Why we loved PostgreSQL triggers, and why we are removing them
A bad reputation
One of the most common patterns of software design is to separate the data from the code. On one side, we have persistence, querying, and mutations with ACID transactions (at least on most common relational databases), and on the other side we have well, all the rest, from business logic to presentation layers. So executing code inside databases seems at first a little awkward. But there are use cases for that, especially when it’s interesting to transform data without leaving the database instance, eg. for performances or consistency.
That’s why databases offer many functions to transform the data being queried from casts to aggregations, so we can craft powerful queries with fewer data to retrieve. Databases also allow us to code complex functions to store data in a more efficient way. PostgreSQL allows for the creation of procedural functions in at least 4 languages (SQL, Python, TCL, and Perl). Like many other engines, it proposes a mechanism to automatically execute those functions when data is created, updated, or deleted. These are the triggers.
Triggers have a bad reputation though. Lots of developers don’t want to use them at all. Most common complaints:
- They are mostly written in SQL, which can quickly get cumbersome and difficult to read. Plus not all developers know SQL.
- They are easily forgotten because they are stored in the database. They are hard to fit into your development or deployment process and it’s also difficult to be sure that the database runs the correct version of your trigger.
- They are difficult to debug. Triggers are executed in the database, and therefore not easily observable. Your code can create a record and then a trigger will fire without your knowledge. You can log your code but it’s more challenging to log triggers and get a unified view.
But at GitGuardian we like to keep an open mind. Despite all their faults, triggers could surely help us somehow.
How triggers helped us
When we started GitGuardian Internal Monitoring, we faced performance issues on complex queries involving aggregations filtered on business rules. We rapidly came to the idea of computing those values in the database, but with no compromise on consistency. We concluded triggers could be a good and cheap solution to compute those aggregates.
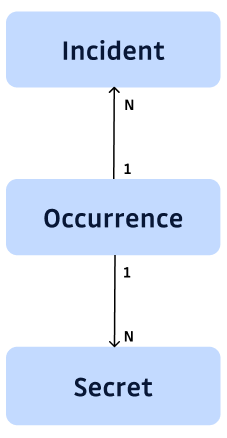
Let’s consider this simplified model. GitGuardian Internal Monitoring detects secrets in private Git repositories. Each Secret can be found in many files, many commits, each of them being an Occurrence. The Incident was created to facilitate the remediation management by users. It aggregates Occurrences and offers additional information for remediation:
- a count of occurrences,
- a severity that is linked to the kind of files where the Secret is found and if it is valid or not (among other signals),
- a remediation status linked to a complex workflow eg. if a new Occurrence of an Incident considered as resolved is found, the incident must be reopened.
All those incidents’ properties and many more are displayed on the GitGuardian Internal Monitoring dashboard: involved repositories and developers, if the Secret was found in test files or not, detected during a historical scan, etc…
