


Security is job zero. It’s even more important than any number one priority.
Data security means protecting the data, such as those on a disk or in a database, from destructive forces and the unwanted actions of unauthorized users, such as a cyberattack or a data breach. It’s the practice of protecting digital information throughout its entire lifecycle.
When we talk about unauthorized access, corruption, or theft, there are basically two major possible ways to get the data:
- The attackers get access to the storage system. For example, they hack into the server or even steal the physical disk.
- When you use your data, if the communication is captured, the data could also leak.
So, we need to make sure no matter if the disk is compromised or the data transmit traffic is compromised, the data itself isn’t compromised. This is where encryption kicks in.
Encryption at Rest

Encryption at rest means the data stored in the storage system is encrypted. Encryption at rest is designed to prevent the attacker from accessing the data by ensuring the data is encrypted when stored on the disk. If the data stored on the disks isn’t encrypted, when the storage system is compromised, the attacker can read it just as you can, simple as that.
If you are a Mac OS user, you might already be familiar with FileVault, which does encryption at rest.
Even if the attackers steal your laptop or break into the data center and steal the hard drives of your servers (or the servers of your public cloud providers, not quite likely but still possible), they would have to defeat the encryption without the encryption keys, which is so time-consuming that it almost borders on impossible.
Encryption in Transit

Encryption at rest isn’t enough, though, because data is meant to be used. What good is it if you only store the data safely on the disk and never use it?
Your app will need to read from and write to your database, and your apps need to send and receive data between them. During the data transit, if the data isn’t encrypted and the communication is compromised thus the data is intercepted, your data is leaked.
Encryption in transit makes sure the data is encrypted before the transmission; it also authenticates the endpoints. Upon data arrival, the data is decrypted.
The most famous example is probably HTTPS which you use every day: the data is encrypted before being sent and decrypted upon its arrival at the servers, and the identity of the server is also verified.
AWS KMS
For data at rest and data in transit, encryption makes it secure. And for encryption to work, we need an encryption key that is used by algorithms to do encryptions.
This is where the AWS KMS kicks in: it’s a centralized place for you to generate, store, manage and audit your encryption keys. And, since it’s an AWS service, it is very well integrated with many other AWS services.
KMS mainly handles encryption at rest, but depending on how you use it, it can also be used for encryption in transit.
KMS Use Cases
Enforcing Data at Rest Encryption AWS
If you are responsible for securing your data across AWS services, you probably need KMS. In this case, KMS is used to centrally manage all the encryption keys which control access to your data.
For example, if you need to make sure all the virtual machine storage volumes are encrypted at rest, or you want to create a snapshot of a volume and want to make sure the snapshot is encrypted, you can use KMS to do the encryption. By default, Amazon EBS uses KMS key for encryption. Alternatively, you can specify a symmetric customer-managed key that you created as the default KMS key for EBS encryption. Using your own KMS key gives you more flexibility, including the ability to create, rotate, and disable KMS keys.
Many other storage services within AWS are very well integrated with KMS., like EFS, S3, RDS, SageMaker, etc.
Encrypt Data in Apps
If you are a developer who needs to encrypt data in your applications, you might want to use the AWS Encryption SDK with AWS KMS to easily generate, use, and protect symmetric encryption keys in your code.
The security of your encrypted data depends in part on protecting the data key that can decrypt it. One accepted best practice for protecting the data key is to encrypt it:
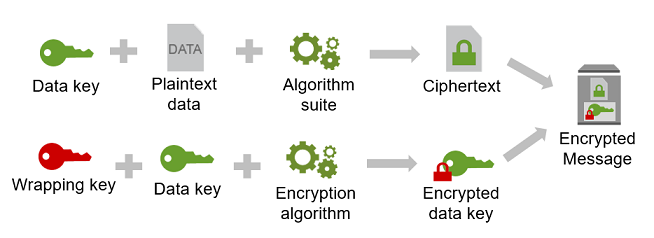
To do this, you need another encryption key, known as a key-encryption key or wrapping key. This practice of using a wrapping key to encrypt data keys is known as envelope encryption. With AWS Encryption SDK and with AWS KMS, you can achieve data encryption with envelope encryption in your app with only a few lines of code.
Encrypting PCI Data Using AWS KMS
Since security and quality controls in AWS KMS have been validated and certified to meet the requirements of PCI DSS Level 1 certification, if you are dealing with payment card information, you can directly encrypt Primary Account Number data with an AWS KMS customer master key to be compliant.
