

Generic secrets are hard to detect and are getting leaked more often. See how GitGuardian offers advanced protection where GitHub's push protection falls short.
The landscape of credential security has shifted dramatically in recent years, with a notable transformation in both the volume and nature of secrets embedded in code. According to GitGuardian's 2025 State of Secrets Sprawl report, a staggering 23.7 million new hardcoded secrets were added to public GitHub repositories in 2024 alone—marking a 25% increase from the previous year. More significantly, 58% of these secrets were classified as "generic," up from 49% in 2023, representing the fastest-growing and most challenging category of credential leaks.
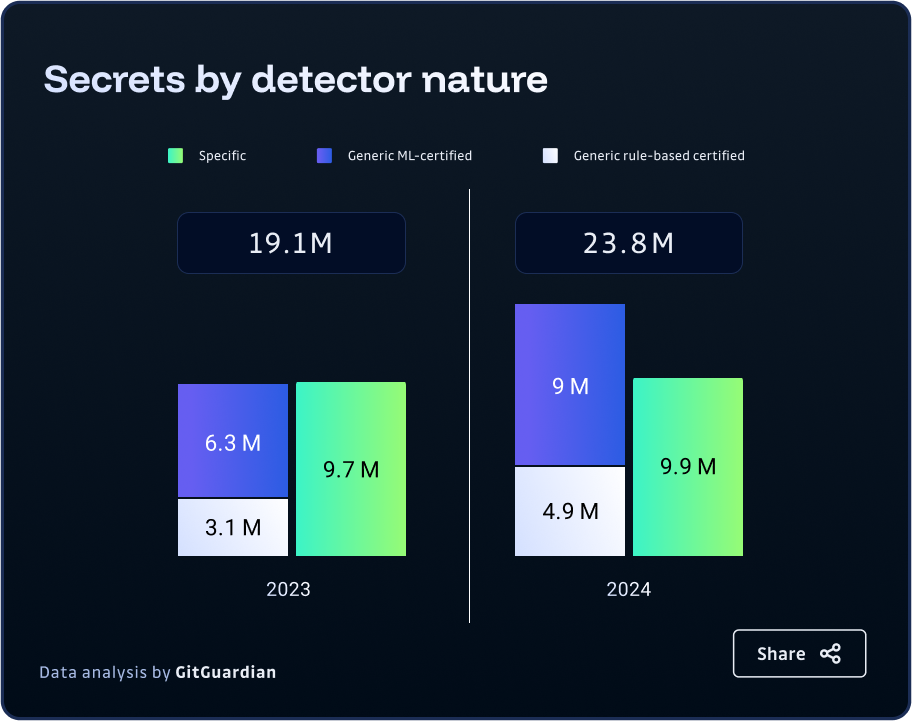
Generic secrets, including database connection strings, custom authentication tokens, encryption keys, and basic username/password combinations, lack the standardized patterns that make specific API keys easily identifiable. This fundamental difference has created a significant blind spot in traditional security approaches, leaving organizations vulnerable.
Let's take a look at why this problem is so pervasive and what we can do about it.
Understanding Generic Secrets: The Detection Challenge
GitGuardian's secrets detectors fall into two categories: specific and generic. Specific detectors are those that we have mapped to known services and providers. These specific secrets follow recognizable formats, such as AWS keys or GitHub OAuth tokens, or have consistent prefixes, like "sk-" which is the standard for OpenAI keys, or "ghu_" used by GitHub. Our specific detectors find some credentials because the context gives clear hints of the provider, even if the pattern is not standardized. GitGuardian has built 439 such detectors so far, and we are building more all the time.
Secrets that are not mapped to a specific, known provider or service we refer to as a "generic." This broad definition accounts for any services we have not heard of yet, including internal APIs, brand-new SaaS offerings, and other non-human identities being created where there is no direct pattern in standard use.
For example, a custom database connection string might be structured in multiple ways depending on the database type, configuration preferences, and organizational conventions. Authentication tokens for bespoke internal services can follow any arbitrary format an organization chooses to implement.
