False Positives are Harming AppSec Efforts
False Positives occur when a detection system incorrectly identifies harmless events as risks. This is a common problem with most security vulnerabilities including secrets. Claiming to have zero false positives is unrealistic or proof that you will miss true positives in the process. Consequently, our challenge is to provide the best trade-off between recall and precision.
Far from being just a technical achievement, it's a necessity that directly impacts our users on a daily basis. False positives are a waste of time and resources, creating unnecessary stress and tiring out teams. Ultimately, too many false positives risk making teams ignore real threats when they appear and being counter-productive by harming security overall.
Therefore, reducing false positives is imperative for appsec efficiency. It helps Security and Engineering teams:
- Save time and resources: Security and engineering teams will spend significantly less time reviewing and dismissing false alerts.
- Increase their precision: Avoid overlooking genuine threats due to the volume of false positives.
- Reduce alert fatigue: Continuous false alarms can lead to desensitization, causing real threats to be ignored.
Generic Secrets is the Name of the Game
Secrets detectors come in two forms. Specific detectors are designed to identify a particular type of secret with a well-defined pattern, such as AWS keys. It guarantees a 100% recall with almost perfect precision.
However, not all secrets can be detected by specific detectors, because secrets don't always follow a predictable pattern, or have a new pattern not yet supported by specific detectors. That's why GitGuardian introduced generic detectors to catch any type of secret based on contextual information. These detectors are crucial to ensure a good recall, typically catching 50 to 70% of all incidents on our customers’ environments.
For years, GitGuardian’s secrets detection team has adopted a data-driven approach to make these detectors as precise as possible. This is a daunting task, and we still have a few false positives that make it through our algorithms.
Introducing FP Remover, our Machine Learning Model that Understands When Secrets Are Not
In a groundbreaking achievement that will set a new industry standard, GitGuardian's Machine Learning experts and Secrets Detection team have joined forces to create FP Remover, a new ML model that achieves an unseen signal-to-noise ratio for secrets detection.
Here is our estimated generic detectors' performance before using FP remover:

Of all the flagged secrets by our generic detectors, we presume that 90% were True Positives and 10% were False Positives. FP Remover was developed to decrease the number of false positives mistakenly detected.

FP Remover predicts that approximately 5.3% of the total secrets previously identified by the generic detectors are false positives. Multiple experiments have confirmed this is almost always the case.
In other words, where generic detectors previously identified 10% of false positives, FP remover cuts this number by half and crushes the time engineers lose on false alarms so they can focus on what matters: remediation of real exposed secrets.
For practitioners, it means that GitGuardian will continue to present the same number of true positives as before, with very few exceptions, and significantly fewer false positives.
Behind the Scenes: How Does it Work?
FP Remover is an in-house ML model based on a transformer architecture, trained on a large amount of code data and fine-tuned on our secrets detection datasets.
We estimate that about 30% of the secrets identified by generic detectors are rarely false positives. When users encounter the same secret value, they may sometimes claim it's a false positive, while other times they may dispute this and need to investigate the code before reaching a conclusion
So we made FP Remover understand code like a developer, and trained it to remove the most evident false positives. For instance, it will identify:
- False Positives that can not be a secret based on code-specific semantics such as variable names or type annotations.
if args.password: cmds += ['-p', args.password]- False Positives that can be identified through context understanding.
{...
"signup_form_username": "Identificador",
"signup_form_password": "Contrasinal",
"signup_form_confirm_password": " Confirmar contrasinal",
"signup_form_button_submit": "Crear conta",
...}Confirmar contrasinal means Confirm password in Galician.
Limitations of the model and potential improvements
Our team decided to take a conservative approach, avoiding an overly aggressive model when identifying false positives to prevent the removal of too many actual secrets. Despite this setup, a small number of false positives slip through the cracks.
