

One of the largest takeaways from the latest GitGuardian State of Secrets Sprawl Report is that in 2025, the way we all build software changed.
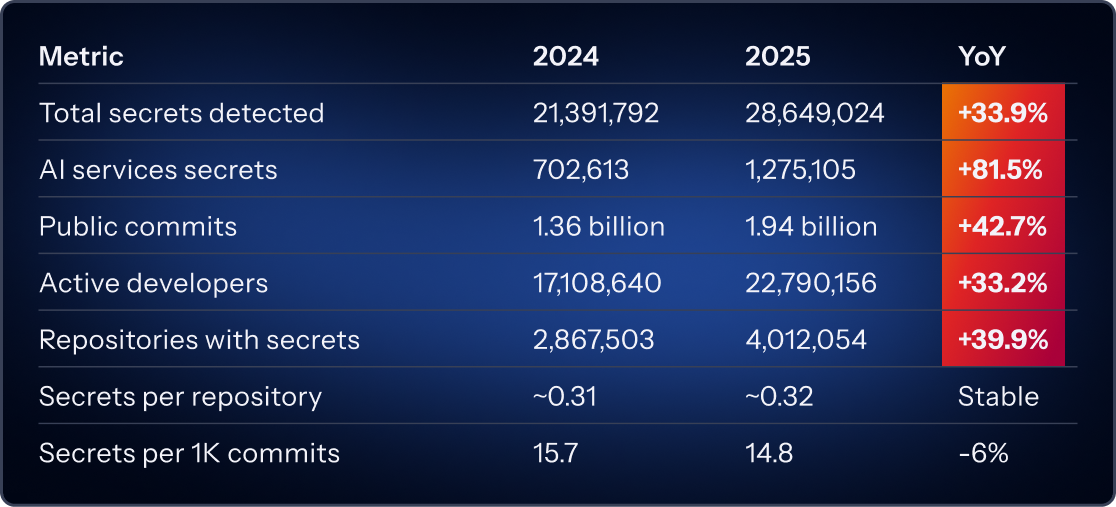
First, there are more developers than ever before. Publicly active developers on GitHub grew 33% in 2025, and 54% of active developers, meaning someone who has pushed code to GitHub, made their first commit that year. That means a lot of new code, a lot of new projects, and a lot of new integrations arriving all at once. More builders usually means more issues in code and consequently more credentials being leaked. This most certainly was a factor contributing to the 28,649,024 new secrets GitGuardian found in public GitHub commits across 2025. This is a 34% year-over-year increase and the largest annual jump in the report’s history. But it is more than just new devs and new agents. Since 2021, leaked secrets have grown 152%, while the public developer population grew 98%. Secrets are leaking faster than the developer base is growing.
But this year, there is another force in the system. AI has become part of the default software stack for almost all developers.
That shift shows up clearly in the credential data. The report found 1,275,105 AI-service secrets exposed in 2025, with 81% year over year growth in AI-related service secrets. It also found that 12 of the top 15 fastest-growing leaked secret types were AI services. That is a strong signal that AI tooling is no longer a sidecar to the stack. It is the stack, or at least a growing layer of it.
AI does not have to invent a new category of security mistakes to change the risk picture. It only has to increase the number of services, tools, workflows, and machine identities required to ship even ordinary software. More moving parts mean more keys. More keys mean more ways to leak them. The mechanics are familiar. The pace is new.Let's take a deeper look at what we found in the research across 2025.
AI is now a real credential category
The AI story goes well beyond model-provider keys. That is certainly a part of it, but just one aspect. The more interesting pattern is that the whole AI application layer is now visible in leaked secrets data. The fastest-growing detectors include the surrounding services that developers use to make AI features work in production.
However, since LLMs are at the heart of all of this new infrastructure, let's start our analysis there.
