


This is the first part of a deep dive into the details of DevSecOps applied at every stage of the Software Development Life Cycle.
This week I will introduce this concept with its origins and its recent evolution, and then we will go into the specifics of each stage, starting with planning, analysis and design, where some of the most important decisions are made regarding security.
Then we will analyze the development stage and the recent challenges that led to the emergence of the DevSecOps practices.
1 - An Introduction to the SDLC
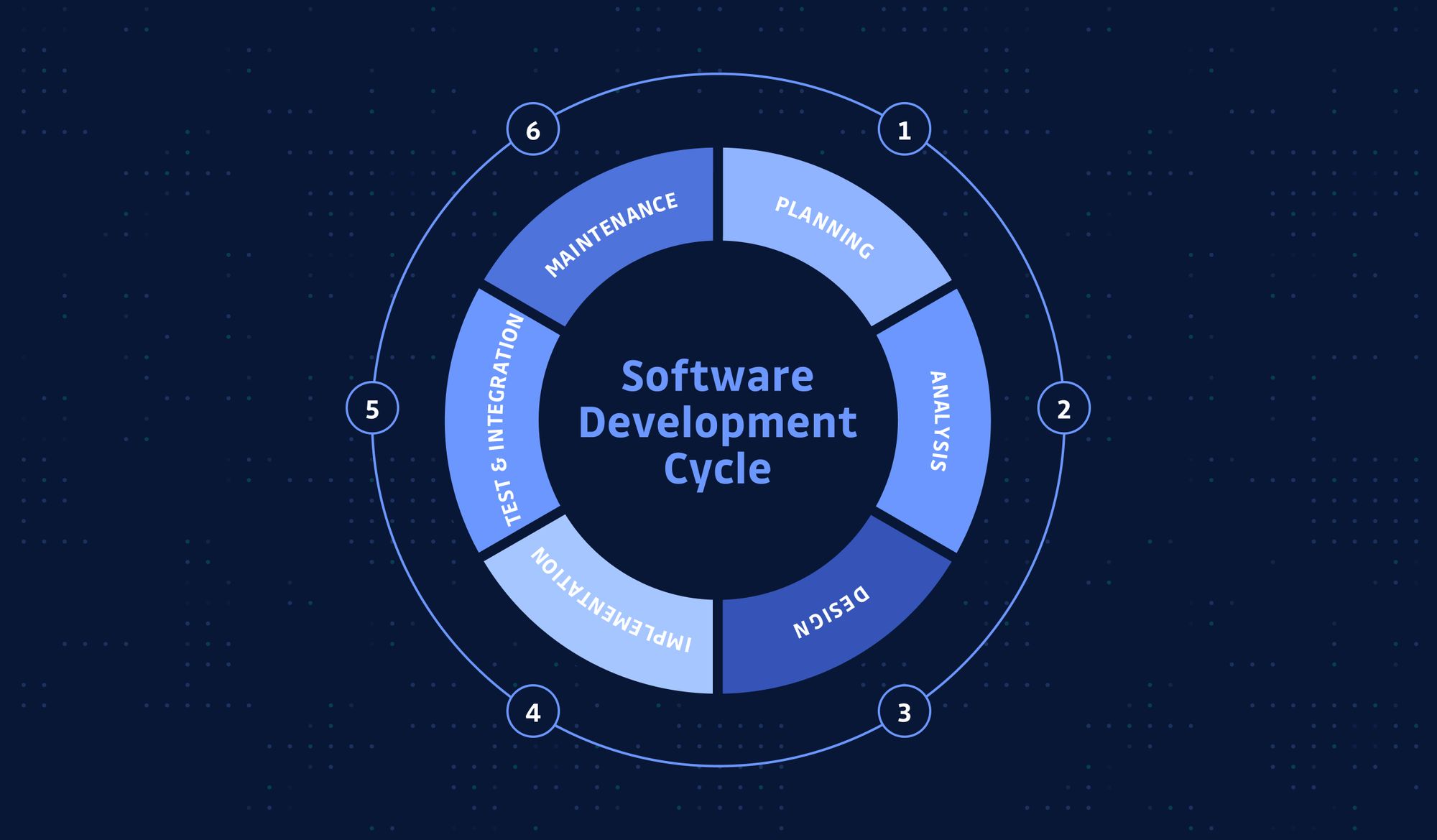
In software engineering, the SDLC (Software Development Life Cycle; might also be referred to as the Application Development Life Cycle) is the process for planning, designing, developing, testing, deploying, and maintaining an information system.
