
Detecting secrets in source code is like finding needles in a haystack: there are a lot more sticks than there are needles, and you don’t know how many needles might be in the haystack. In the case of secrets detection, you don’t even know what all the needles look like!
This is the issue we are presented with when trying to evaluate the performance of probabilistic classification algorithms like secrets detection. This blog will explain why the accuracy metric is not relevant in the context of secrets detection, and will introduce two other metrics to be considered together instead: precision and recall.
Accuracy, precision and recall metrics answer three very different questions:
Accuracy: What percentage of times did you take a stick for a needle, and a needle for a stick?
Precision: Looking at all the needles that you were able to find, what percentage are actually needles?
Recall: Among all needles that were to be found, what percentage of needles did you find?

Why is accuracy not a good measurement of success for secrets detection?
The difference is subtle in their descriptions but can make a huge impact to metrics.
Going back to the needle analogy, if we take a group of 100 objects, 98 sticks and 2 needles then we create an algorithm to detect all the needles. After running, the algorithm identified all sticks correctly but only 1 needle, then this algorithm failed 50% of the time at its core objective, yet because it detected the sticks correctly it still has a 99% accuracy rate.
So, what happened? Accuracy is a common measurement used in model evaluation, but in this case, accuracy gives us the least usable data, this is because there are a lot more sticks than there are needles in our haystack, and equal weight is applied to both false positives (the algorithm took a stick for a needle) and false negatives (the algorithm took a needle for a stick).