LLM Platforms: The "Model as a Service"
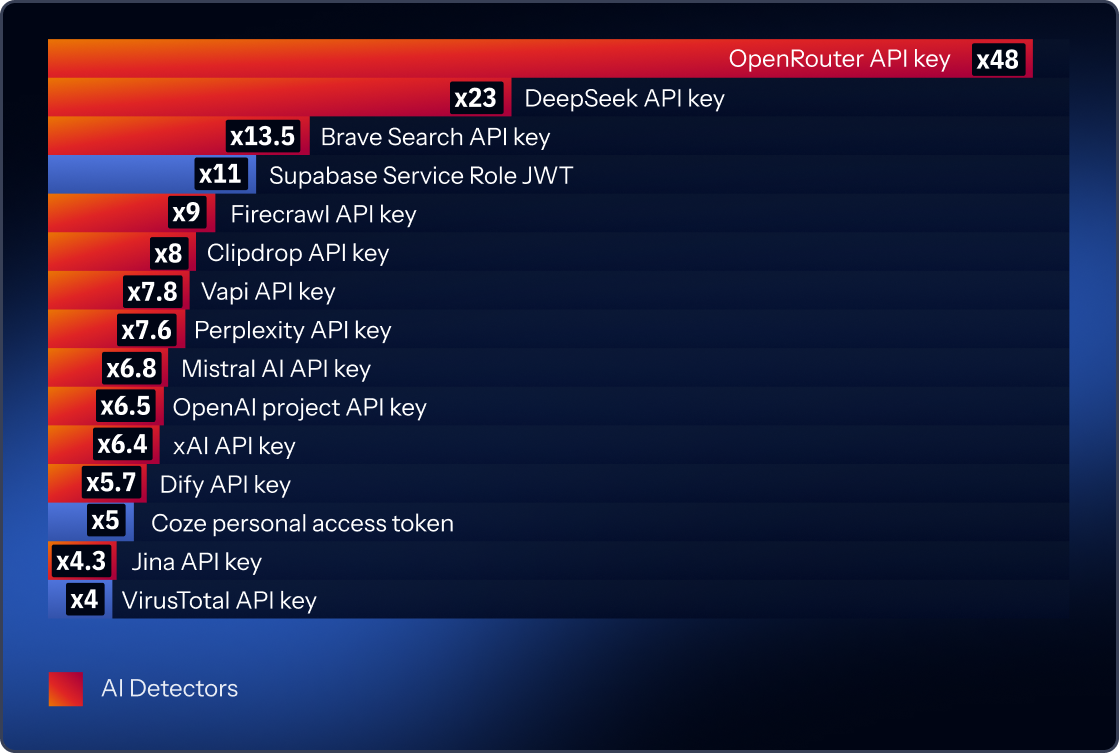
Of all the model providers, Deepseek showed the greatest change from the previous report, with 2,179% growth year-over-year.
xAI showed similar year-over-year growth to OpenAI, at 555%, but with a volume smaller than Deepseek's, at 6,273 leaks. Rounding out the top-growing platforms that developers call directly are Mistral, up 578%; Claude, up 220%; LlamaCloud, up 109%; and Cohere, up 77%. These numbers show us that production-grade model access has become mainstream in real software.
Other findings suggest that developers and teams are comparing and using multiple model vendors for their projects. This can be for failover and resiliency in their apps or to best find the model that supports their use case.
The best example of this trend is OpenRouter, which saw an astounding 4,661% more leaks. Their platform usually does not operate a single proprietary model. Instead, they act more like a gateway that lets developers access and switch among multiple models through one API.
NVIDIA is another example, where its keys often relate to AI infrastructure or AI service platforms that help teams run or deploy models, rather than being only a direct “one provider, one model API” offering.
Open Models Also Drive Leaks
Hugging Face keys leaked over 130,000 times across public GitHub in 2025, staying about the same as the previous year. HuggingFace is important, though, as it often connects the “open model” world to inference platforms, which is part of the reason we think we are seeing Groq Cloud API keys leaking at a 211% higher rate in our findings. Groq was mainly known for its compute platform and inference hardware, enabling people to efficiently run certain open-source models but at the end of 2024, they began offering access through an API through Groq Cloud.
More AI Leaks From The Growing Support Ecosystem
Other findings point to LLM usage being wrapped in a real application layer. Teams are building full products around the model, and those products need orchestration, monitoring, and data services.
Supabase is the clearest example of the adoption curve turning into leakage risk. In the 2025 report, we reported +97% year-over-year growth. This year, that growth rate jumps to +992%. Supabase is widely loved because it makes it easy to stand up a database-backed application quickly, and it has become a common default for modern AI projects, especially when developers want a fast on-ramp to vector-like workflows and retrieval patterns. The more teams reach for an AI-friendly “fast database” to ship quickly, the more likely those, often new, developers are to leak keys.
