


A few weeks ago, we introduced a new Role-based Access Management (RBAC) feature in the GitGuardian Internal Monitoring platform. This release resulted from several months of hard work where we had to thoroughly review our data model and implement a very resource-efficient permissions calculation mechanism. I thought this was the perfect opportunity to offer a deep dive into the research, problems, and dead-end roads we encountered on this journey.
Disclaimer: I’ll be using Django in my code examples, but the ideas can be generalized; however, a relational database is a stronger requirement.
I. Defining the problem
In a nutshell, the RBAC feature creates the notion of “Teams”, a perimeter where each member can see and act upon a restricted number of incidents. In our domain, an incident is a logical unit corresponding to a unique leaked secret. Since a secret can leak in multiple repos, we call occurrences the various locations of this secret in one or more repositories. A set of repos defines a team, so a user belonging to a team can act on any secret detected once or more on one of these repos.
Since an incident can have two occurrences owned by two different teams, our first conceptual problem was: how to distribute incidents across teams?
But that’s not all. We also needed to allow the possibility of giving access to one particular incident to a user or a team. A user has its own perimeter, which is the union of the perimeter of its teams, and the incidents they have been granted access to individually.
Here is a visualization to help you grasp the relationships between these concepts:
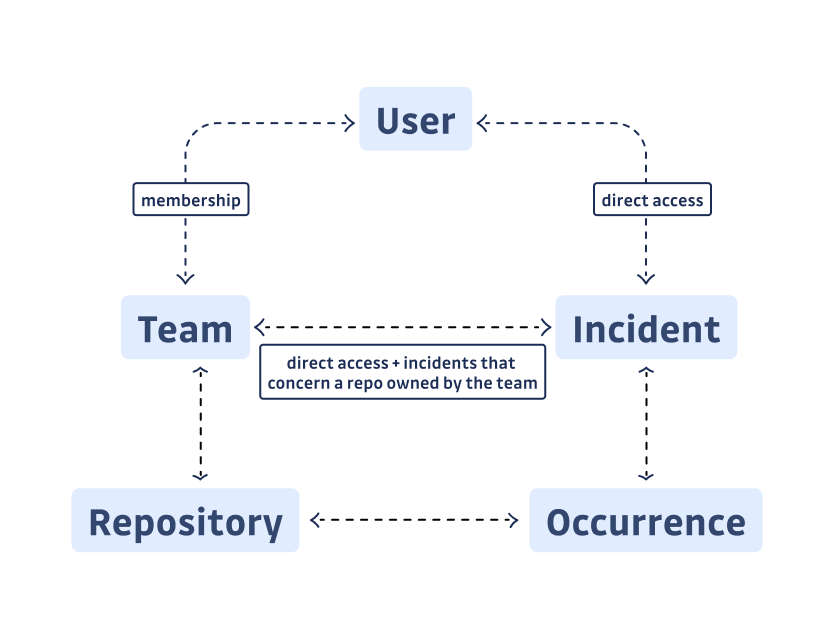
Finally, knowing which incidents are part of the user’s perimeter was just half the story; what we wanted, in the end, was to know what the user could do with them. Here are the three permission levels:
READ: user can see the incidentWRITE: user can act on the incident—ignore, assign, resolve, etc.ADMIN: user can share the incident with other users and teams, adding it to their perimeter.
These permissions can, again, be inherited from the team the user is a member of, or be directly attributed. For a given incident, the user’s permission is therefore the maximum permission level accorded by these two means. And this maximum permission needs to be computed dynamically (on the fly).
Why we didn’t go for the straightforward solution
One straightforward solution would be to have a table persisting per-user permissions. But this would be very difficult to maintain. Why? Let’s imagine a user is removed from a team. The incidents for which he had inherited some permissions by belonging to the team are no longer in the user’s perimeter. Therefore, all the permissions for the team’s incidents should be recomputed, to check if the user lost access or had their permission reduced on the incidents.
Going with a per-user permissions table would necessarily imply a higher order of magnitude in the number of operations necessary to update all the user permissions.