This is why accuracy is not a good measurement to determine success in secrets detection algorithms. Precision and recall look at the algorithm's primary objective and use this to evaluate its success, in this case, how many needles were identified correctly and how many needles were missed.
High Precision = low number of false alerts
High Recall = low number of secrets missed
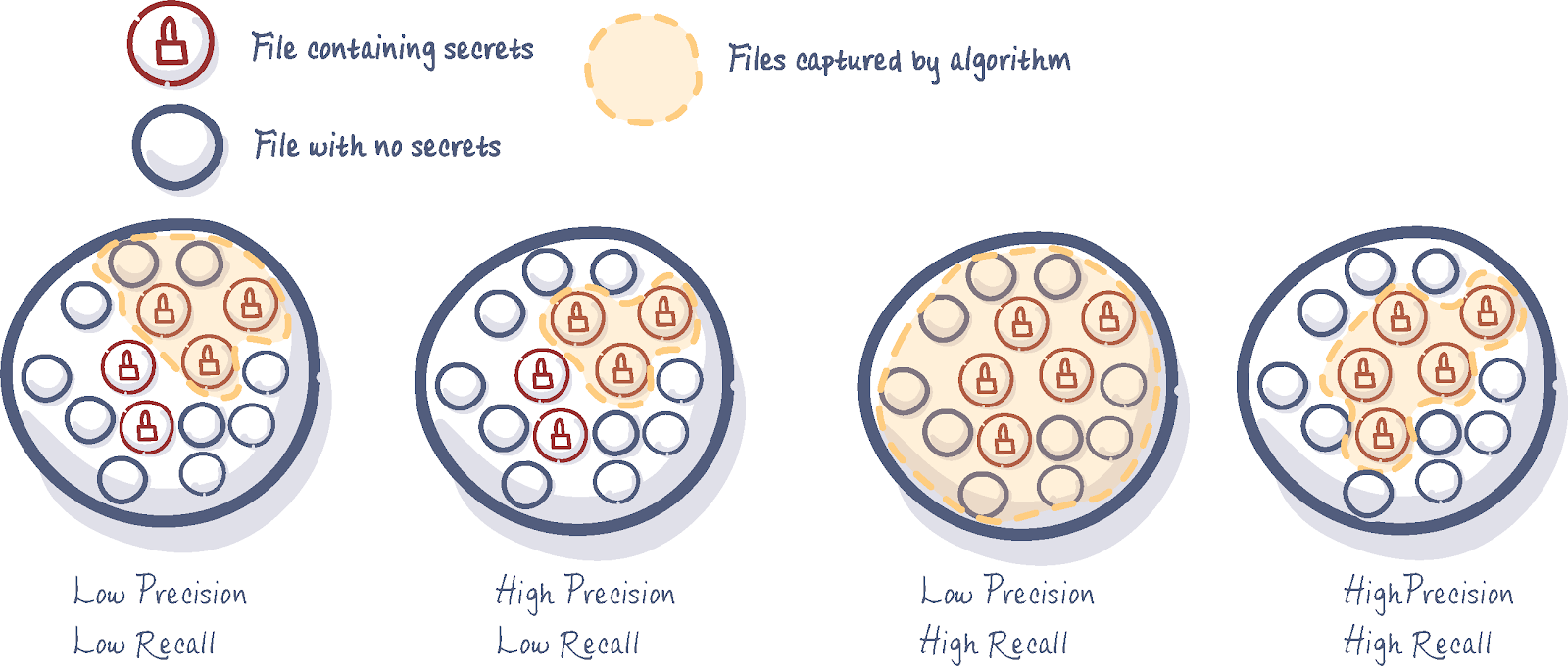
It is really easy to create an algorithm with 100% recall: flag every commit as a secret. It is also really easy to create an algorithm with 100% precision as well: flag only one time, for the secret you are the most confident it is indeed a secret. These two naive algorithms are obviously useless. It is combining both precision and recall that is the challenge.
How can we properly evaluate the performance of a secrets detection model?
Let’s take a hypothetical algorithm that scans 1,000 source code files for potential secrets.
In this example we will state:
- 975 files contained no secrets within the source code
- 25 files contained secrets within the source code
The algorithm detected
- 950 True Negatives (TN): No secrets detected where no secrets existed
- 25 False Positives (FP): Detected secrets that were not true secrets
- 15 True Positives (TP): Detected secrets where secrets exist
- 10 False Negatives (FN): Detected no secrets where secrets did exist
This can be displayed on a confusion matrix (below) which is a performance measurement tool for classification algorithms to help visualize data and calculate probabilities.
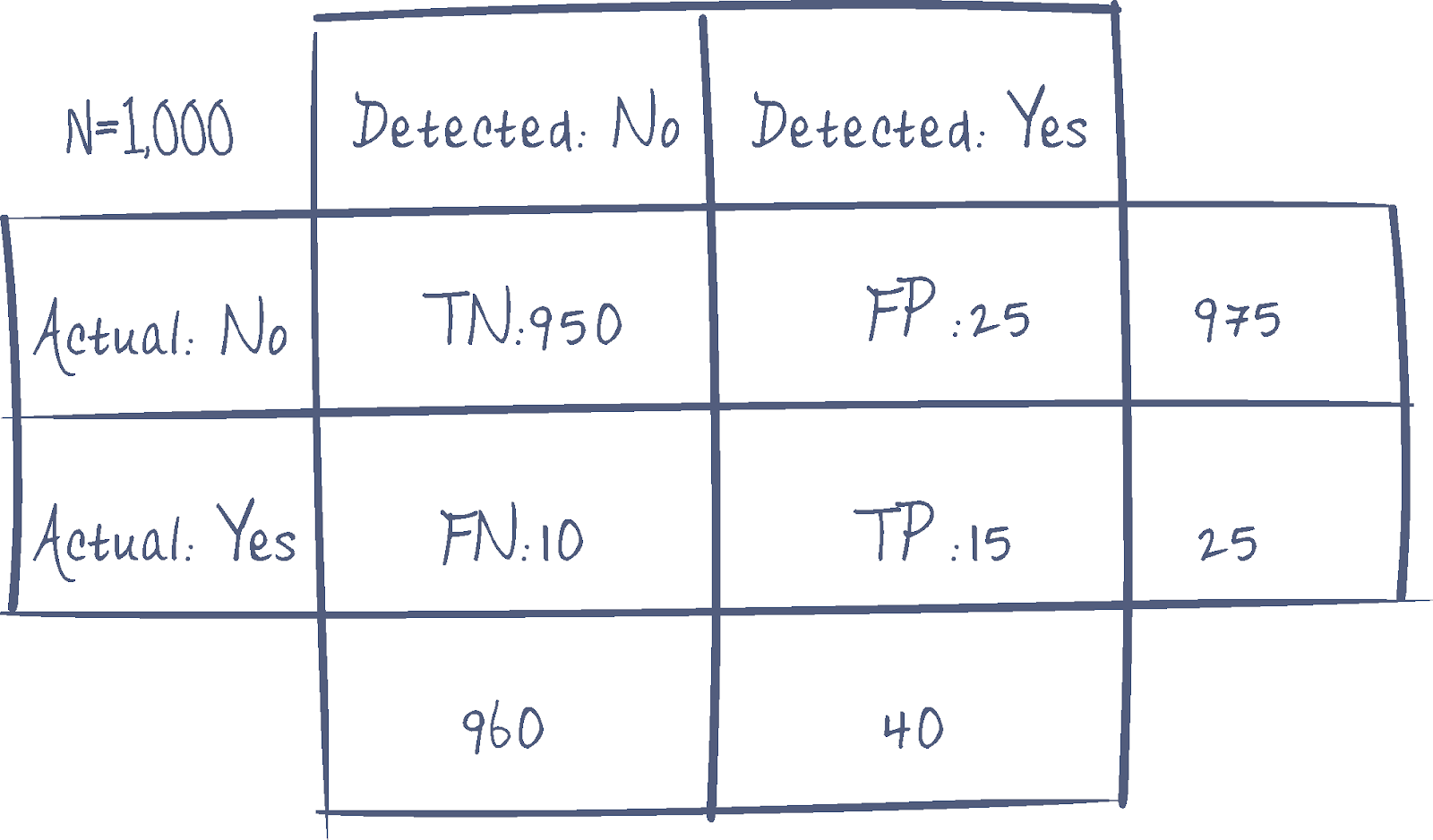
We can use this matrix to gather a range of different data including accuracy, precision and recall.
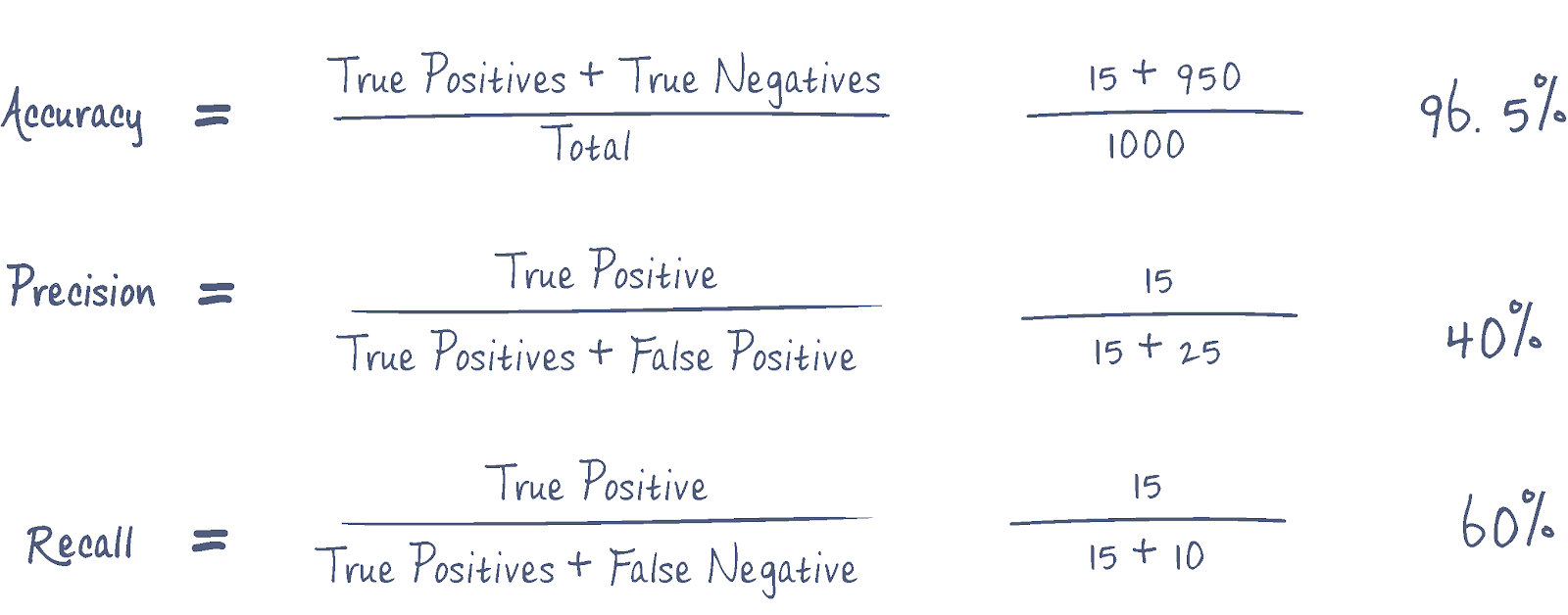