Since they are all expensive aggregations, we were facing a bottleneck when trying to compute them on the fly.
Hence our idea of using triggers to precompute aggregates.
Let’s say we want to precompute the count of occurrences of an Incident. We add an “occurrences_count” field in the “incident” table, and each time an occurrence is inserted, a trigger will increment incident.occurrences_count.
Using PL/pgSQL, the code would look like this:
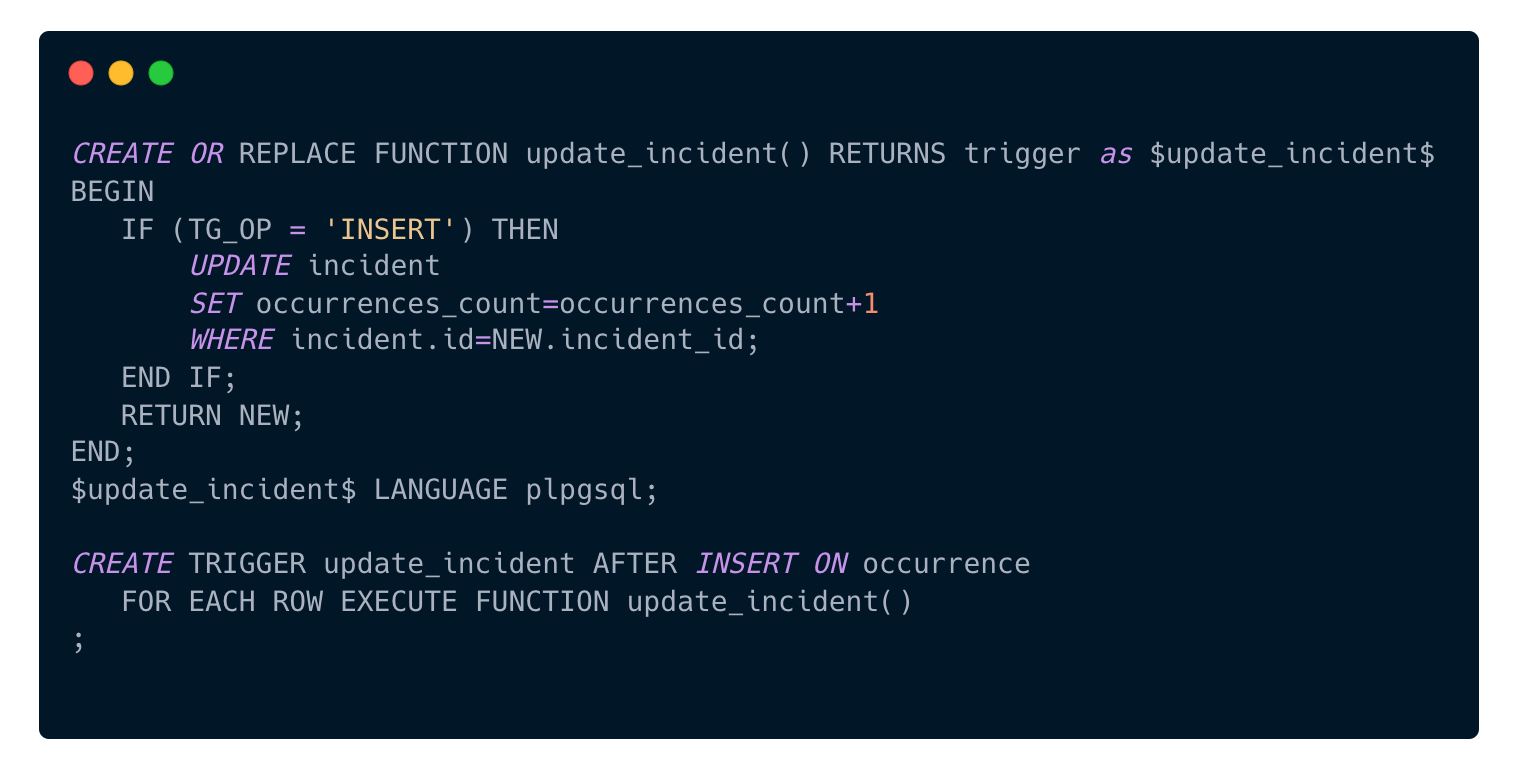
First, we create a function where values of the newly inserted row are available in the NEW variable, and where the TG_OP variable tells us from which operation it is called on. This function is then set to be triggered for each row inserted in the occurrence table.
Now, let’s see how we overcame the flaws often mentioned about triggers: poorly integrated into the development flow, difficult to write and maintain, difficult to debug and observe.
How can we be sure triggers are up to date in the database?
In Django, there is no built-in way to manage triggers, like you can find in Rails with Gems like hair_trigger. But Django has a powerful migration system that makes it easy to create or update our triggers in the database.
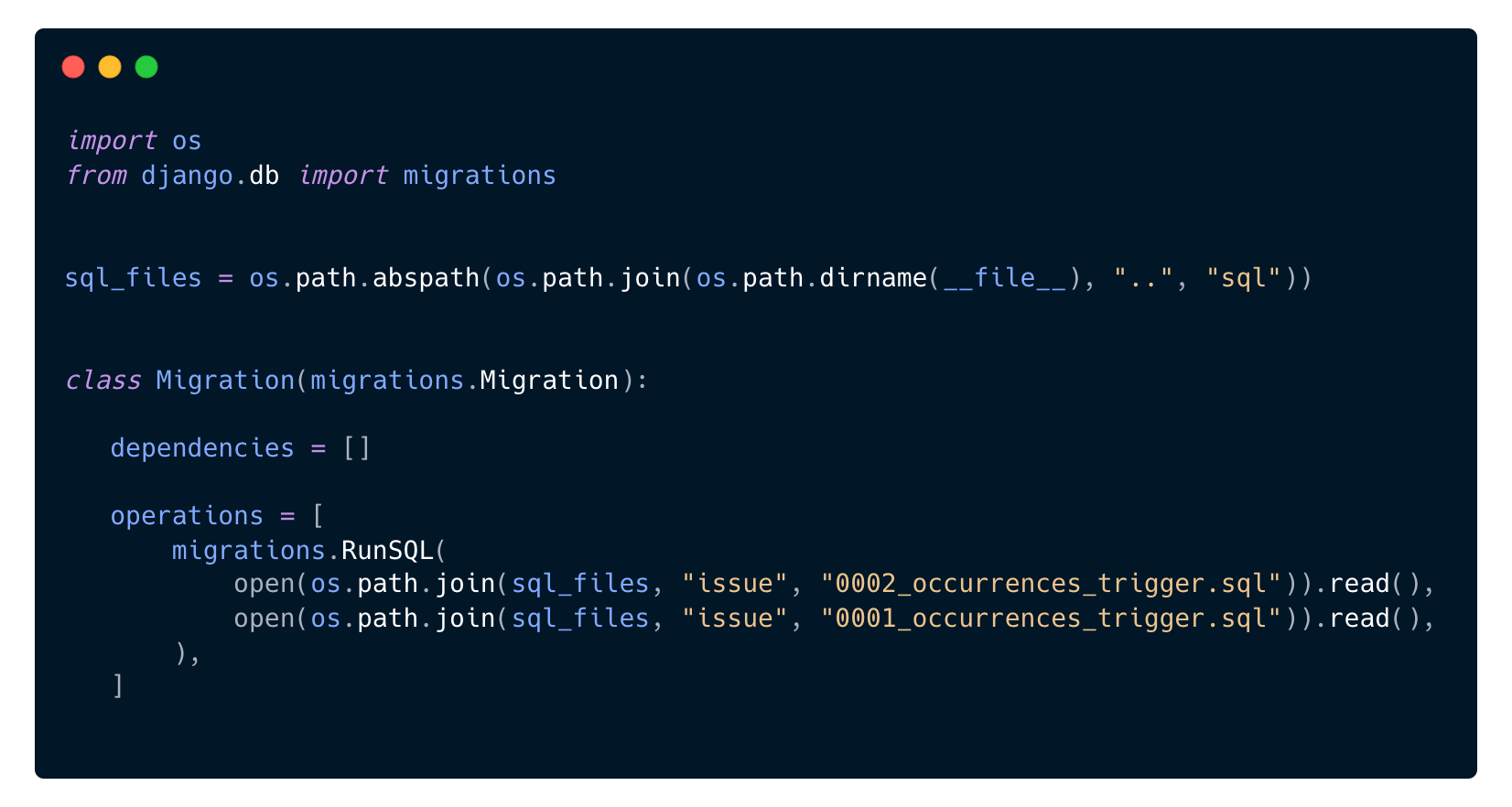
In this code, we put our PL/pgSQL code in plain SQL files in a sql directory. SQL files are neat because we can lint them to make them (a little bit) more readable. To facilitate the creation of new trigger files and their insertion into Django migrations, we created the “maketrigger” Django command that provides a template for SQL trigger code. We also use versions to manage incremental and reversible migrations (0001_occurrences_trigger.sql is the first version of the trigger, 0002_occurrences_trigger.sql is the second version). We just call Django’s RunSQL to apply the SQL code that will drop any existing trigger and create a fresh new one, making the migration idempotent.
How do we get observability on triggers?
We do not. But by keeping our triggers very simple, we limited the need for observability. Each trigger carried only very simple business logic and did only a few queries.
And triggers delivered. As soon as we released them in production, read performances increased as expected. Write performance wasn’t critical since most INSERTs and UPDATEs are made by asynchronous backend tasks, plus we didn’t see any issue in months. In other words, we loved triggers.
But after about a year, we started to get some unexpected behavior in our database.
Why we are removing triggers
It first started with very long queries. Those queries were happening once in a while with no predictable pattern. Using our APM and Postgres monitoring tools we quickly identified locks as the cause of those issues. But those tools were helpless to identify the root cause of locks. You probably guessed triggers were to blame. The problem is that they leave very few traces that can lead back to them. Only each individual SQL query performed by triggers is logged in Postgres pg_stat_activity table, so it’s very difficult to “see” a trigger operating. But we eventually came to the conclusion that triggers were an important cause amongst others.