Typically, there are five stages in the SDLC: planning, analysis, design, implementation, and maintenance.
Sometimes, you might see more refined categorization, like separating developing and testing, or making documentation as a standalone stage; or slightly different definitions, like plan/build/test/release/monitor; but the gist is all the same: it should cover the whole cycle of the software development process.
1.1 - The History of Waterfall
Years (or tens of years) ago, we were still doing the SDLC in a monolith and waterfall way. Microservice and agile weren't popular back then or even haven't been invented yet. Frankly, most companies started the monolith way.
Even if we look at Amazon, which is so good at distributed systems, high availability, and agile, it started as a monolith. When Amazon was founded back in the 90s as an online bookstore website, it was a monolith. It still was in 2001. Don't get me wrong, by that point, it had evolved into a multi-tier architecture with different components interacting with each other, of course, but they were so tightly coupled together that they behaved like one giant monolith.
When the product is still both young and straightforward, and you have only two guys in the team, agile would add operational overhead, and microservice would add extra latency.
So, like most companies and projects, Amazon didn't start straight as a multi-region, multi-AZ (availability zone) set up in the first place.
I know what you are thinking: in a world where all we hear is high availability and resiliency, this just sounds wrong. But it made sense in the initial phase of a project. Why pay thousands of server fees when you don't have a whole lot of users yet, and why future-proof a system when it's not even sure whether there will be a future or not?
1.2 - How Did Agile Become a Thing
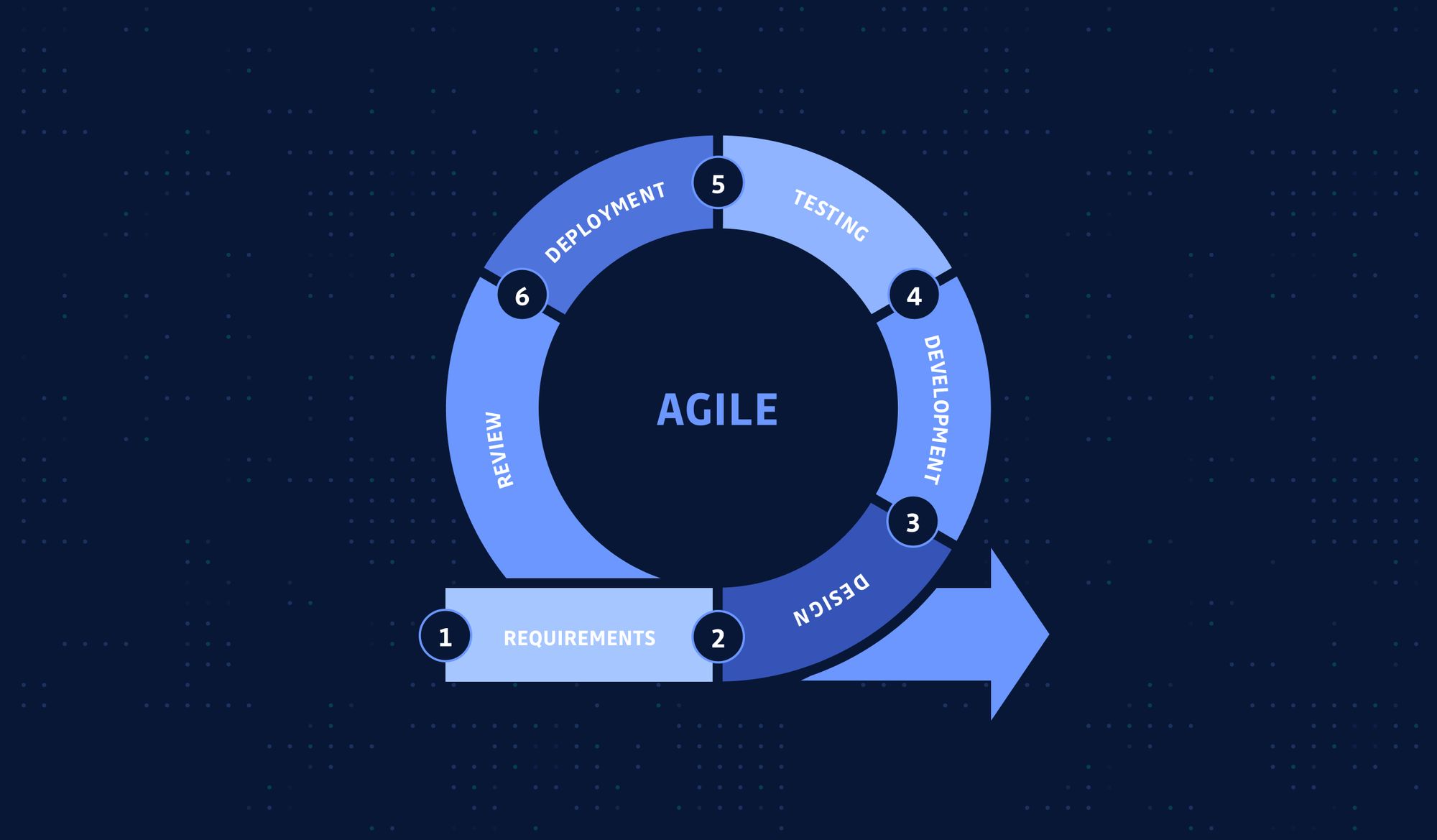
As the project matures, you add more developers to it, the code base becomes more prominent and architecture more complex, the monolith method doesn't work anymore because it adds more overhead to your process, and the SDLC slows down.