Another supporting service is LangChain, which had ~200% more leaks. LangChain is an orchestration framework that helps developers connect models to tools, prompts, and workflows. Its keys show up when teams operationalize multi-step AI features. Other examples include Weights and Biases keys, up 200%, and Jina keys, up around 400%, both of which are used to track experiments, evaluate outputs, and monitor performance over time, which is typical when an AI feature is being improved and maintained like any other production system.
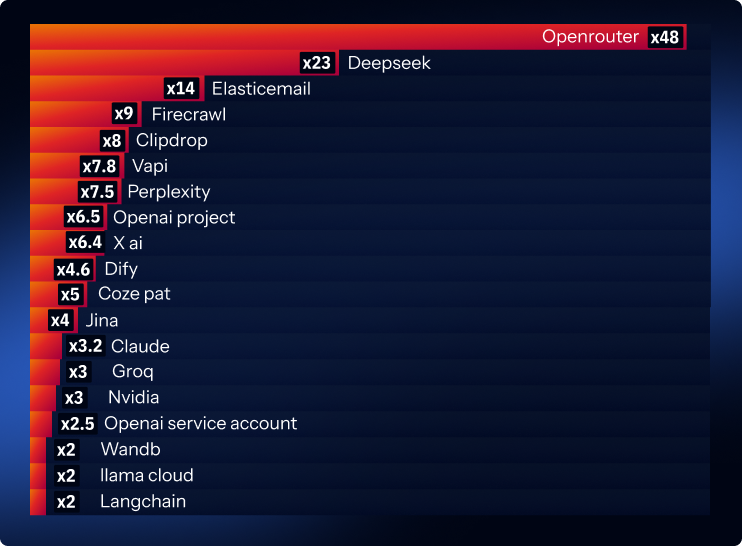
Retrieval and access layers are also showing massive growth, with Perplexity keys up 750%. Perplexity can be used as a search and retrieval API, so its key shows up when teams route questions through a service that finds sources and returns context to feed into the model.
For AI media and voice infrastructure, we see the largest changes from Vapi, up 780%. This is a developer platform for voice-based AI agents using real-time audio. Seeing these keys leak suggests that AI is moving into customer-facing experiences like voice support, sales calls, and content production, introducing new vendors and new secrets into everyday repos.
Brave Search, whose keys are up 135%, is trusted by developers to run web-style searches, pulling back relevant pages or snippets that the AI can reference. This signals that teams are building complete AI systems in production, where a single “call the model” integration quickly becomes a larger network of services and credentials that need to be managed.
When you add these together, you get a clear signal: a meaningful slice of leaked secrets in public repos is showing up because developers are building AI systems. If teams weren’t doing AI projects, these secret types would not be appearing at anything like these levels.
New AI Control Plane Players
The other broad category in our report is platforms that sit one layer above the models themselves, used to assemble complete AI applications by coordinating prompts, tools, data sources, and deployments. These become the control plane where teams build and run agent-style workflows.
The platforms showing the highest year-over-year growth in leaks are Dify, at 570%, and Coze, at 500%. These platforms help teams build agentic systems, chain tools together, manage prompts, and deploy AI features quickly, without writing everything from scratch. Coze PATs are of particular concern, as these access tokens often carry very broad account-level permissions and show up in commonly leaked artifacts, such as local configuration files and automation scripts.
The data suggests that developers are adopting higher-level agent-building platforms, increasing their speed to market, but also increasing the number of integrations and credentials in a typical AI project.