Using AWS KMS to encrypt data directly removes some of the burdens of managing encryption libraries.
Additionally, a customer master key in KMS can’t be exported, so it alleviates the concern about the encryption key being stored in an insecure manner. And, as all KMS requests are logged in CloudTrail, the use of the CMK can be audited by reviewing the CloudTrail logs.
Other KMS Benefits
There are a few other use cases or benefits you might already be using without knowing it.
- By default, when you create or update Lambda functions that use environment variables, those variables are encrypted using AWS KMS. When your Lambda function is invoked, those values are decrypted and made available to the Lambda code.
- If you are a developer who needs to sign or verify some data using asymmetric keys digitally, you can use the service to create and manage the private keys you’ll need.
- If you’re responsible for proving data security for regulatory or compliance purposes, you should use it because it facilitates proving your data is consistently protected. It’s also in scope for a broad set of industry and regional compliance regimes. Besides the aforementioned PCI DSS level 1, it’s validated with HIPAA (healthcare, health insurance) and FIPS 140–2 (government departments, federal agencies, contractors, or service providers to the federal agencies).
Using the Data — Authentication and Authorization
Encryption at rest makes sure the data is soundly and safely stored, and encryption in transit makes sure the data won’t leak even if the traffic is captured. It seems we are fully protected, right? Well, there is still a catch — you only want certain authorized users to access certain data instead of anyone-can-access-anything. To access the data, you probably need a password to authenticate your identity.
A real-life example
Once, I was in a project where we needed to migrate from some older version of OpenShift clusters in one AWS account to some other latest Kubernetes clusters in some other AWS accounts. The difference between OpenShift and Kubernetes isn’t such a big deal, so the application part migration went well, but the biggest challenge was the secrets.
In the old days, when the project just started in the old OpenShift clusters, every secret was managed manually, and the OpenShift secret is used as the single source of truth with RBAC policies in place, ensuring each team had the right access.
While this approach sounds not so bad, managing those secrets was such a painful experience: every time when a new secret was needed, we needed to create it in multiple environments, manually, copy-paste from Slack - Secret Sprawl alert!! It was as if we were leaving our credit card code in plain sight! -, base64 encode, create YAML files, apply, then delete those YAML.
We decided to change this manual operational overhead in the new Kubernetes clusters, but we needed to make sure during the migration where both the old and the new clusters were running, the secrets should be synchronized from a single source of truth.
Apparently, AWS KMS wouldn’t work here; what we need is a way to centrally store secrets and fetch them easily, which are in turn used for authentication.
This project brings us to the topic of authentication (Authn) and authorization(Authz). First, you need to authenticate a user: if this user is a trusted party, like an employee, or an internal application, or an external integrated application; then you need to authorize this user: based on this user’s team, app, role, etc., decide what data they should be able to access and whatnot, and what operations they could execute on those data.
HashiCorp Vault
Vault secures, stores, and tightly controls access to tokens, passwords, certificates, encryption keys, etc., for protecting secrets and other sensitive data. Vault is designed to do secrets storage, authentication, and authorization, but it’s more than that.
Vault Architecture
To understand Vault, maybe we can talk about HashiCorp’s other product first: Terraform. If you are a HashiCorp user, you may have already used Terraform, the Infrastructure as Code tool that automates your cloud infrastructure.
Terraform is logically split into two main parts: Terraform Core and Terraform Plugins.