This is how agile, microservice (and DevOps) came into life. They were not invented out of nowhere. Instead, they emerged because there was a specific problem to be solved, and it's achieved by separating big teams into smaller ones and monoliths into finer-grained components. But essentially, each smaller agile team and the quicker agile cycle is still following the SDLC.
1.3 - The Security Challenges Agile Has Brought to the SDLC
In the old monolith days, there was only one repo. So, if you were worried that a credential might be accidentally committed to the repo, there was only one place to check. It's not a big deal if it's not automated because you only need to check it in one place, and you probably only need to check it once before the big bang release.
With the emergence of Agile and DevOps, things are different. You got multiple teams and repos and services. They all release every week (or even shorter period). It's physically not possible to manually do it every week for all repos anymore.
This is only one simple example. You might have other issues, like making sure the server's SSH port isn't enabled, like all your databases are not exposed to the public internet, etc. In the old days, a simple check was acceptable, but not anymore.
In a modern setup, you have multiple cross-functioning teams, each team doing its own SDLC alone. Although they are working on different products or components, they have similar problems in the SDLC. Especially, new teams, new services, and new products are being created constantly. How do you ensure your SDLC doesn't slow down when you have more and more teams and services? You want a mechanism that works, and preferably, a mechanism that works fast.
And this is where DevSecOps kicks in.
At first glance, it seems DevSecOps is created by "adding" security into DevOps.
Why on earth adding more doesn't slow things down?
I'm glad you asked. Let's take a deeper look into each stage of the SDLC, and see how the DevSecOps way handles it even faster than before.
2 - Planning / Analysis / Designing
We usually don't start coding right away when it comes to the SDLC, but we do some planning, and we do the architecture/system design.
This is when all the essential questions are answered, and most of the architectural decisions are made because these are the decisions that are not so easy to change in the future.
If you chose the wrong VM type, you could easily wipe it out and launch a new one; but if you created a not-so-ideal network topology, it's not so easy to fix without downtime.
What's more, every team faces these issues, which means a lot of duplicated work that slows things down.
Let's have a look at some of the architectural decisions.
2.1 - Access Control
We tend to deploy things in the cloud for faster invention. When you have just created a new cloud account (be it AWS or GCP), the first thing you usually do is create some users and roles instead of using the root account, which is highly risky.
Access control defines one thing: who can access what. It is already hard enough to manage by itself, even when you work in a single team with a monolith. It's even more so when you have multiple teams, each working on its service.
Things might become out of control if you manage teams and people manually. You might add one team today and add some roles tomorrow, and in the end, nobody knows who should have access to what.
In a DevOps or DevSecOps way, access could be automated by code.
While access isn't strictly "infrastructure" per se, some Infrastructure as Code tools can do this indeed (like Terraform). You can easily define different groups and roles, and permissions with code. With the help of various plugins, you can even use an IaC tool to manage your users on other platforms, like in GitHub.
When you have coded some common modules, they can be shared across different teams so that they don't have to reinvent the wheel. And when you have all the groups and roles and permissions defined as code, you are only one commit away from access control change.
Imagine if you have a new team member onboarding today, and you simply put his name into a team, and voila, he gets access to all he should. Imagine you need to onboard one guy not only to a specific AWS group but also a GitHub group. Instead of doing things manually at two different places, you can do it as code with minimum changes and apply.
