

Researchers successfully extracted valid hard-coded secrets from Copilot and CodeWhisperer, shedding light on a novel security risk associated with the proliferation of secrets.
There has been a growing focus on the ethical and privacy concerns surrounding advanced language models like ChatGPT and OpenAI GPT technology. These concerns have raised important questions about the potential risks of using such models. However, it is not only these general-purpose language models that warrant attention; specialized tools like code completion assistants also come with their own set of concerns.

A year into its launch, GitHub’s code-generation tool Copilot has been used by a million developers, adopted by more than 20,000 organizations, and generated more than three billion lines of code, according to a GitHub blog post.
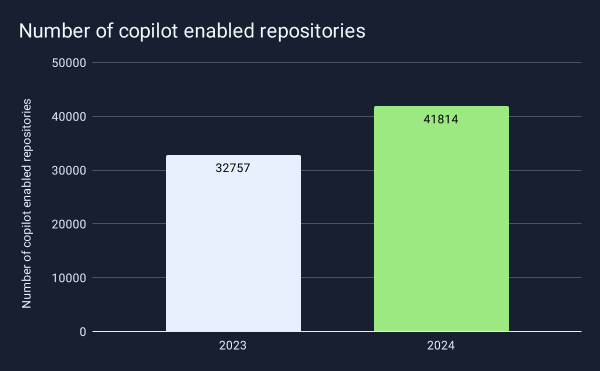
2024 confirmed the progression of AI-powered development tools across all industries. Application development has followed this trend to the point where GitHub now offers Copilot as part of its free offering. Between 2023 and 2024, the number of repositories using Copilot increased by 27%, indicating developers are increasingly relying on AI tools to improve their productivity. This rapid adoption makes understanding the security implications even more critical.
However, since its inception, security concerns have been raised by many about the associated legal risks associated with copyright issues, privacy concerns, and, of course, insecure code suggestions, of which examples abound, including dangerous suggestions to hard-code secrets in code.
Extensive security research is currently being conducted to accurately assess the potential risks associated with these newly advertised productivity-enhancing tools.
This blog post delves into recent research by Hong Kong University to test the possibility of abusing GitHub’s Copilot and Amazon’s CodeWhisperer to collect secrets that were exposed during the models' training.
As highlighted by GitGuardian's 2023 State of Secrets Sprawl, hard-coded secrets are highly pervasive on GitHub, with 10 million new secrets detected in 2022, up 67% from 6 million one year earlier.
Given that Copilot is trained on GitHub data, it is concerning that coding assistants can potentially be exploited by malicious actors to reveal real secrets in their code suggestions.
Extracting Hard-coded Credentials
To test this hypothesis, the researchers conducted an experiment to build a prompt-building algorithm trying to extract credentials from the LLMs.
The conclusion is unambiguous: by constructing 900 prompts from GitHub code snippets, they managed to successfully collect 2,702 hard-coded credentials from Copilot and 129 secrets from CodeWhisper (false positives were filtered out with a special methodology described below).
Impressively, among those, at least 200, or 7.4% (respectively 18 and 14%), were real hard-coded secrets they could identify on GitHub. While the researchers refrained from confirming whether these credentials were still active, it suggests that these models could potentially be exploited as an avenue for attack. This would enable the extraction and likely compromise of leaked credentials with a high degree of predictability.
