

Despite their well-known risks, hard-coded secrets are still a common practice in cloud environments to simplify testing and deployment. Docker images are not immune and can inadvertently leak secrets in Dockerfile or within layers. Once uploaded to public registries, these secrets can be discovered by attackers, endangering the companies concerned.
Unlike vulnerabilities, valid secrets enable attackers to have the same access as associated users or machines, making detection of such access complicated because it is similar to legitimate behavior.
For attackers, the main challenge is to discover valid secrets that will enable them to simply elevate their privileges, for example, during initial access. GitHub is a good example of a data source containing secrets, and it is not uncommon to find highly sensitive secrets concerning private Artifactory instances or Azure Blob Storage.

In this context, this post presents the results of a campaign to identify secrets in Docker images publicly accessible on the DockerHub registry. It took place in the last quarter of 2024, and involved 15 million images for which all configuration files (equivalent to the contents of the Dockerfile) and 16 million layers were scanned for secrets. This represents over 50TB that have been downloaded, and over 100,000 valid secrets authorizing access to resources usually protected by authentication.
Docker 101
To ensure image distribution, Docker relies on the notion of a registry: a web service with a well-defined API for uploading and downloading images. DockerHub is the default registry and is the focus of this post.
Each registry contains repositories, such as gitguardian/ggshield, with associated tags. The association of a repository and a tag is commonly called a Docker image.
The following script summarizes how to use this API to retrieve useful information to search for secrets in the gitguardian/ggshield repository:
Line 3 retrieves an authentication token, which will be used for future calls. Line 8 lists the tags within the repository, including latest. Line 11 lists the layers of the image gitguardian/ggshield:latest. There are 9, for a total size of around 100MB. This call also gives the manifest fingerprint. It is retrieved on line 15 and its contents correspond to the original Dockerfile. The manifest lists all the instructions used to build the image before it is distributed on DockerHub.
Using these simple commands, it is possible to manually retrieve the Dockerfile and the contents of the layers to search for secrets. This is exactly what our gsshield tool does when it scans a single Docker image.
DockerHub Analysis Methodology
While registries expose the /v2/_catalog API for listing all repositories, this is not the case with DockerHub, for which only a classic keyword search is available. This is not an unavoidable obstacle, and you can search for keywords of interest, such as production, staging, or internal, but the results are limited to a maximum of 10,000 repositories.
To uncover as many repositories as possible, an exhaustive enumeration was used to build up keywords returning less than 10,000 repositories each. For example, if the keyword docker returns 10,000 repositories, we then try dockera, then dockeraa, and so on. The enumeration took about two weeks and listed more than 9 million unique repositories for around 3 million different users (like gitguardian).
With this list of repositories, the next step is to retrieve all the associated tags. Unsurprisingly, latest is the most frequently used tag.
At this stage of the experiment, this corresponds to around 26 million public Docker images to download and analyze. That sounds perfectly reasonable but, in practice, we're talking about 11 PB of data in total. That's a huge amount, and what's more, our experience suggests that much of it is useless.
Why is this? As described in the previous section, a Docker image is made up of several files, including :
- a JSON file containing its configuration
- several layers in tar format. Each of these is created by a Docker instruction in the Dockerfile (i.e. RUN, COPY...).
With this knowledge in mind, it is possible to reduce the amount of data to be processed when searching for secrets. As the number of tags varies greatly from one repository to another (up to 2000 for a particularly large repository), only a maximum of 5 were retrieved per repository. This corresponds to over 90% of repositories, and limits the number of manifests to be analyzed to 14,722,797.
These configuration files provide a direct and convenient mapping between a layer and the corresponding Docker instruction. Overall, this dataset contains 200 million instructions, for a total size of 4.8PB for all layers. Once again, you'll have to make an informed choice if you hope to detect any secrets.