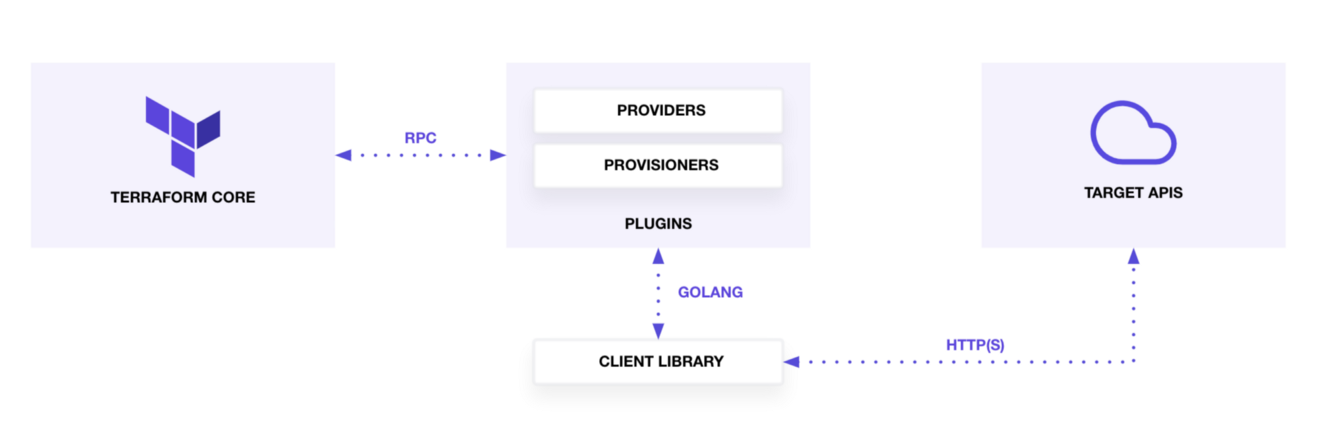
The core basically doesn’t do much. Terraform Core provides a high-level framework that manages the state, constructs the resource graph, and executes the plan. If the plan is to create some resources in some public cloud, the core can’t do it. The core relies on RPC communication to the plugins, or the providers, which in turn does the CRUD. The plugin implements the operations carried out in a specific domain, such as AWS.
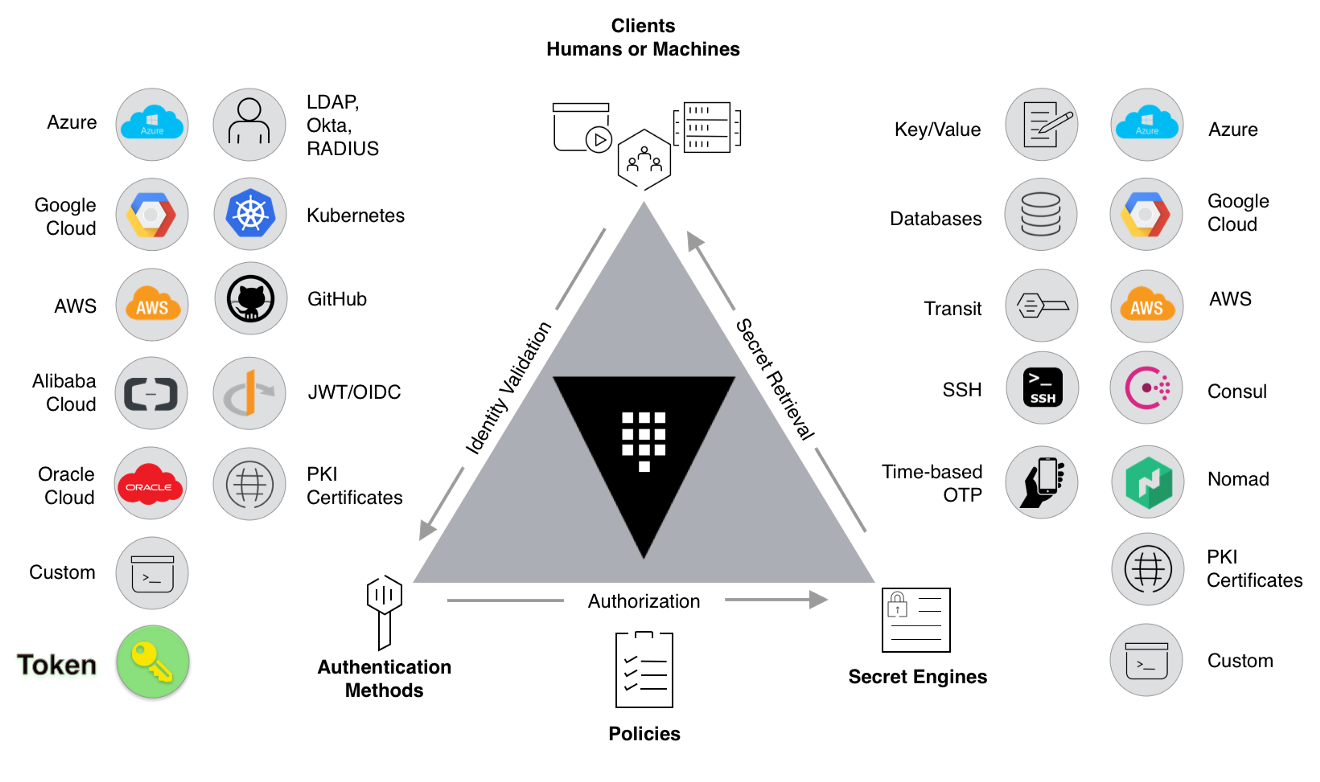
HashiCorp Vault used a similar design, where the vault core itself only does the identity validation and authorization, but to actually get the secret, or to decide what exactly access you get, it’s all on the secret engines.