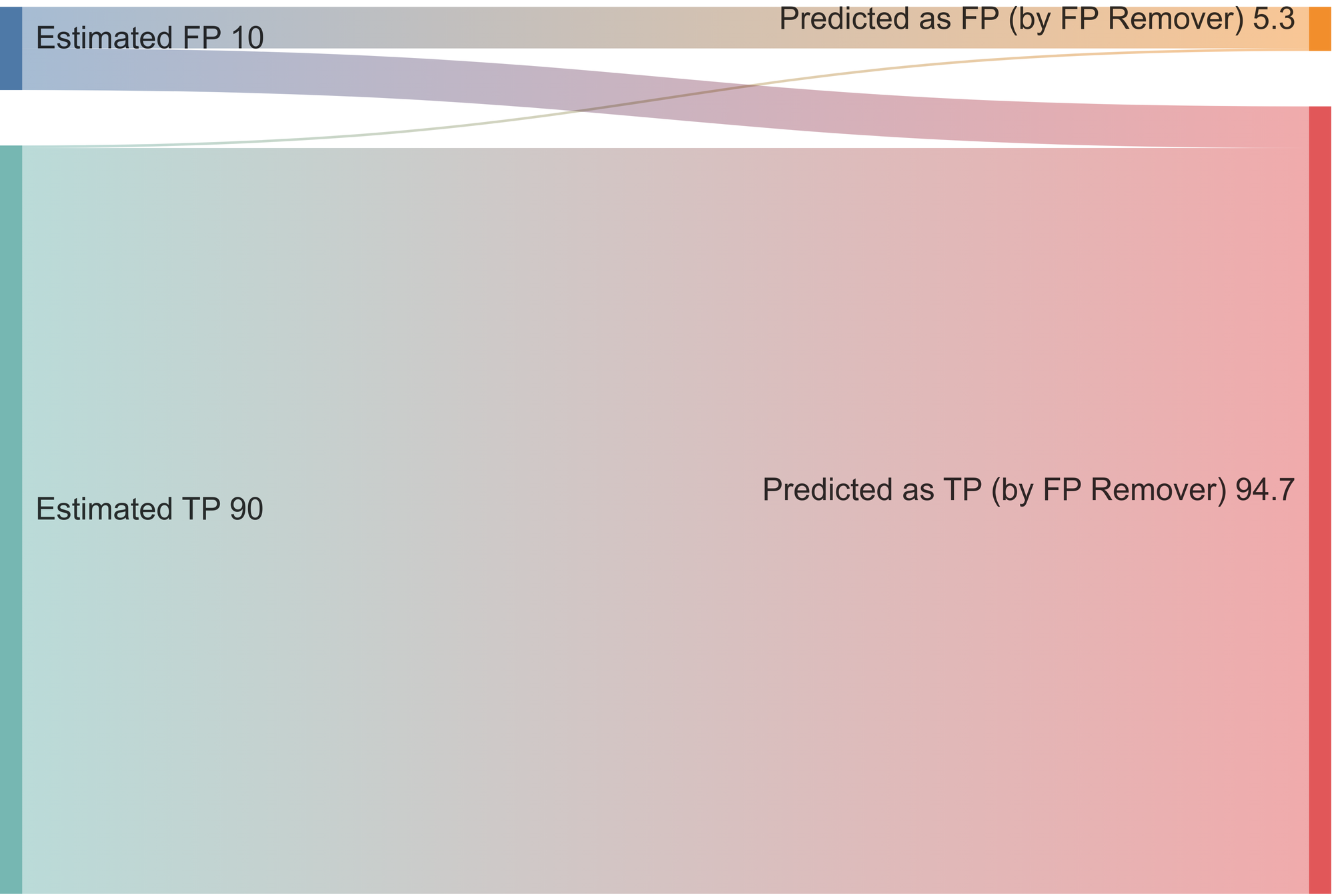
FP Remover will eliminate half of the 10% of false positives that were incorrectly identified as secrets but will also discard 0.3% of true positives. This trade-off is considered acceptable because GitGuardian's secrets detection is comprehensive enough to have a very low rate of missed true positives.
The Machine Learning team is already working on a more efficient version of FP Remover that will consider additional contextual factors such as filenames, repository structures, and others.
Conclusion
FP Remover is a major improvement to GitGuardian’s user experience and for code security overall. Users will spend more time remediating actual incidents, and less time investigating false alarms. While it represents an important milestone in our continuous efforts to improve our secrets detection engine, it is just the beginning of what can be achieved through ML.
Over time, our teams will improve the performance of our Machine Learning models with our community of 500K developers and customers. We are also exploring other approaches, such as utilizing ML earlier in the process, to reduce alert fatigue and eliminate false positives
But detection without remediation is just noise. This is why our ML teams are already focused on supplying additional information and context about secrets identified through our generic detectors. This will assist our users in prioritizing and addressing the most critical vulnerabilities.