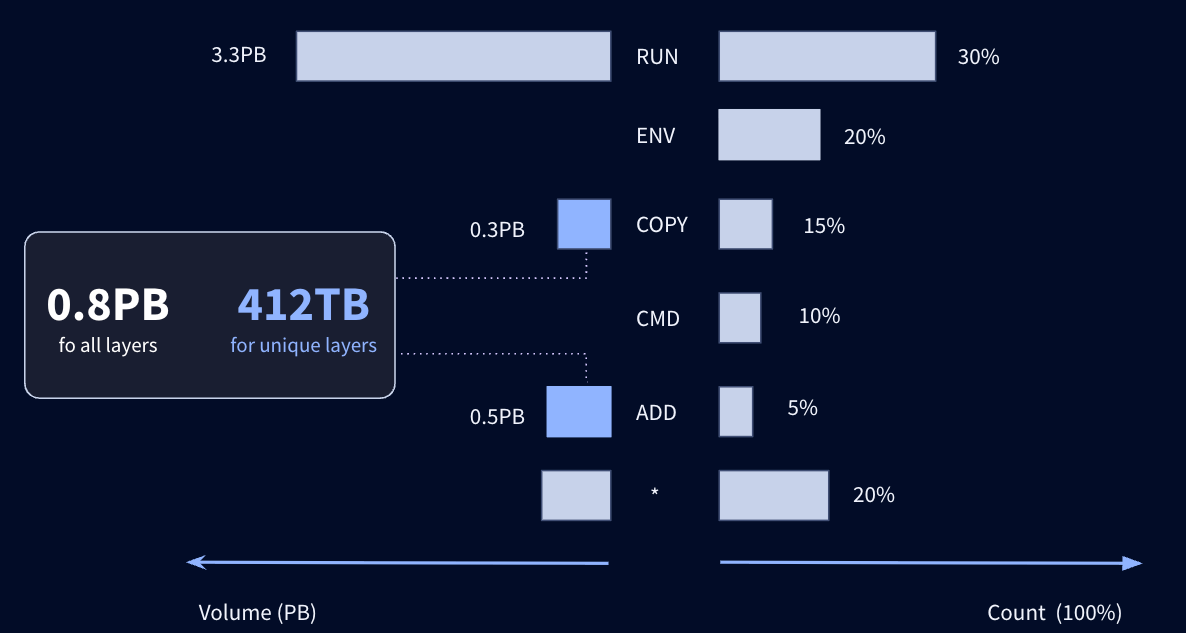
These instructions have been classified by type. RUN, ADD, and COPY alone account for 50% of the layers and 85% of the total volume. Some instructions, such as ENV and WORKDIR, do not create a layer, but only help to configure the image. Subsequently, in order to limit the volume of data to be analyzed, only layers created by COPY and ADD instructions will be taken into account. We focused on COPY and ADD instructions because they are commonly used to import external data into the image. This reduces the noise from other instructions like RUN, which can add non meaningful files such as Ubuntu packages.
This is an acceptable compromise based on the assumption that external data is imported into the image using these two instructions. Of course, RUN instructions can also import files, e.g. source code using git clone, but they also add noisy files such as packages installed with apt on Debian-based systems. In addition, it's worth noting that hard-coded secrets, such as GitHub tokens, used in RUN instructions, can generally be detected when manifest files are analyzed, further reinforcing the relevance of this compromise.
Focusing on the 39 million layers created by ADD and COPY instructions remains a real challenge. Deduplication of these layers on the basis of their SHA256 hashes considerably reduces their number to 18 million, but the overall size of 412 TB remains impractical. To further reduce this volume, we need to examine the size of the layers, which varies considerably from one to another. Some are tiny, while others, which store Machine Learning models, reach 150 GB. Interestingly, these large layers don't necessarily contain interesting secrets. Smaller layers are the majority, with 90% of them less than 45 MB in size; that's 16 million layers to download for a corresponding storage space of 50 TB.
Given the volume of data to be downloaded in order to detect secrets, several IP addresses were used in parallel, and only files containing at least one secret were retained. This represents 300 GB of compressed data after scanning.
The scan took around 3 weeks and was carried out using Git guardian secrets detection engine that powers ggshield (https://github.com/GitGuardian/ggshield). Only certain MIME types, mainly corresponding to text files, were analyzed.