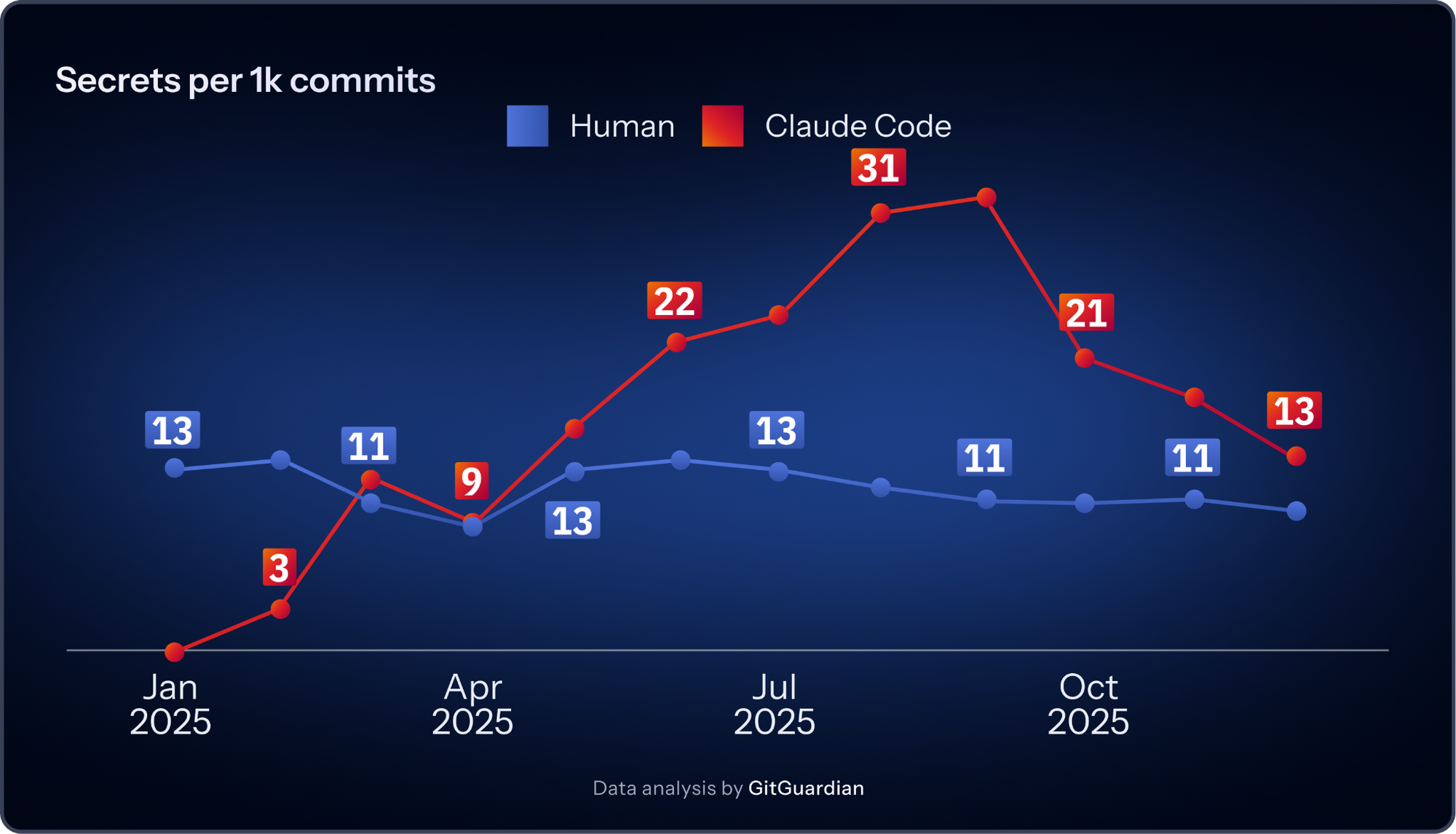
The Claude Co-signed Commits Issue: 2x The Base Rate Of Leaked Secrets
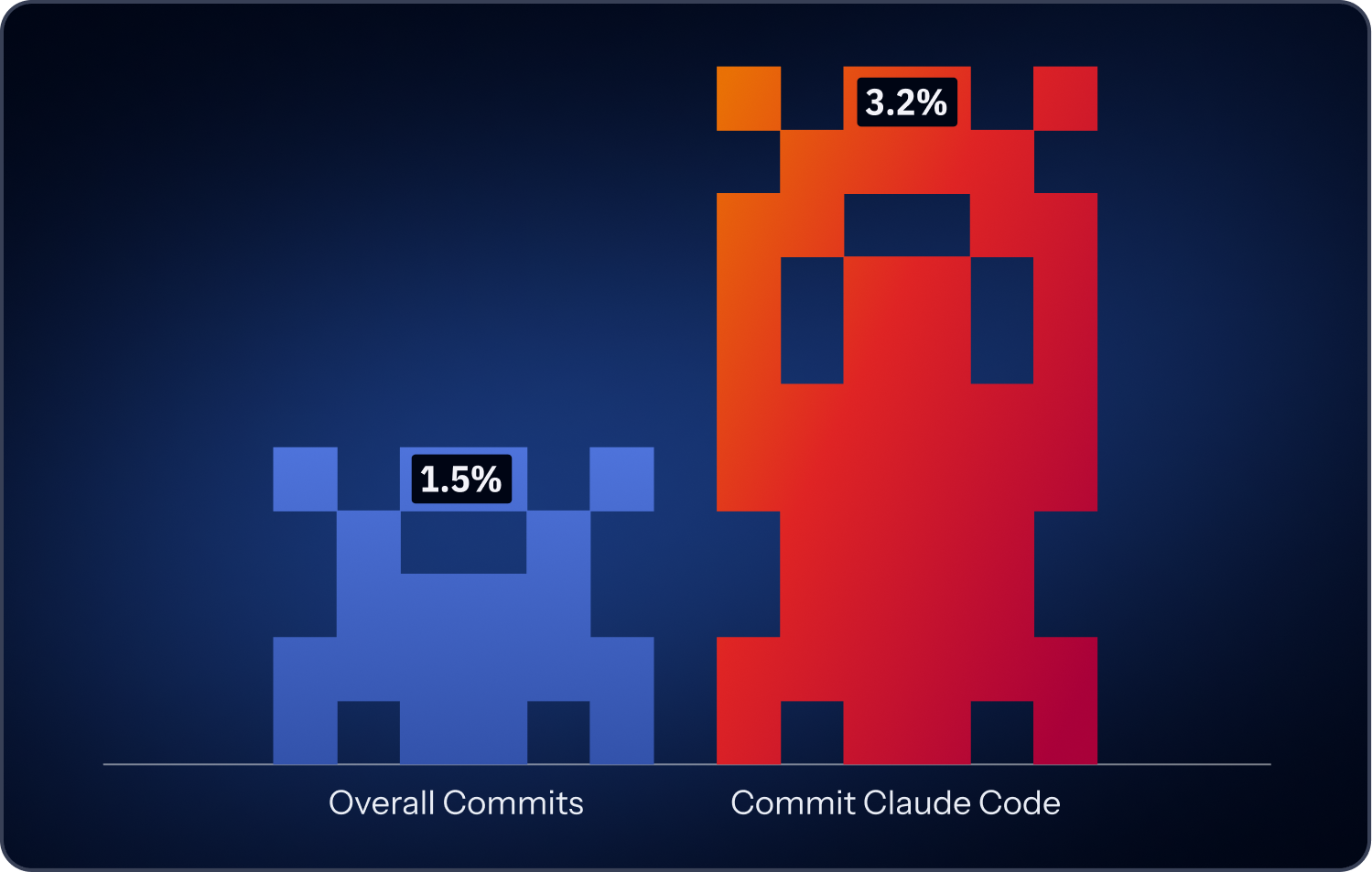
One of the most significant findings in the 2026 report has less to do with AI services and more to do with how software is now produced. GitGuardian found that AI-assisted commits significantly contribute to secrets sprawl, and that Claude Code co-authored commits leak secrets at roughly 2x the baseline across public GitHub.
2025 was the breakout year, with adoption accelerating early and then ramping sharply in the second half as multiple assistants gained traction. By year-end, AI-assisted commits had reached their highest levels.
This point is easy to overreact to, so it is worth being precise. The report is not saying one assistant is uniquely reckless or that AI coding tools are the root cause of secrets leakage. The more grounded reading is simpler. When code production speeds up, insecure patterns scale with it.
That is the real risk. AI-assisted development makes it easier to scaffold projects, test integrations, spin up backends, wire third-party services together, and publish working code quickly. Those are all useful things. They also happen to be the exact moments when credentials get pasted into config files, shell histories, local scripts, repo examples, quick demos, and half-finished automation.
Once the pace increases, those habits do not disappear. They become easier to repeat.
AI-generated code often looks finished before it is production-ready. A developer can get a feature working quickly, prove it out, and move on before anyone has asked the boring but important questions: where should this secret live, who owns it, how does it rotate, what is its scope, what breaks if it expires, and what logs or files might accidentally retain it?
AI-assisted coding data from the report is evidence that the software production has changed. We should expect more commits, more prototypes, more integrations, and more implicit machine identities. We should also expect those identities to be created faster than many organizations can realistically govern them.
Concrete Numbers From MCP Research
One of the strongest additions in this year’s report is the section on Model Context Protocol (MCP). MCP emerged in early 2025 as a common way to connect large language models to external tools and data sources. GitGuardian research found 24,008 unique secrets exposed in MCP configuration files. 14% of those were PostgreSQL database connection strings. The top leaked secret types in those files were Google API keys at 19.2%, PostgreSQL connection strings at 14%, Firecrawl at 11.9%, Perplexity at 11.2%, and Brave Search at 11%.