Secret Engines
Secrets engines are components that store, generate, or encrypt data.
Secrets engines are incredibly flexible; what Vault can do depends on what engines you have. So it is easiest to think about them in terms of their function. Secrets engines are provided some set of data, they take some action on that data, and they return a result.
Vault Use Cases
Secrets Manager
Some secrets engines (for example, Vault KV engine) simply store and read data — like encrypted Redis/Memcached, where you read and write key-value pairs.
Most likely, we may already know Vault as a secrets manager. With this type of engine, Vault can centrally store secrets for your applications, systems, and infrastructure; vault makes it easy to access these secrets across different places, and vault audits the access — it is like a secrets manager.
Identity-Based Access
Some secrets engines connect to other services and generate dynamic credentials on-demand, so vault can authenticate and access different clouds, systems, and endpoints using trusted identities.
For example, the AWS secrets engine generates AWS access credentials dynamically based on IAM policies stored in Vault. This generally makes working with AWS IAM easier since it does not involve clicking in the web UI. Additionally, the process is codified and mapped to internal auth methods (such as LDAP). The AWS IAM credentials are time-based and are automatically revoked when the Vault lease expires, eliminating manual work.
For another example, the MySQL engine is one of the supported database secrets engines. This engine generates database credentials dynamically based on configured roles for the MySQL database, and just like the AWS secrets engine, you get a time-based credential for a period of access, and it will be revoked when the lease expires.
Encryption as a Service
There are some other secret engines that provide encryption as a service, TOTP generation, certificates, and much more.
Taking Encryption as a Service as an example, Vault’s transit secrets engine handles cryptographic functions on data-in-transit. Vault doesn't store the data sent to the secrets engine, so it can also be viewed as encryption as a service, just like AWS KMS. This relieves the burden of proper encryption/decryption from application developers and pushes the burden onto the admins of Vault.
With the Vault transit engine, you can keep secrets and application data secure with one centralized workflow to encrypt data both at rest and in transit.
The final set-up
Since what Vault can do totally depends on the secret engine, the use cases are only limited by your imagination (and by the secret engines, of course.)
In the previously mentioned project, we went to Vault KV engine for help to use it as a secrets manager and as the single source of truth:
- Vault integrated with our internal GitHub Enterprise for single sign-on
- GitHub team-based identity access policy created in Vault, just like before
- Secrets from the old clusters created in Vault with an automation script using Vault API as a one-time migration
- Secrets management in OpenShift disabled, using Vault as a single source of truth and managing secrets there
- A small app developed with Vault API and K8s API to periodically synchronize secrets from Vault into Kubernetes as native K8s secrets
Problem solved.
Summary
While Vault and KMS share some similarities, for example, they both support encryption, but in general, KMS is more on the app data encryption / infra encryption side, and Vault is more on the secrets management / identity-based access side.
Having data encryption, secrets management, and identity-based access enhances your security, but that’s not all of it. Even if you have chosen to do encryption and to use a secrets manager and you have all the right tools in place to help, it doesn’t really mean it’s 100% secure.
Good Intention
How often do we read in the news that there is a misconfigured database with public access, so customer data is leaked? How often do we see a story that some Git repository contains passwords to access databases?
While this can be mitigated by knowledge sharing and internal training, it doesn’t always work, unfortunately.
Most people already have good intentions; they know they should not do things like this, but things like this still happen because good intentions don’t work; humans make mistakes.
I’m willing to admit that I have also accidentally submitted information which I shouldn’t have into Git before. Then I had to rewrite the history of the repo. Lucky for me, it was a personal project. If it was a huge repo shared by multiple teams, I can’t imagine what the consequences are.
Automated Mechanism
If good intentions don’t work, what will work? Mechanism. Automated Mechanism.
For example, you can rotate the password to your database automatically and periodically, making sure accessing those passwords isn’t an overhead for the applications that need access to it. This can be achieved by automation.
For another example, you can build an automated pipeline that scans Git repos for possible secrets leak, generate reports, and create alerts.
Adopting KMS or Vault is a good step forward, and the next step would be the automated DevSecOps way of doing security.
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.