Analysis of Secrets Discovered
A total of 1,2 million unique secrets were detected, 99% of which were only present in layers, most of which are less than 15 MB in size. This is a significant result that reinforces the need to scan Docker images in detail and shows that configuration analysis is not enough. This represents 3 million images containing at least one secret.
As far as secrets detected in manifests are concerned, ENV, RUN & ARG instructions are responsible for 78% of secret leaks; ENV alone accounts for 65%.
Having detected so many secrets, it's time to look at their nature and validate them. This is a complex exercise, but nonetheless a useful one when it comes to measuring their potential impact. At GitGuardian, our secret detectors are able to identify well-known key patterns, and automatically validate them against their corresponding services and providers
Here, we automatically checked 500,000 secrets and found 100,000 of them to be valid; 97% of which are only present in layers, and account for 170,000 Docker images. They are of very different natures and provide access to databases, AWS infrastructures, GitHub Enterprise instances, and Artifactory repositories. This represents 170,000 Docker images.
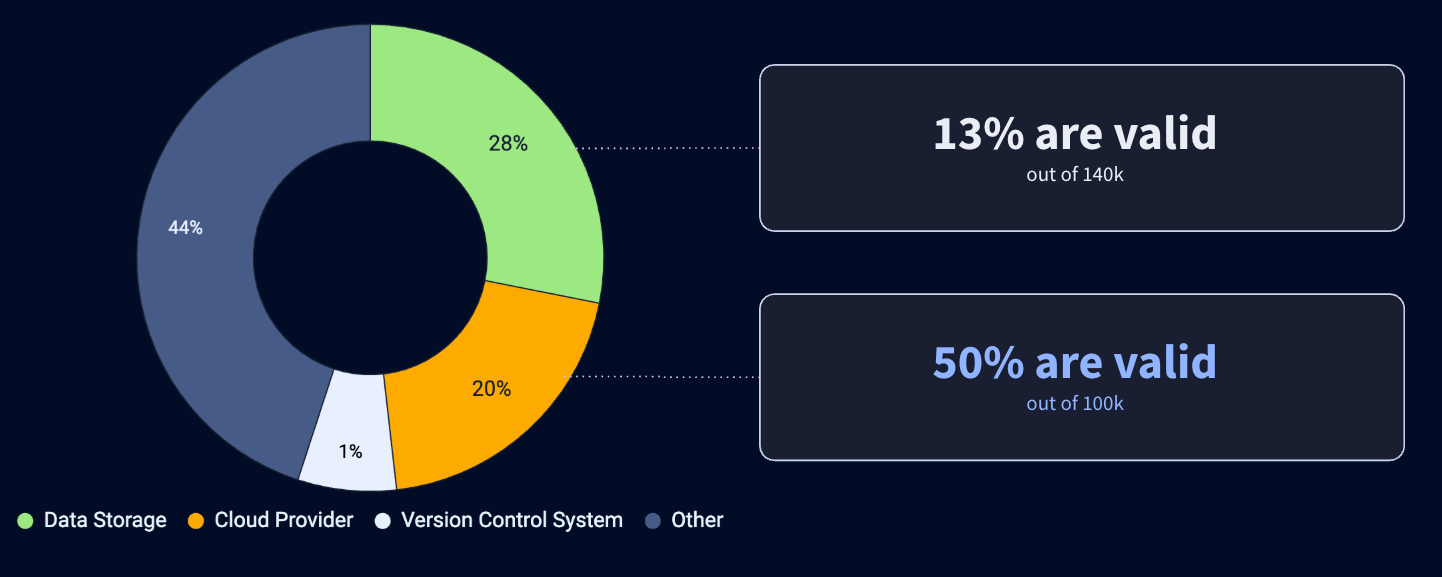
Beyond the numbers and enumerations, it's interesting to note that the nature of valid secrets is very different from that of other data sources. GitHub detects some secrets in commits and notifies key partners such as Microsoft and OpenAI. As a result, apart from detection bias, few of these partners' secrets remain valid for long after they have been made public on GitHub. This is not the case on DockerHub, where over 7,000 valid AWS keys have been identified.