What is wrong with (our) triggers
Our triggers are cascading. A trigger on a table will act on another table where triggers will also happen. That’s not a problem per se, but if the cascading chain involves many tables, that’s more queries to execute each time you act on the first table. That’s a hidden complexity and a potential hidden performance issue.
We also do bulk inserts to boost performances. When scanning code for secrets, we don’t do an insert for each occurrence we find. We create row batches that we insert in a single operation. But as you can see in my previous example, PostgreSQL triggers operate at the row level (the “FOR EACH ROW” in the trigger definition), meaning that if you insert 10,000 rows, they will fire 10,000 times.
PostgreSQL also supports statement-level triggers. They will fire only once no matter the number of rows affected. But with cascading triggers, it will not help much. The first trigger only fires once, but it will fire the cascading trigger chain every time it iterates on a row.
In most of our use cases, although our triggers are all simple and fast, they can create a huge chaotic load on the DB in circumstances we can’t foresee.
Life after triggers
If we did choose triggers in the first place it is because they offer performance and consistency. So, wanting to ditch them raised a question: how much are we willing to lose on those two aspects?
On the performance side, we still want to keep fast reads no matter how the data grows, but we can afford lower write performances because most of those writes are performed in the background. We also want to keep as much consistency as possible, but we can accept a small delay (no more than a few seconds) to update computed fields.
We considered many solutions. When it comes to transforming the data for read performance, some architecture patterns like CQRS come to mind (use separate data models for creation and consumption and link through transformation pipelines). But we figured out those were overkill for our use case… for now.
Computing the fields in an asynchronous task (we use Celery to that extent) seemed a simpler, leaner approach. We chose this solution also because it’s already a part of our Django project, meaning that we can use all of our high-level concepts and tightly control how we optimize the code. We can do only the needed queries, and pack them in bulk operations as we wish. In the end, running the Python code may be slower than doing the whole process inside the database, but the overhead will not be significant enough to affect useability and we will get more stability and scalability.
Final thought
So are triggers good or bad? Although we experienced how harmful they can be, we still think they can be useful. As they enforce consistency in the database, they allow for a team working on a monolith to scale.
Still, they must be kept as simple as possible and their development lifecycle must take place in standard development processes: reviewed, tested, and released as other pieces of code. At GitGuardian, we finally kept some of them. There is still some love after all.