As we wanted to keep table operations as synchronous as possible, we added the permission fields on three relations to dispatch the workload:
- the User-Incident relation
- the Team-Incident relation
- the User-Team relation
After doing some research, we decided to compute these permissions in SQL. Not relying on per-user permissions also meant we could not rely on the common Django permissions libraries (including django.contrib.auth), which are all object-based.
In the table below, we map the number of rows impacted by a new event (new incident, new repo added to a team’s perimeter, etc..). We can see that the per-object solution scales linearly with the number of users in a team. But we don’t want our team sizes to be limited:
| condition | affected # user-incident | affected # of team-incident |
|---|---|---|
| new incident | # of teams × # of team’s users | # of teams |
| new repository in the team | # of repository incident × # of team’s users | # of repository incidents |
| new user in the team | # of team incidents | 0 |
| new team incident (direct access) | # of team users | 1 |
Although we discarded early on the User-Incident relation as the ultimate source of truth, we had to use per-object permissions for the Team-Incident relation. That choice was motivated by performance reasons: the read operation through the Repository and Occurrence tables was too slow, and we made the assumption that the number of teams would be smaller than the number of users.
II. How our model works
A simple trick: using binary masks
Once we defined the permissions specs, we needed to determine how to store them in our database. I mentioned three levels of permission, but it was evident that in the future we would need to add many more to allow more granularity in the business domain roles. To avoid having many boolean fields and to simplify the logic of checking authorizations, we preferred to store authorizations in their binary representation. Thanks to the use of binary masks, we can store all the permissions in a single Integer field.
💡 How to check permissions stored as a binary mask
Let’s say we have 2 resources A and B, and the permissions READ and WRITE
We’ll store that in two bytes. Let’s assume for simplicity that WRITE implies READ,
Cases for A:
0b0011is theWRITE: Apermission0b0001is theREAD: Apermission
Cases for B:
0b1100is theWRITE: Bpermission0b0100is theREAD: Bpermission
and obviously:
0b0000is no permission.
With a bitwise AND, we encode for example 0b0111 as being the WRITE: A and READ: B permission. Conversely, to check a permission, all we have to do is a bitwise AND on the permission mask and the binary value of the field.
So to check if a user has permission WRITE: A, we’ll do 0b0011 & the permission of the user. The result will be equal to the mask only if the user has the permissions:
0b1111&0b0011=0b0011→ OK0b0111&0b0011=0b0011→ OK0b1101&0b0011=0b0001→ not OK0b0000&0b0011=0b0000→ not OK
To implement this in Django we used the IntegerChoices classes, as well as a simple helper to help check permissions in our Python code.
from django.db import models
class Permission(models.IntegerChoices):
READ = 0b001
WRITE = 0b011
ADMIN = 0b111
@classmethod
def is_authorized(
cls, mask: "Permission", scope: "int | Permission"
) -> bool:
"""
GIVEN a mask and a scope
Return true if the scope matches the mask
ex: 0b100 & 0b110 = 0b100 != 0b110
"""
return bool((scope & mask) == mask)Django models
Now that we know the relationships between our objects, and where to store the permissions we need, we can implement it with Django models.
Let’s say we use the default Django User model, here are our models:
class TeamUser(models.Model):
team = ForeignKey("Team", ...)
user = ForeignKey("User", ...)
permission = PositiveSmallIntegerField(default=Permission.READ)
class Team(models.Model):
name = TextField(...)
users = ManyToManyField("User", through="TeamUser", ...)
class TeamIncident(models.Model):
team = ForeignKey("Team", ...)
incident = ForeignKey("Incident", ...)
permission = PositiveSmallIntegerField(default=Permission.READ)
class UserIncident(models.Model):
user = ForeignKey("User", ...)
incident = ForeignKey("Incident", ...)
permission = PositiveSmallIntegerField(default=Permission.READ)
class Incident(models.Model):
name = TextField(...)
teams = ManyToManyField(Team, through="TeamIncident", ...)
users = ManyToManyField(User, through="UserIncident", ...)Quite straightforward, let’s move on to the use cases.