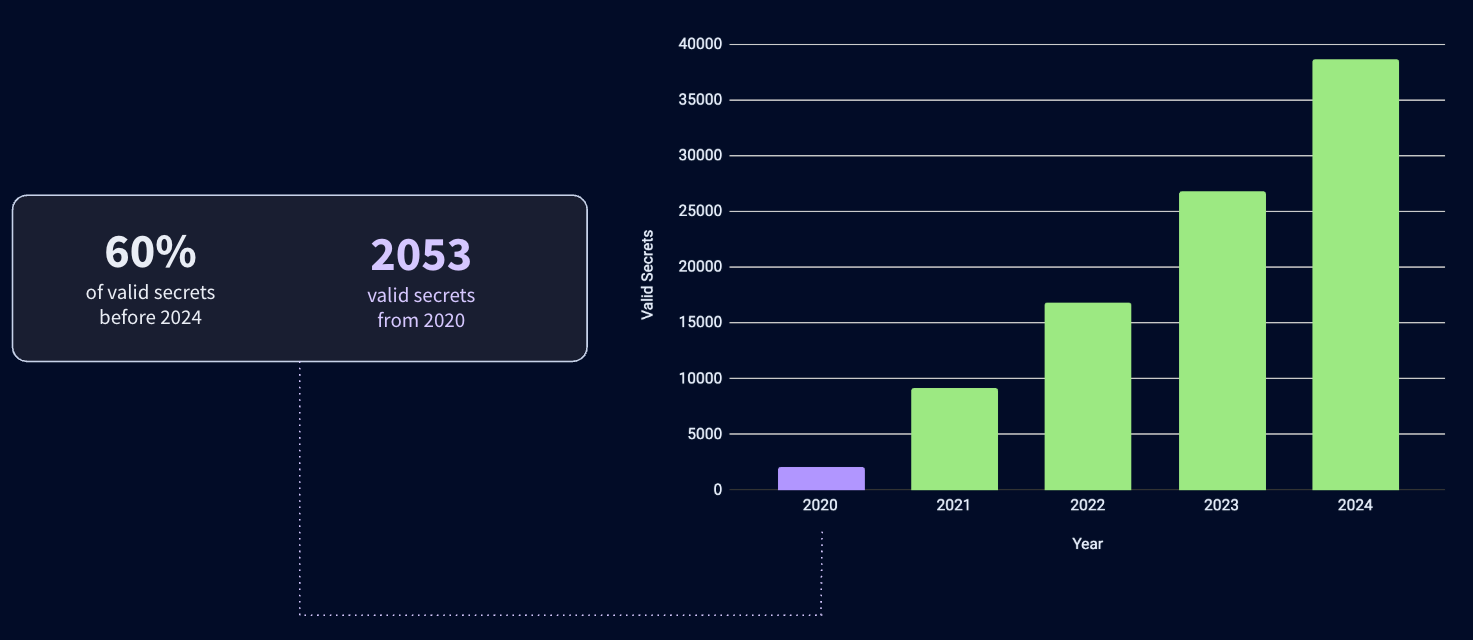
A significant finding emerged regarding the longevity of valid secrets. Surprisingly, 60% of these valid secrets were created before 2024, indicating a persistent security risk. Digging deeper, we discovered 2053 valid secrets that trace back to 2020. This paints a clear picture: secrets are often left unattended and unrotated, potentially exposing systems to vulnerabilities for years. It's not just about detecting secrets, but also about ensuring they don't outlive their intended lifespan and become liabilities in your infrastructure.
Takeaways
The findings from analyzing millions of Docker images reveal a concerning reality: many organizations are likely unknowingly leaking secrets. These exposures stem from a variety of Docker build pitfalls, including persistent layers and leaking build arguments.
It’s crucial to understand that attackers actively target Docker registries for secrets, making regular audits of your images an essential security practice. Prioritizing secret leak prevention is significantly more cost-effective than responding to a breach, and tools are available to help with this process.
Want to go deeper ? Explore our blog for more best practices on handling secrets in Docker to avoid common pitfalls.