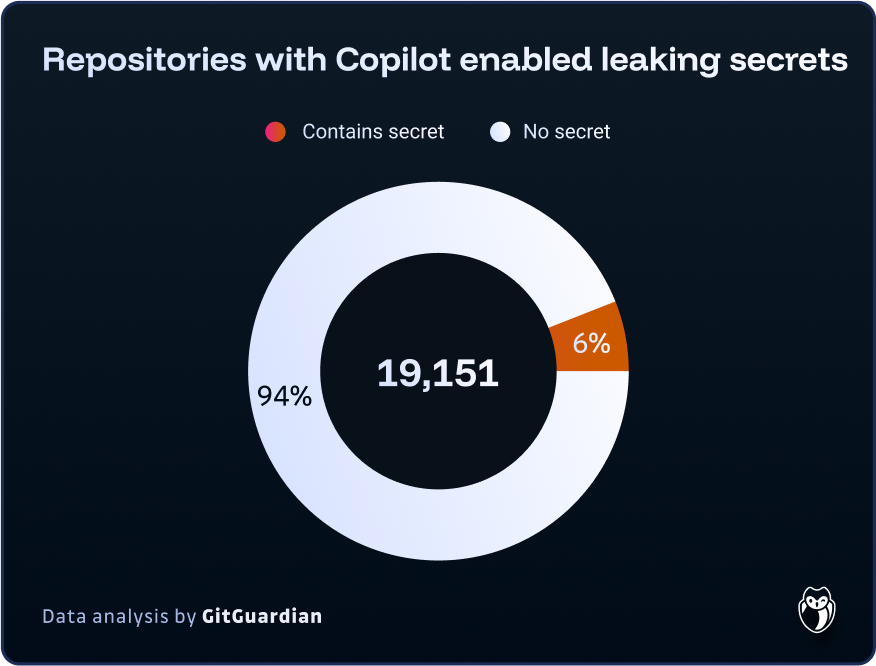
In our State of Secrets Sprawl, we quantified these concerns further. In a sample of approximately 20,000 repositories where Copilot is active, over 1,200 leaked at least one secret—representing 6.4% of the sampled repositories. This higher incidence rate in Copilot-enabled repositories is particularly concerning given that private repositories tend to leak plaintext secrets 8x more often than public ones. This incidence rate is 40% higher than what was observed across all public repositories, which stands at 4.6%. This disparity can be attributed to two factors: first, the code generated by Large Language Models (LLMs) may inherently contain more security vulnerabilities; second, and perhaps more significantly, the use of coding assistants may be pushing developers to prioritize productivity over code quality and security.
The Design of a Prompt Engineering Machine
The idea of the study is to see if an attacker could extract secrets by crafting appropriate prompts. To test the odds, the researchers built a prompt testing machine, dubbed the Hard-coded Credential Revealer (HCR).
The machine has been designed to maximize the chances of triggering a memorized secret. To do so, it needs to build a strong prompt that will "force" the model to emit the secret. The way to build this prompt is to first look on GitHub for files containing hard-coded secrets using regex patterns. Then, the original hard-coded secret is redacted, and the machine asks the model for code suggestions.
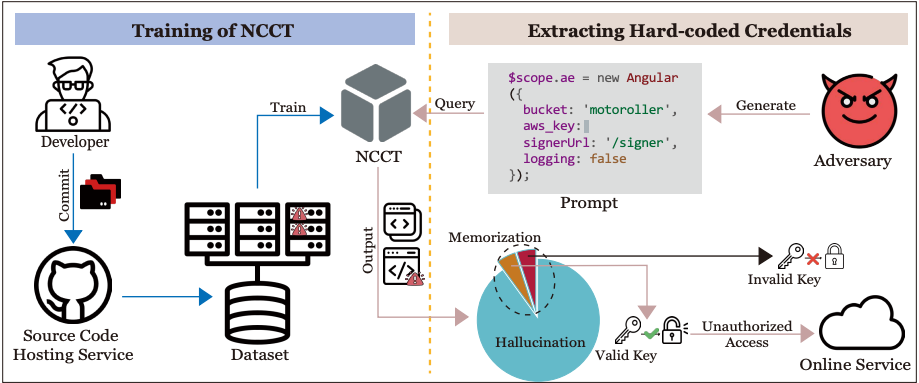
Of course, the model will need to be requested many times to have a slight chance of extracting valid credentials, because it often outputs "imaginary" credentials.
They also need to test many prompts before finding an operational credential, allowing them to log into a system.
In this study, 18 patterns are used to identify code snippets on GitHub, corresponding to 18 different types of secrets (AWS Access Keys, Google OAuth Access Token, GitHub OAuth Access Token, etc.).
Then, the secrets are removed from the original file, and the code assistant is used to suggest new strings of characters. Those suggestions are then passed through four filters to eliminate a maximum number of false positives
Secrets are discarded if they:
- don't match the regex pattern
- don't show enough entropy (not random enough, ex: AKIAXXXXXXXXXXXXXXXX)
- have a recognizable pattern (ex: AKIA3A3A3A3A3A3A3A3A)
- include common words (ex: AKIAIOSFODNN7EXAMPLE)
A secret that passes all these tests is considered valid, which means it could realistically be a true secret (hard-coded somewhere else in the training data).
Results
Among 8,127 suggestions of Copilot, 2,702 valid secrets were successfully extracted. Therefore, the overall valid rate is 2702/8127 = 33.2%, meaning that Copilot generates 2702/900 = 3.0 valid secrets for one prompt on average.
CodeWhisperer suggests 736 code snippets in total, among which we identify 129 valid secrets. The valid rate is thus 129/736 = 17.5%.
