TL;DR
We introduced our automated severity scoring engine a few months ago for detecting hard-coded secrets. After a successful private beta where it proved to be a massive time-saver for appsec teams investigating and prioritizing secrets incidents, we're excited to announce that we've rolled it out to all free tier users. So far, it has automatically assigned severity levels to over 4 million incidents, covering 83% of the total and spanning 375,000 accounts!
Today, we're taking it a step further with an enhanced version. Managers and owners of GitGuardian workspaces can now edit the default ruleset or create their own severity rules.
Our bet is simple: more fine-tuned rules mean better coverage. And better coverage means security engineers can spend less time manually evaluating severities and instead focus on the most critical issues.
Why you should automate severity scoring
In the own words of the Head of Engineering of a governmental agency,
“This helps to prioritize remediation quickly. When we go back to the historical scan, it [GitGuardian] can tell us not only what secrets were exposed but also the general risk level of each incident. This allows us to prioritize remediation efforts and focus on the more critical vulnerabilities first.”
Hardcoded secrets, such as API keys and passwords embedded directly into code or exposed in various places like CI job logs, Docker images, Slack conversations, and Jira tickets, pose significant security risks. We initially built a detection engine to scan entire codebases and alert developers and their security teams. However, we soon realized that the sheer volume of hardcoded secrets was overwhelming for security engineers to handle individually. After all, they're only human.
Still, security teams stressed their need to address the problem comprehensively and prioritize risk reduction without wasting productivity. This is where GitGuardian's automated severity scoring engine comes in.
Every incident raised is carefully categorized into severity levels such as "low," "medium," "high," "critical," "info," or "unknown." By employing GitGuardian's automated severity scoring engine, application security teams can:
- Tackle the most severe incidents head-on, significantly mitigating the risk of exploitation.
- Allocate response efforts based on risk, resulting in time and resource savings.
- Maintain a proactive approach towards secrets security and enhance the overall posture.
- Avoid inconsistent scoring across individuals (resulting from manual efforts).
Get started
First, turn it on
GitGuardian's severity scoring engine has 15 built-in rules ready to run against the entire history of your hardcoded secret incidents and the new ones.
Sign in to your GitGuardian account, go to your workspace settings, and click "Secrets detection" in the menu—Toggle Automated Severity Scoring on.
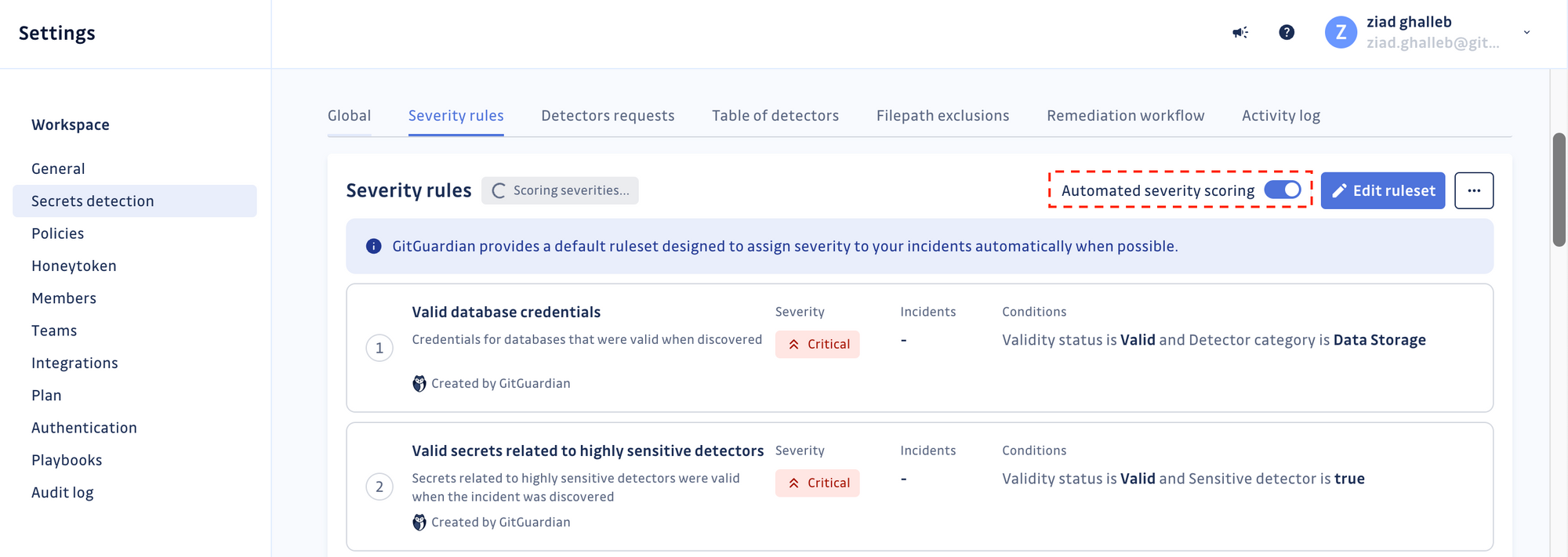
Each rule employs multiple factors to evaluate the severity of every incident, such as:
- The type of secret. Certain secrets, such as Cloud Service Providers' API keys or database connection URLs, are prized by attackers and require immediate attention.