III. Our implementation in practice
Filtering the incidents for a user
First, getting all the incidents of a user, or all users having access to an incident is simple, because the existence of the models themselves implies the READ permission, so we don’t have to check permissions. We can do the following:
# list incidents of user
Incident.objects.filter(Q(users=user) | Q(teams__users=user)).distinct()
# list user having access to an incident
User.objects.filter(Q(incidents=incident) | Q(teams__incidents=incident)).distinct()
The query could be done through subqueries instead. In practice, we leverage the fact that we already have access to the user’s teams to simplify it.
After checking what incidents to display to a user, we want to know which permissions they have on these incidents to know which actions they are allowed to do.
Let’s stay with three permission levels:
0b001isREADwhich allows seeing the incident0b011isWRITE(implyingREAD) which allows acting on the incident0b111isADMIN(implyingREAD+WRITE) which allows granting access to the incident to other users and teams.
And, of course, 0b000 is no permissions at all.
Let’s write the Django query for this, by constructing the user_permission annotation that will contain the aggregated permission of the user on each incident.
A user’s permission within a team is the lowest (computed with the AND binary operation) permission between the permission of the team in the incident and the permission of the user in the team:
F("team__team_incident__permission").bitand(F("team__team_user__permission"))
# and filter the relation by
queryset.filter(team__team_user=user)
And a user’s permission within multiple teams is the highest permission (computed with the OR binary operation) across all teams:
BitOr(
F("team__team_incident__permission").bitand(F("team__team_user__permission")),
output_field=PositiveSmallIntegerField(),
)
BitOr is PostgreSQL specific in DjangoBut the user can also get access to incidents individually, so we’ll use Coalesce(..., 0) that will replace nullish values with 0, our null permission, when the user does not have access through teams, or individually. Otherwise, we couldn’t apply our binary operation (NULL is not a binary value).
user_permission_expression = Coalesce(
BitOr(
F("team_incident__permission").bitand(F("team_incident__team__team_user__permission")),
output_field=PositiveSmallIntegerField(),
),
0,
).bitor(Coalesce(F("user_incident__permission"), 0))
Finally, we filter the queryset for our user:
queryset = Incident.objects.filter(
Q(user_incident__user=user) | Q(team_incident__team__team_user__user=user)
).annotate(user_permission=user_permission_expression).distinct()
Filtering a queryset by permission
We have everything we need, but it’s not yet practical to fetch all the user’s objects for which they have a certain permission level with our binary logic.
We could craft a custom queryset filter, but let’s make something more reusable: let’s define a custom Lookup to implement the Permission.is_authorized method directly in SQL:
class IsAuthorized(Lookup):
"""
GIVEN a mask and a scope
Return true if the scope matches the mask
ex: 0b100 & 0b110 = 0b100 != 0b110
"""
lookup_name = "isauthorized"
def as_sql(self, compiler, connection):
lhs, lhs_params = self.process_lhs(compiler, connection)
rhs, rhs_params = self.process_rhs(compiler, connection)
params = lhs_params + rhs_params + rhs_params
# The binary operation happens here
return "%s & %s = %s" % (lhs, rhs, rhs), params
Field.register_lookup(IsAuthorized)
# usage, assuming the of_user queryset method annotates the user_permission
Model.objects.of_user().filter(user_permission__isauthorized=Permission.WRITE)
It’s important to note that although our incident permissions computation works in all cases, we should not forget about shortcuts.
For example, the Manager role enables access to all the incidents, so it doesn’t make sense to compute the permissions for it. Similarly, the “all-incidents team” provides access to all the organization’s incidents, allowing us to eliminate the perimeter computation.
Also, in paginated endpoints, we just have to compute the permissions on the page we want to return!
We’re done!
Implementing the Teams feature was far from straightforward, and I know that we are not the first engineering team to be confronted with this kind of challenge. It required a thoughtful reflection on the data models we use, and on how to implement the feature with the least possible impact both on performance and on the rest of the application. In the end, I think this was a really good exercise and we learned many things that we will be able to apply to other parts of our code.
Time for our next challenge!