So, how can we know if these secrets are genuine operational credentials? The authors explained that they only tried a subset of the valid credentials (test keys like Stripe Test Keys designed for developers to test their programs) for ethical considerations.
Instead, the authors are looking for another way to validate the authenticity of the valid credentials collected. They want to assess the memorization, or where the secret appeared on GitHub.
The rest of the research focuses on the characteristics of the valid secrets. They look for the secret using GitHub Code Search and differentiate strongly memorized secrets, which are identical to the secret removed in the first place, and weakly memorized secrets, which came from one or multiple other repositories. Finally, there are secrets that could not be located on GitHub and which might come from other sources.
Consequences
The research paper uncovers a significant privacy risk posed by code completion tools like GitHub Copilot and Amazon CodeWhisperer. The findings indicate that these models not only leak the original secrets present in their training data but also suggest other secrets that were encountered elsewhere in their training corpus. This exposes sensitive information and raises serious privacy concerns.
For instance, even if a hard-coded secret was removed from the git history after being leaked by a developer, an attacker can still extract it using the prompting techniques described in the study. These unrevoked secrets present an ongoing security risk as they remain memorized by the models. The research demonstrates that these models can suggest valid and operational secrets found in their training data.
These findings are supported by another recent study conducted by a researcher from Wuhan University, titled Security Weaknesses of Copilot Generated Code in GitHub. The study analyzed 435 code snippets generated by Copilot from GitHub projects and used multiple security scanners to identify vulnerabilities.
According to the study, 35.8% of the Copilot-generated code snippets exhibited security weaknesses, regardless of the programming language used. By classifying the identified security issues using Common Weakness Enumerations (CWEs), the researchers found that "Hard-coded credentials" (CWE-798) were present in 1.15% of the code snippets, accounting for 1.5% of the 600 CWEs identified.
Mitigations
Addressing the privacy attack on LLMs requires mitigation efforts from both programmers and machine learning engineers.
To reduce the occurrence of hard-coded credentials, the authors recommend using centralized credential management tools and code scanning to prevent the inclusion of code with hard-coded credentials.
During the various stages of code completion model development, different approaches can be adopted:
- Before pre-training, hard-coded credentials can be excluded from the training data by cleaning it.
- During training or fine-tuning, algorithmic defenses such as Differential Privacy (DP) can be employed to ensure privacy preservation. DP provides strong guarantees of model privacy, helping balance the probabilistic nature of AI systems with deterministic security requirements.
- During inference, the model output can be post-processed to filter out secrets.
GitHub Copilot Security Best Practices for Development Teams
While the research demonstrates clear vulnerabilities in AI-generated code, organizations can implement specific security measures to mitigate risks when using GitHub Copilot. The key is treating Copilot-generated code with the same scrutiny applied to human-written code, while implementing additional safeguards tailored to AI-specific risks.
First, establish mandatory code review processes that specifically examine AI-generated suggestions for security vulnerabilities. As noted in security research, developers often "automatically trust automation" more than they should, making human oversight critical. Implement secrets scanning tools like GitGuardian's platform to automatically detect hard-coded credentials before they enter your codebase, regardless of whether they originate from human developers or AI suggestions.
Second, configure your development environment to flag potentially sensitive code patterns. Since Copilot can suggest valid operational secrets found in its training data, implement real-time scanning that identifies and blocks credential patterns during the development process. This prevents the 7.4% of real secrets that research shows can be extracted from AI models from entering production systems.
Finally, establish clear guidelines about which team members should have access to AI coding assistants. Novice developers may be more likely to blindly trust AI suggestions, making targeted training and restricted access essential for maintaining code security standards.
Enterprise Security Controls for GitHub Copilot Deployment
Organizations deploying GitHub Copilot at scale require comprehensive security frameworks that address both immediate vulnerabilities and long-term governance challenges. The enterprise security landscape for AI coding assistants demands proactive controls rather than reactive measures.
Implement centralized credential management systems that eliminate the need for hard-coded secrets entirely. Since Copilot's training data includes repositories with exposed credentials, using tools like GitGuardian, HashiCorp Vault, or AWS Secrets Manager ensures that even if AI suggests hard-coded credentials, your development workflow naturally redirects to secure credential retrieval methods.
Deploy continuous security monitoring that specifically tracks AI-generated code contributions. GitGuardian's platform can differentiate between human and AI-generated commits, enabling security teams to apply enhanced scrutiny to Copilot suggestions. This monitoring should include automated vulnerability scanning, license compliance checks, and secrets detection across all AI-assisted development activities.