- The validity of the secret is assessed as well. Exposed secrets that are valid present a higher risk level than others.
- The visibility of the secret is also a determining factor. Secrets accessible to the public are regarded as more severe than those concealed within private repositories.
In addition to assigning severity levels, the engine provides a coverage metric. This metric indicates the percentage of incidents for which severity levels were set, giving users insight into the engine's effectiveness and helping them identify coverage gaps.
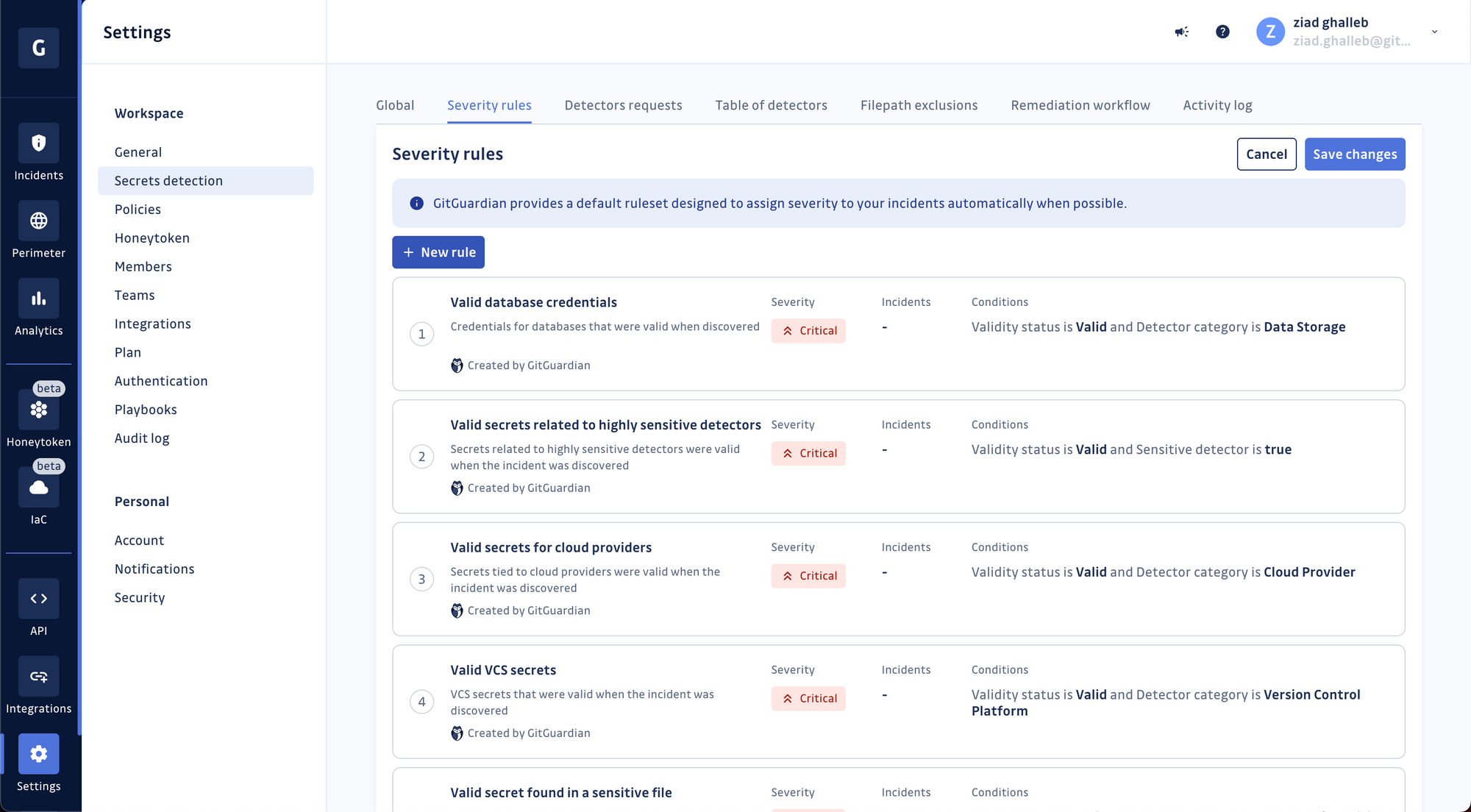
Edit or create a new rule
GitGuardian's built-in rules are an excellent place to start. Still, you may notice they're not fully aligned with the nature of software development in your organization and are leaving some gaps here and there in their coverage.