That list is revealing. It maps almost perfectly to the AI support layer, now showing up everywhere else in the report. Search. Retrieval. Data access. Developer tooling. External APIs. MCP gives teams a standard way to connect models to the real world. It is risky for the exact same reason.
New standards often spread through examples. People copy sample configs, tweak them, and keep moving. If those examples depend on hardcoded credentials in local files, the unsafe pattern spreads alongside the standard. This is not an MCP-specific criticism. It is a familiar story in software. Convenience wins first. Governance arrives later. By then, the insecure pattern is already normal.
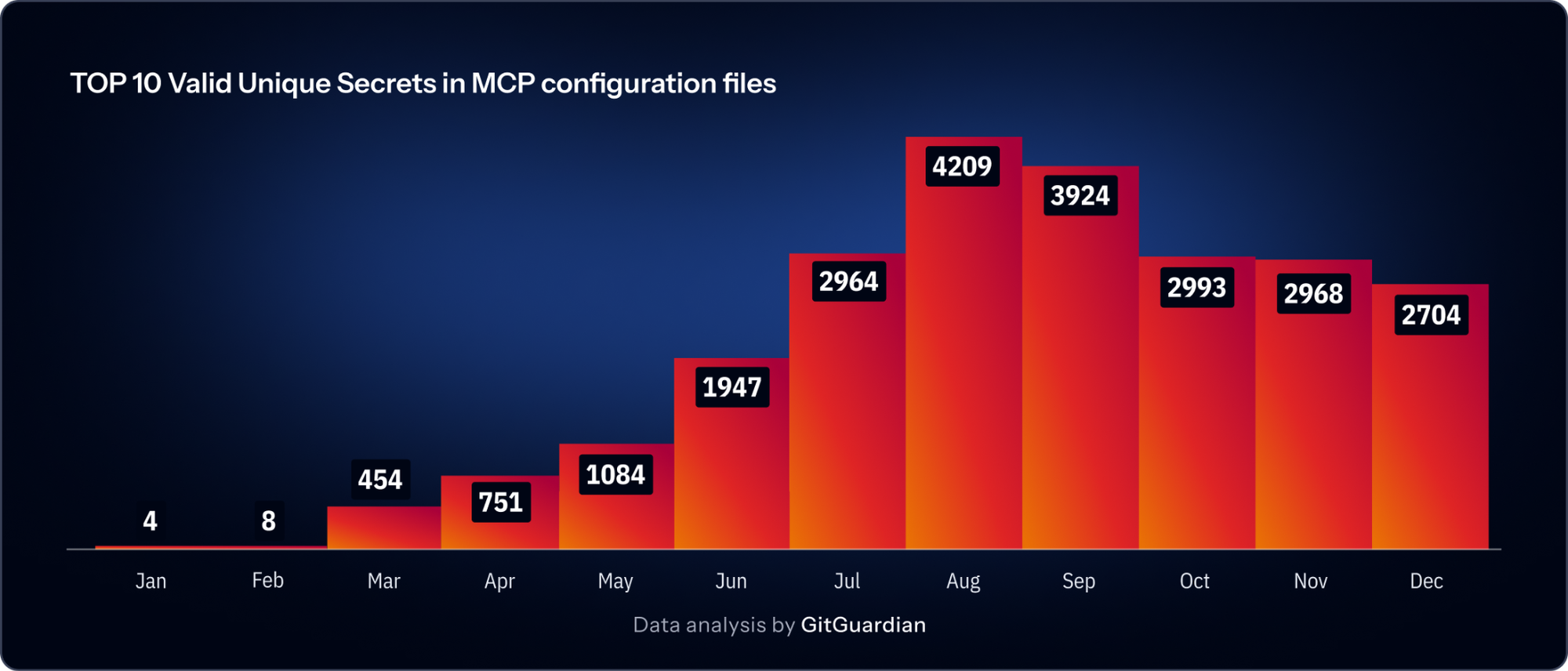
The MCP findings make the broader AI story more tangible. AI systems are not self-contained. They are built to reach out to tools, data, and services. Every connection point is another identity. Every identity needs ownership, scope, rotation, and visibility. If any of those are weak, the stack accumulates risk quietly and quickly.
Generic Detectors For The AI Ecosystem
It is important to note that this year, for the first time, our machine-learning classification for generic secrets introduces an AI category. These are cases where we have strong signals that the key correlates to AI-related projects. 4.1% of all keys we found fell into this AI-labeled generic category with high confidence.