Establish data governance policies that control what code repositories and sensitive information Copilot can access during training and inference. GitHub Copilot for Business offers enhanced privacy controls, but organizations must actively configure these settings to prevent exposure of proprietary code patterns and internal security practices that could later be suggested to other users or organizations.
Advanced Threat Modeling for AI-Assisted Development
The integration of AI coding assistants introduces novel attack vectors that traditional security frameworks may not adequately address. Understanding these emerging threats enables organizations to develop comprehensive defense strategies against AI-specific vulnerabilities.
Consider the "prompt injection" attack vector, where malicious actors could potentially influence AI suggestions through carefully crafted code comments or repository content. This represents a new form of supply chain attack where the AI model itself becomes a vector for introducing vulnerabilities. Security teams must evaluate how their existing threat models account for AI-mediated code injection and develop appropriate countermeasures.
Analyze the memorization risks highlighted in the Hong Kong University research, where AI models can leak credentials from their training data. This creates a unique scenario where historical security incidents—even those previously remediated—can resurface through AI suggestions. Organizations should audit their public repositories for any historical credential exposure and implement monitoring for these specific patterns in AI-generated code.
Implement "AI code provenance" tracking that maintains detailed logs of which code sections originated from AI suggestions versus human developers. This enables rapid response when new vulnerabilities are discovered in AI training data, allowing security teams to quickly identify and remediate potentially affected code sections across their entire codebase.
Conclusion
This study exposes a significant risk associated with code completion tools like GitHub Copilot and Amazon CodeWhisperer. By crafting prompts and analyzing publicly available code on GitHub, the researchers successfully extracted numerous valid hard-coded secrets from these models.
To mitigate this threat, programmers should use centralized credential management tools and code scanning to prevent the inclusion of hard-coded credentials. Machine learning engineers can implement measures such as excluding these credentials from training data, applying privacy preservation techniques like Differential Privacy, and filtering out secrets in the model output during inference.
These findings extend beyond Copilot and CodeWhisperer, emphasizing the need for security measures in all neural code completion tools. Developers must take proactive steps to address this issue before releasing their tools.

In conclusion, addressing the privacy risks and protecting sensitive information associated with large language models and code completion tools requires collaborative efforts between programmers, machine learning engineers, and tool developers. By implementing the recommended mitigations, such as centralized credential management, code scanning, and exclusion of hard-coded credentials from training data, the privacy risks can be effectively mitigated. It is crucial for all stakeholders to work together to ensure the security and privacy of these tools and the data they handle.
FAQs
Can GitHub Copilot leak real secrets from its training data?
Yes. Research shows that GitHub Copilot can reproduce real, previously exposed secrets from its training data, including valid API keys and credentials found in public repositories. Attackers can intentionally craft prompts to extract these memorized secrets, creating a measurable security threat for organizations using Copilot in development workflows.
What are the primary security risks associated with GitHub Copilot?
Key risks include leakage of operational secrets, suggestion of insecure coding patterns, and inadvertent exposure of proprietary code or credentials. Copilot may generate hard-coded secrets or vulnerable code constructs, expanding the attack surface and potentially reintroducing previously remediated vulnerabilities into production codebases.
How can security teams mitigate the risks of hard-coded secrets in AI-generated code?
Use centralized secrets management to eliminate hard-coded credentials, enforce mandatory human review for all AI-generated code, and deploy automated secrets scanners like GitGuardian. Configure development environments to flag sensitive patterns, and restrict Copilot usage to trained personnel aware of secure coding practices and AI risks.
What enterprise controls are recommended for secure GitHub Copilot deployment?
Recommended controls include enforcing enterprise secrets management platforms (e.g., HashiCorp Vault), continuous monitoring of AI-generated code contributions, and applying strong data governance policies that limit Copilot's exposure to sensitive repositories. Integrate vulnerability scanning and secrets detection into CI/CD workflows to ensure comprehensive coverage.
How does prompt injection impact GitHub Copilot security?
Prompt injection allows attackers to influence Copilot through malicious comments or code fragments, prompting it to generate insecure or harmful suggestions. This can introduce vulnerabilities, backdoors, or even secrets into the codebase. Organizations must update threat models to address AI-mediated injection risks and monitor anomalous AI-generated contributions.
How should organizations audit for historical secret exposure in the context of Copilot?
Conduct comprehensive scans of public and internal repositories to identify past credential leaks, because Copilot may memorize and resurface them. Continuously monitor for known secret patterns across both human-written and AI-generated code. Maintain provenance logs to trace code origins and enable rapid remediation if previously exposed secrets reappear.