The organization has become more complex than ever, and we have more role-based access controls to manage, but with the right tool, it can be achieved way faster than ever, and not to mention, it's less error-prone thanks to automation.
2.2 - Network Infrastructure
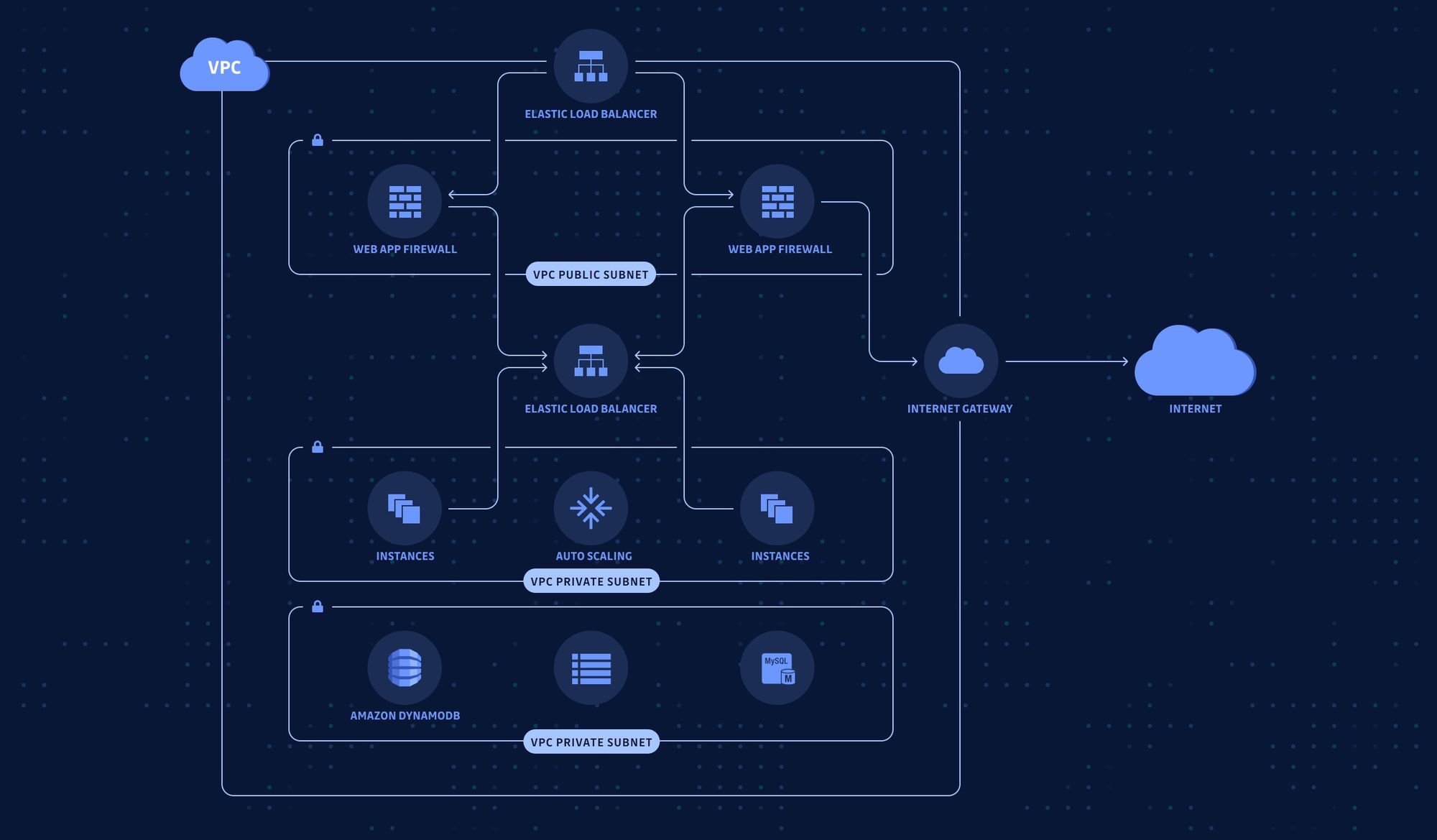
In the designing stage, you also need to decide what your infrastructure will look like. How many layers of networking do you need? Which layer can talk with which layer? Which port should be open and which one should not?
Besides, the computing resources also need to be worked out. On which port is each microservice listening? What permissions does each worker node require to make the whole system work? Should the SSH port be open or not?