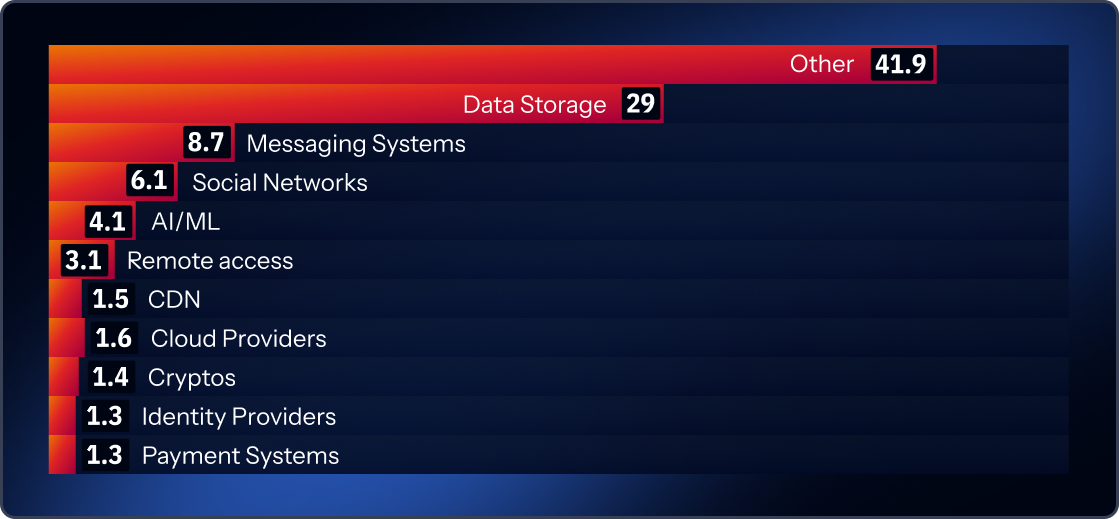
That’s the important qualifier: “with high confidence.” Generic secrets also include a very large “other/unknown” bucket (around 41.9%), meaning we can’t confidently map them to a specific purpose: that 4.1% is almost certainly a floor, not a ceiling. The AI-related fraction of generic secrets may be significantly higher.
The Bigger Story Is Identity Sprawl Driven By AI
The growing problem is the volume of Non-Human Identities created by modern software development. Service accounts, API keys, database credentials, automation tokens, deployment secrets, bot identities, project-scoped keys, and agent tool credentials. These are the connective tissue of software now. AI adds more of them by default.
GitGuardian’s policy-breach distribution makes that plain. Long-lived secrets account for 60% of policy breaches. Internally leaked secrets make up 17%. Duplicated secrets account for 16%. Publicly leaked secrets are 5%. Cross-environment leaks are 1%, and reused secrets are 0.7%. That is a useful breakdown because it shows the dominant problem is lifecycle negligence. Secrets live too long, spread too widely, and get copied faster than they are governed.

AI increases creation velocity inside organizations that already struggle with ownership and remediation. More identities are born. More secrets are copied into more places. Fewer teams know which ones matter most, who should rotate them, and what systems depend on them. The stack expands. The discipline does not expand at the same rate.
What We Learned About AI Use
AI did not create secrets sprawl, but it is now accelerating every condition that makes secrets sprawl worse. More people can build. More code gets shipped. More third-party services get connected. More machine identities get created. More local and temporary configuration surfaces appear. More insecure patterns survive because the fastest path to shipping still usually involves “just add a key.”
That is why the real AI lesson in this report is not “watch your model keys.” It is broader. The AI stack is now part of the normal software stack, and the normal software stack already runs on credentials. Once that clicks, secrets security stops looking like a niche problem for DevOps teams and starts looking like a core operating problem for software organizations.
The teams that handle this shift best will not just detect more exposed credentials. They will get better at controlling the lifecycle behind them. It will empower people to confidently answer, "Who created the identity? What can it reach? How narrowly is it scoped? Where is it stored? When it rotates? What depends on it? When should it die?"
That work is less glamorous than shipping a new assistant, agent, or AI feature. It is also the difference between speed that compounds and speed that eventually breaks things.
AI is making software easier to produce. When software gets easier to produce, identities get easier to create. And when identities get easier to create, secrets spread faster than most teams are ready for.