This is why we've enabled you to adapt existing rules by editing their properties, conditions, and severity value or even create new ones from scratch.
Let's create your first rule together.
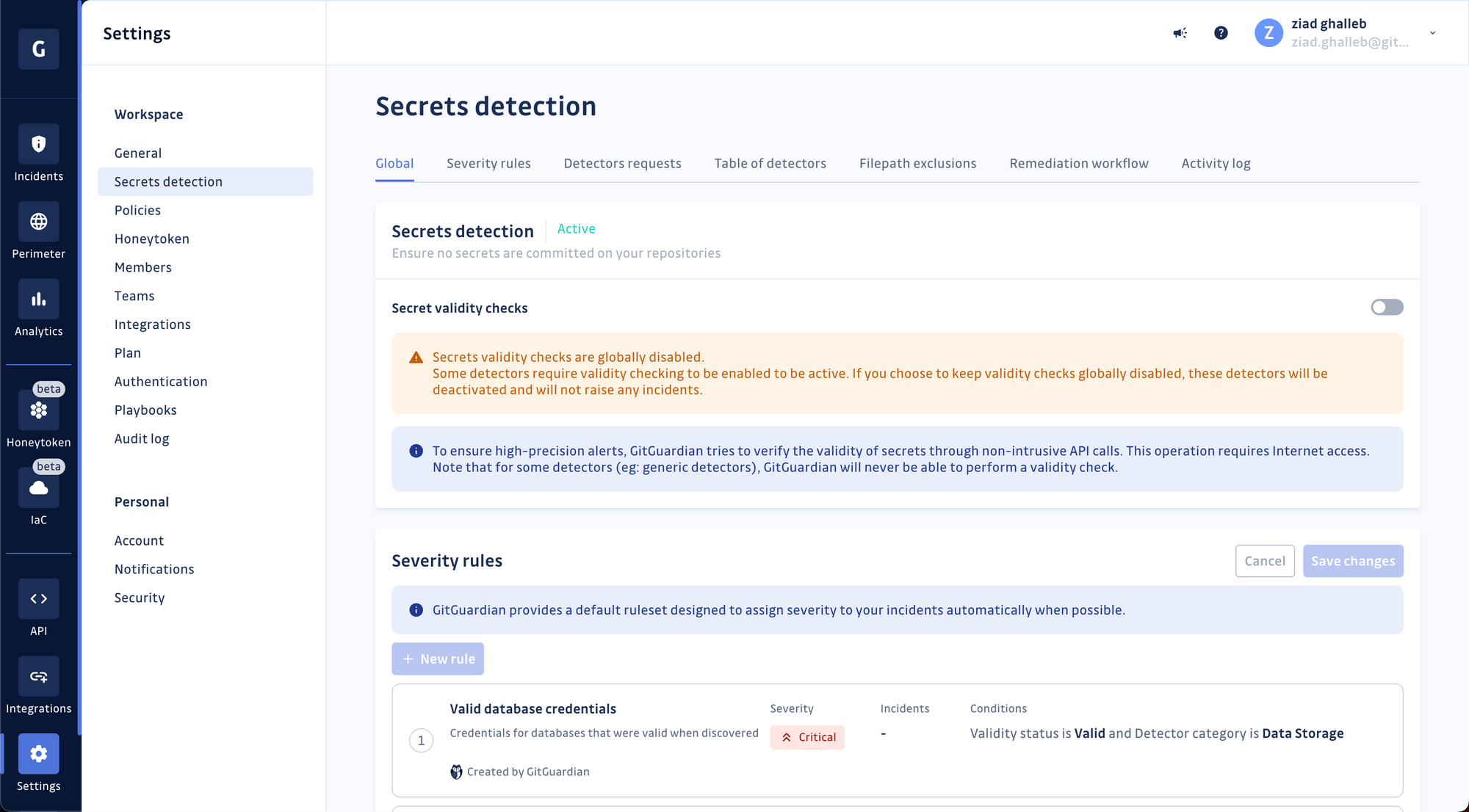
Click the "Severity rules" tab, then create a new rule.