Of course, everything like this can be managed using Infrastructure as Code; but it's not enough.
Code is written by humans, after all, and humans make mistakes. Using IaC can only help you go so far as to remove manual errors and inconsistencies; it can't question you whether you should do so or not when you leave the SSH port open to everyone.
Except it could.
Nowadays, there are already many services that help to ensure better security. For example, suppose you are using Terraform. In that case, there is tfsec and terrascan which scan your code statically, and based on predefined rules, they can generate alert and give you advice on improving your security. All this is done with minimal to no configuration.
If you are not a Terraform guy but a CloudFormation guy, there is also cfnlint which even allows you to define your own security rules.
In the space of AWS, there are many services dedicated to maximizing security: there is a well-architected framework which can generate a report and give advice based on your infrastructure; you have detection and remediation tools like AWS Config, GuardDuty, which can create warnings when specific policies are breached, and security might be compromised.
For example, with AWS Config, you can automatically delete security groups that are not used anymore, so you always keep your infrastructure clean and tidy. See more details here.
2.3 - Data Security
When you have your infrastructure ready, the next big thing to think about is your data. For example, you might want only to deploy database clusters in dedicated network subnets. You might only want your backend subnets, not the frontend subnets, to access the databases.
You want to enable data encryption to make sure data is securely stored at rest. You also want to enable transport layer security when you are talking with the databases to secure the traffic in transit. On the topic of data security, refer to this article for more details.
And sometimes it's not only questions about databases, but other types of storage as well, like: should each specific S3 bucket be open to the public or not? If it is accidentally made open, what should happen to remediate it?
Besides the aforementioned static code analyzing tools and ready-to-use services, you can even automate your own pipeline.
For example, how can a company enforce its policy regarding S3 bucket public exposure? In the good-old monolith days, when you had only one (or a few) buckets, it wasn’t so bad. You could use a homemade script leveraging the S3 API to scan all the buckets and generate a report if any had been made public by accident. You could even do this manually. Then you were able to check out the owner of those non-compliant buckets, send them the report, and ask them to update the access control of their buckets accordingly.
While this could work in a relatively small organization, it certainly won't when you have multiple agile teams, and each team has many buckets to manage. The old way doesn't scale, so you need to build something that can scale. For example, you could build a generic solution where the S3 event triggers a serverless function that checks the bucket's permission. If a policy is violated, fix it right away with code, then notify the owner automatically -- this is the DevSecOps way.
3 - Development
Moving on to the next stage: the coding part. There are three major concerns during the development process on the topic of security : we will finish this first part exploring code repository security.
3.1 - Code Repo Security
Is the access control of the repo correctly set so that everyone has exactly the right amount of permissions? (Consider the principle of least privilege here, except this isn't for machines where the code runs, but rather, for the team members). Is any repo made public by accident? Does the repo contain some sensitive data that shouldn't be stored in it?
These are the questions we want to address around code repo security. Things were relatively easy to manage in the old waterfall days with a monolith (hence most likely a mono-repo setup as well). You can manage people with a few clicks to grant the proper permission, you can see if the repo is public or private literally with merely a glance, and secret sprawling was much more limited.
Again, these methods don't scale in the modern multi-team, agile, microservice setup. Theoretically, the good old ways should still work, except you need to do these tasks, which are time-consuming and error-prone, repeatedly. As the number of teams and repos grow, if you stick to the old way, the SDLC will be significantly slowed down, and you will be buried under a pile of toils, feeling busy all day without any real accomplishment.
With DevSecOps best practice in mind, these things should all be handled in an automated fashion, like the git user management automation we mentioned in the previous section.
For another example, there are quite a few open-source and commercial products, which can do static code analyzing, based on predefined patterns, to detect if the codebase contains secrets or something to that effect. When these jobs are executed automatically by your CI pipelines and integrated with your alerting system, you can eliminate this risk from the very origin.
Yet another, with APIs and automation, you can quickly develop a piece of code that interacts with GitHub to fetch all the repos under an organization and check the public/private attribute, and report back to Slack (or any other tool of your choice). Check out this simple piece of code which does exactly this.
This is the end of this first part, but next we are going to have a look at container image security, managing secrets in Kubernetes, incident response playbooks, and more.
If you would like to receive the second part by email, just subscribe to the blog! And don’t forget to share!
Continue reading
How Adding Security into DevOps Accelerates the SDLC (Pt. 2)
Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.