So what do these results show? We can extrapolate that our model has a 96.5% accuracy rate, this seems pretty good, and you may think that it means it detects secrets 96.5% of the time.
This would be incorrect because this hypothetical model is really only beneficial for not detecting secrets that aren’t there. This is similar to an algorithm that's great at predicting car accidents that don’t happen.
If we look at metrics other than accuracy, we can see how this model begins to fail.
Precision = 40%
Recall = 60%
All of a sudden, the model doesn’t seem to be beneficial. It only returns 60% of the secrets and only 40% of total returned secrets are true positives!
Balancing the equation: achieving high precision, high recall secrets detection algorithm
Balancing the equation to ensure that the highest possible number of secrets are captured without flagging too many false results is an intricate and extremely difficult challenge.
So difficult that GitGuardian dedicated an entire team to train secrets detection algorithms and find the correct balance of high recall and high precision.
You can learn more about the subtleties of this challenge in this blogpost from our Secrets team.
This is essential when a precision that is too high may lead to secret leaks going undetected, while a low precision will create too many false alerts, rendering the tool useless.
There are no shortcuts when building and refining an algorithm. They need to be extensively trained with huge amounts of data and constant supervision.
When talking about why some models fail, Scott Robinson from Lucina healths talks of three core failures when training an AI algorithm:
“No1: Insufficient data,
No2: Insufficient supervision,
No3: Black box failures“.
(black box systems are those that are so complex they become impenetrable)
