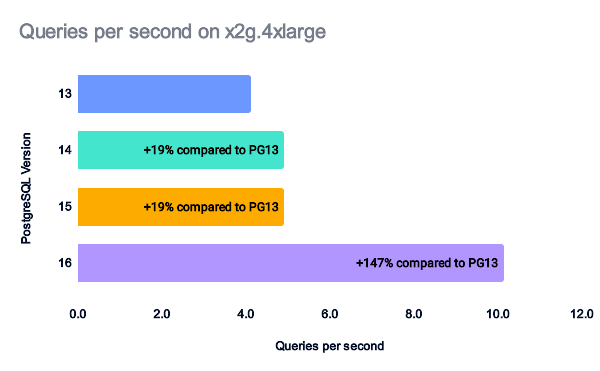
If we compare the queries per second achieved by each PostgreSQL version, we can see some nice performance gains in terms of processed queries per second.
Read and write throughput
To explain the performance differences between the various versions and RDS instance types, we can calculate the total read and write throughput for the tests.
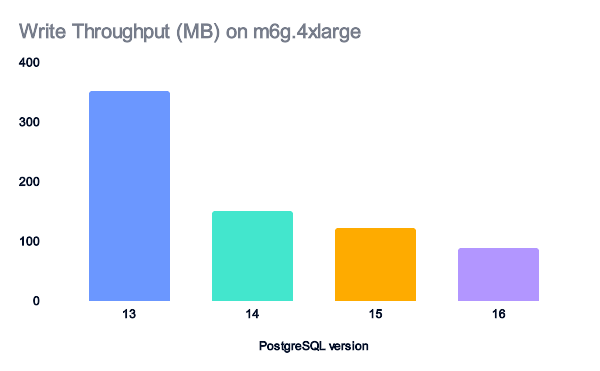
For m6g.4xlarge instances, the read and write throughput helps explain the performance gains we observed.
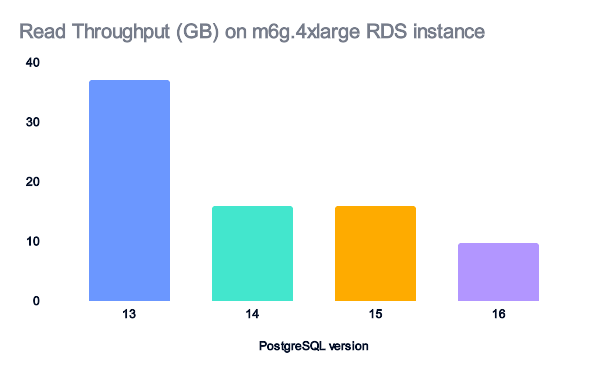
Version 14, then 16, give a huge performance gain on read data, hence the performance gap.
Similar performance gains were observed from PostgreSQL version 13 to 14. Then, a small additional gain was seen in PostgreSQL 16.
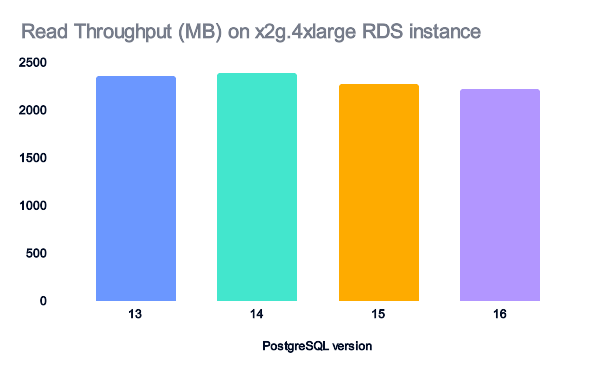
For x2g.4xlarge instances, the data is cached, so the read data doesn't account for the performance improvements.
The amount of written data decreases as the PostgreSQL version increases. However, the amount of written data is minimal and doesn't account for the observed performance improvements.
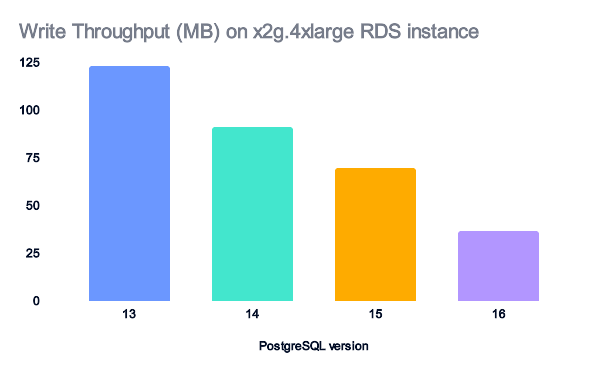
The performance gains might come from better CPU usage, as each new version allows more operations to be parallelized.
Conclusion
PostgreSQL is a brilliant product with a vibrant community.
Each year, it brings new features that can help developers and DBAs. Thanks to its declarative programming paradigm, every performance improvement in PostgreSQL can give your queries a boost.
At least every quarter, you should install the new minor version. Reading the release notes carefully should take you more time than deploying it: you'll just have to install the new package and restart your instance, in a matter of seconds. More time for tackling your backlog, I guess.
In an era where insane power is just a few clicks away, installation and configuration are relatively straightforward and fast. But you should never take for granted that your system will run autonomously forever. Don't forget that monitoring is an absolute necessity.
Fortunately for us, by picking "The World's Most Advanced Open Source Relational Database", we can be less stressed about stability and more about our humongous backlog.
Things can always go wrong, but PostgreSQL is known to be really stable and robust.
When it comes to major versions, every team must find a balance between "let's do it as often as possible" and "let's wait until it's no longer supported."
At GitGuardian, we upgrade PostgreSQL every two or three versions. Each time, we're excited to discover the new features and enjoy the performance gains that come with the upgrade.
En un mot comme en cent: don't wait too long to upgrade your PostgreSQL instance to the newest version. If you are using the GitGuardian self-hosted version, we have a complete migration guide ready for you: Migrate to PostgreSQL 16.
It should come with delightful performance gains!