Choose a name for your rule and add a short description. Then proceed to define the conditions of your new rule. In this example, we're looking for occurrences of GitHub Personal Access Tokens that were found valid by GitGuardian's validity-checking mechanism and exposed in public repositories.
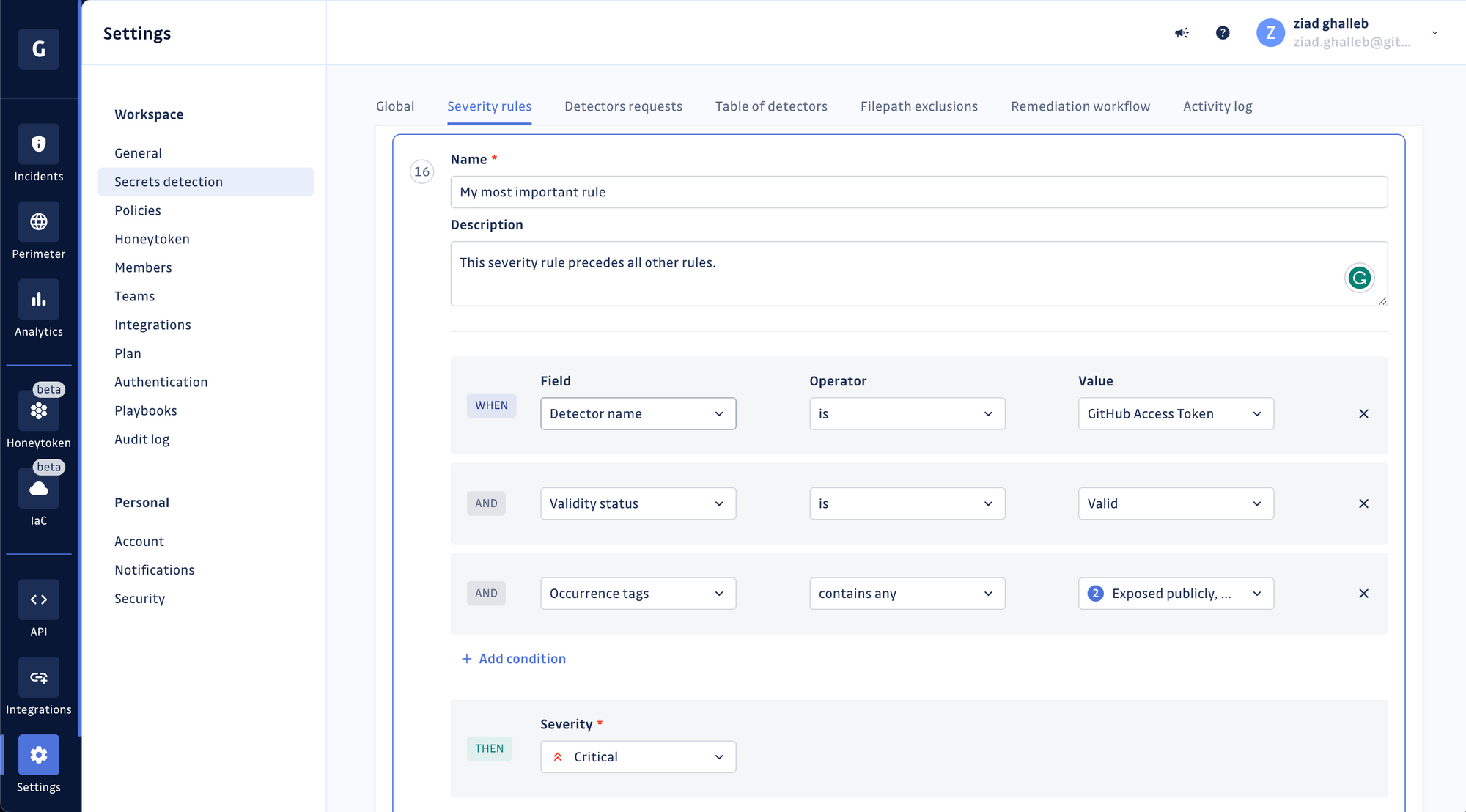
Choose the severity level for your rule and save it. Once it's created, the rule will be added to the bottom of your existing stack.