It is important also to realize that when building algorithms for probabilistic scenarios, they will change over time. There is no perfect solution that can remain the same, trends will change, secrets will change, data will change, formats will change and therefore, your algorithm will need to change.
“People can create an algorithm, but the data really makes it useful”
Kapil Raina
GitGuardian as an example
GitGuardian is the world leader in secrets detection, which has been achieved largely due to the vast amount of information that has gone through the algorithm.
Over 1 billion commits scanned and evaluated every single year with over 2 million alerts that have been sent to developers and security teams. We’ve collected a lot of explicit (alert marked as true or false) and implicit (commit or repository deleted after our alert) feedback. It is a great example of how effective retraining of data, particularly at this large scale, can be used to continuously improve an algorithm's precision and recall.
At the start in 2017, GitGuardian was detecting 200 secrets per day on GitHub, a benchmark set by other offerings on the market. With extensive model training, GitGuardian now detects over 5,000 per day with a 95% precision.
There are no shortcuts in building algorithms. We’ve battle-tested our algorithms on public GitHub with billions of commits (yes billions), and these algorithms can now be used to detect secrets in private repositories as well. It would have been impossible to launch detection in private repositories without doing so on public GitHub first.
Update November 2021: if you want to learn more about our secrets detection engine, please check out our new series explaining the workings and performance of what we've built:
 Guardians
Guardians Guardians
Guardians Guardians
Guardians