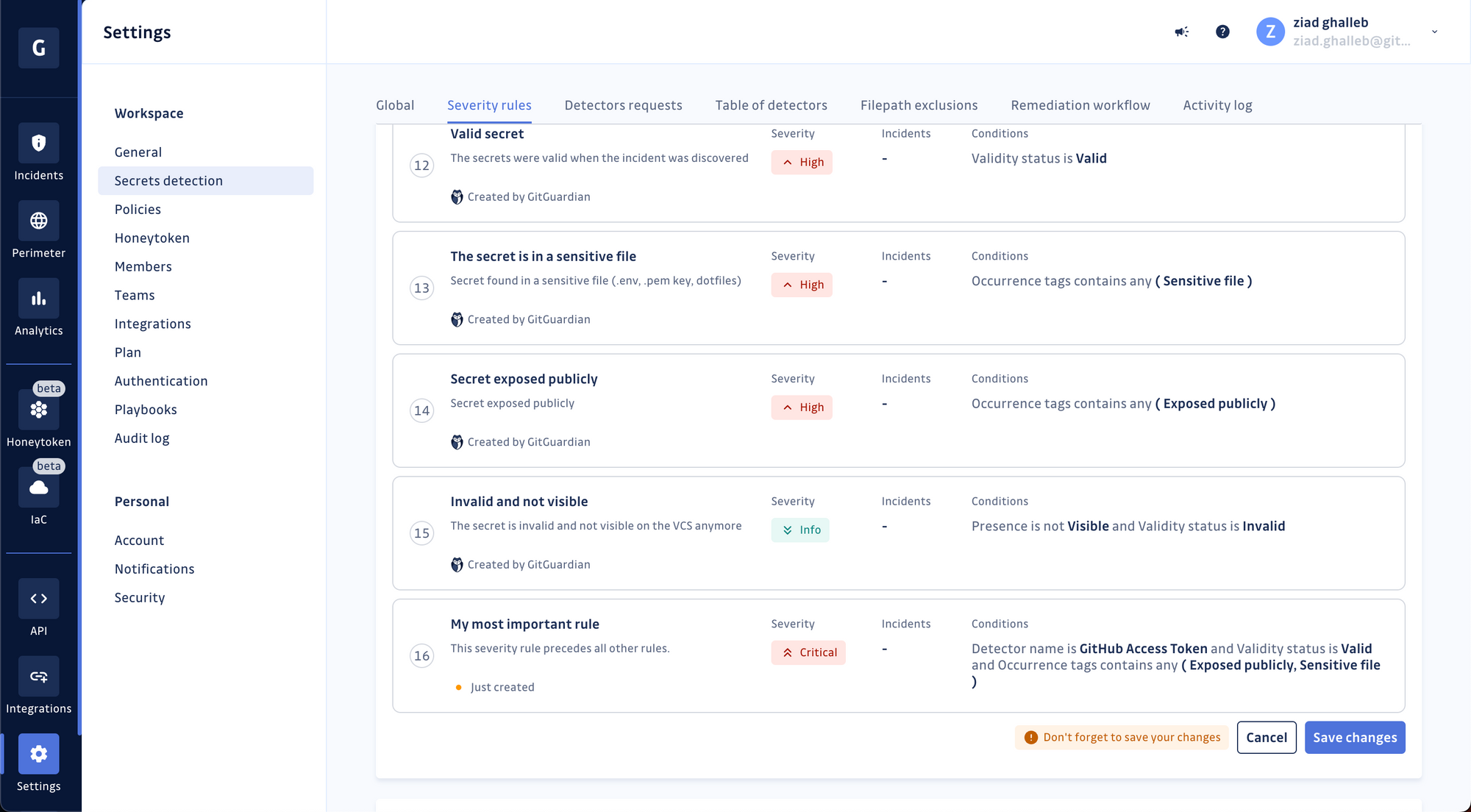
Incidents are evaluated sequentially against the rules, so your new rule will be considered the least important. You can move it around for it to take precedence over other rules.
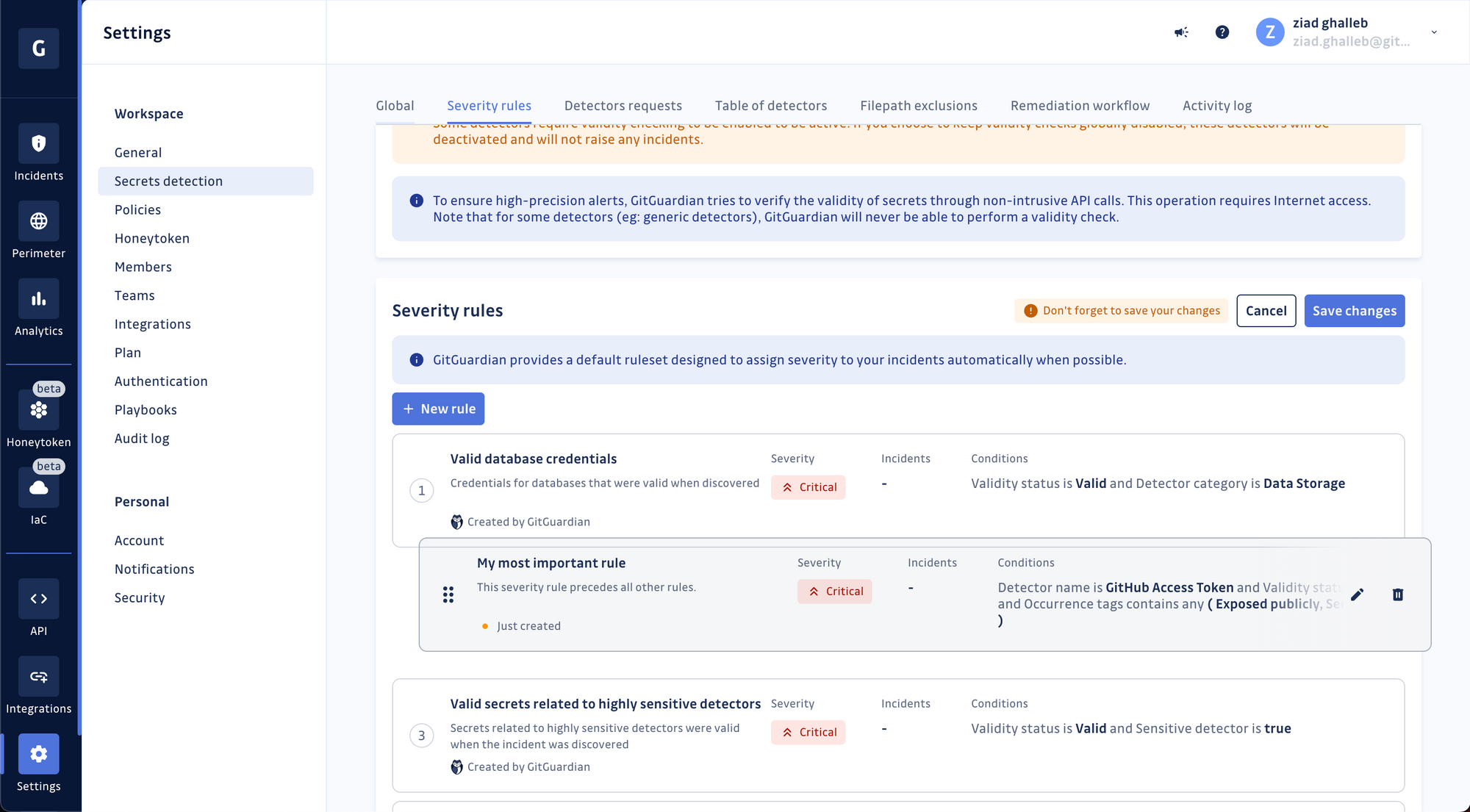
Voilà! Don't forget to save your updated list of rules before leaving.
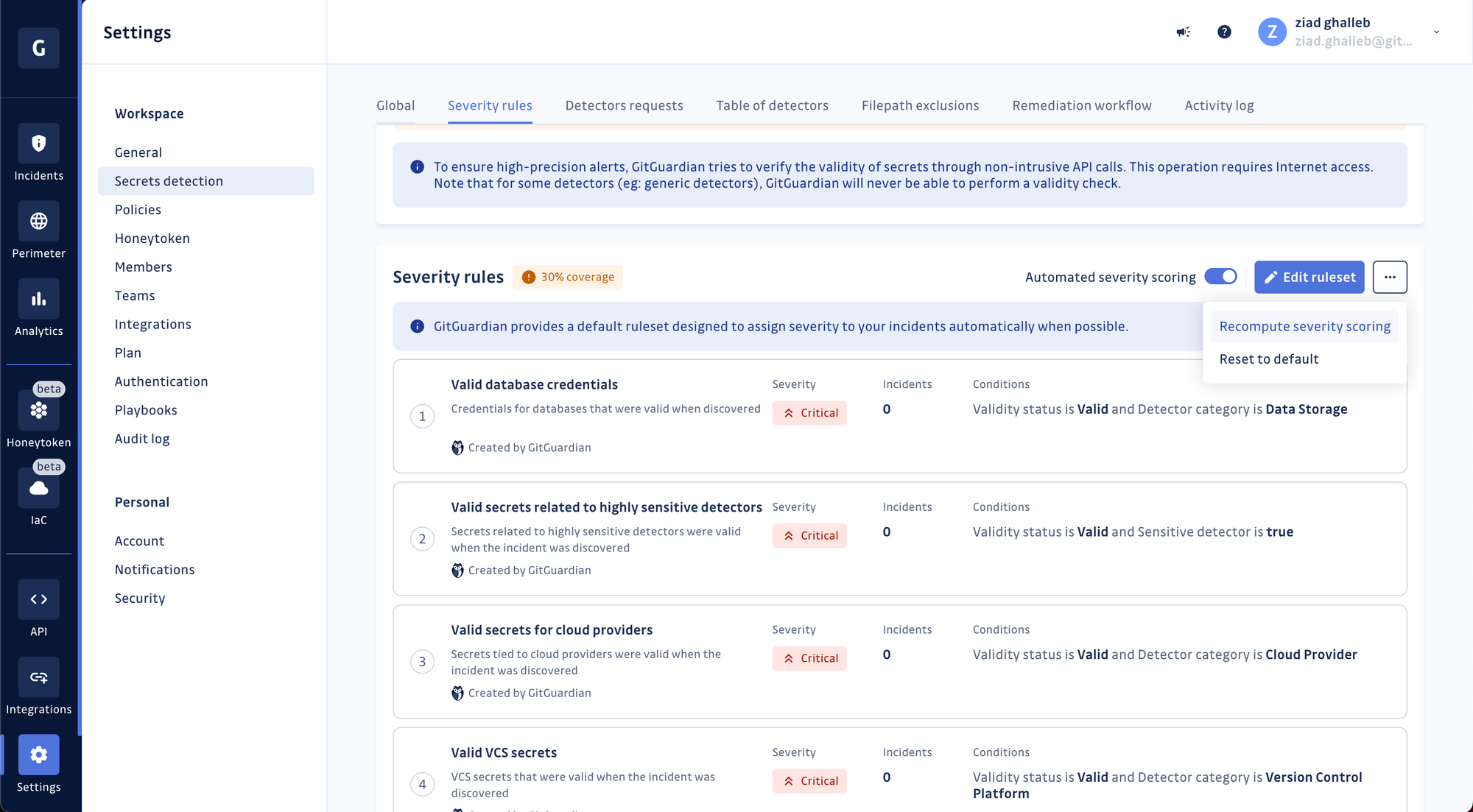
We can't wait to see what rules you will create! If you already have a GitGuardian account, go to your workspace settings and try it out!
If you haven't created a GitGuardian account yet, you can find detailed information about GitGuardian and how it can help protect your organization's software supply chain from exposed secrets at https://www.gitguardian.com.
To learn more about our approach to automating manual steps in the remediation process using no-code, you can read "Automate your way out of code security incidents with GitGuardian's playbooks."