Contextual Dependency
The validity of a generic secret depends entirely on its surrounding context within the code. The same string that might be a legitimate secret in one context could be completely innocuous in another. This contextual dependency requires a detection system to understand not just string patterns but code semantics and structure.
Consider a simple example: the string "root:password123" might be a legitimate database credential when found in a configuration file, but the same string could appear as example text in documentation or test cases where it poses no security risk. Distinguishing between these scenarios requires a semantic understanding of the code's purpose and context.
False Positive Challenges
The broad nature of generic secrets makes them prone to false positives when using conventional detection methods. Without intelligent filtering, attempts to catch generic secrets would flag numerous non-sensitive strings, such as UUIDs, hashes, test data, or placeholder values. This signal-to-noise problem creates a difficult trade-off: set detection parameters too broadly and overwhelm teams with false positives, or set them too narrowly and miss critical vulnerabilities.
What's Driving the Proliferation of Generic Secrets
The increasing prevalence of generic secrets in code repositories is driven by several converging factors in modern software development practices:
Proliferation of Custom and Internal APIs
The explosive growth of microservices architecture has led to a dramatic increase in the number of internal APIs within organizations. Unlike public APIs from major service providers, these internal APIs often use custom authentication schemes with organization-specific credential formats. As companies build more internal tools and services, the volume of these custom, non-standardized secrets inevitably increases.
Increased Developer Autonomy and Varied Practices
Modern development practices emphasize developer autonomy and flexibility, allowing teams to select the tools and approaches that best suit their specific needs. While this autonomy accelerates innovation, it also leads to inconsistent credential management practices across different teams within the same organization. Without centralized standards for credential formats and storage, individual developers or teams may implement ad-hoc solutions that generate diverse credential types.
This variability makes it extremely difficult to establish comprehensive detection rules that would catch all potential secret formats without generating excessive false positives.
The Impact of AI-Assisted Development
The rise of AI code assistants has inadvertently contributed to the generic secrets problem. According to our research, the use of AI coding assistants increases the secrets incidence rate by approximately 40%. Code suggestions may include credential handling patterns copied from training data that don't adhere to best practices. For example, AI assistants may generate placeholder credentials that developers subsequently replace with real values instead of correctly calling secret management tools.

Understanding GitHub Secret Protection: Core Components and Capabilities
GitHub secret protection encompasses a comprehensive suite of security features designed to prevent credential exposure across the development lifecycle. The system operates through two primary mechanisms: secret scanning for detection and push protection for prevention. Secret scanning continuously monitors repositories, issues, discussions, and pull requests for exposed credentials, while push protection acts as a real-time barrier that blocks commits containing secrets before they reach the repository.
The platform's detection capabilities extend beyond traditional pattern matching through GitHub Copilot integration, which leverages AI to identify elusive secrets like passwords that conventional detectors often miss. This multi-layered approach addresses both historical vulnerabilities through retroactive scanning and future risks through proactive blocking. GitHub's partnership with over 150 industry providers ensures comprehensive coverage of service-specific token formats, while validity checks help security teams prioritize active threats over expired credentials.
For organizations implementing github secret scanning push protection, the system provides configurable policies including delegated bypass permissions, alert dismissal restrictions, and automated enablement across repositories, enabling standardized enforcement at enterprise scale.
Setting Up GitHub Secret Protection: Implementation Best Practices
Implementing effective github secret push protection requires a strategic approach that balances security enforcement with developer productivity. Organizations should begin by enabling push protection across all repositories, starting with public repositories where it's enabled by default, then extending coverage to private repositories based on risk assessment.
The configuration process involves establishing clear bypass policies that allow authorized personnel to override protection when legitimate business needs arise, while maintaining audit trails for compliance purposes. Security teams should configure alert routing to ensure detected secrets reach the appropriate response teams promptly, and establish clear remediation workflows that guide developers through secure credential replacement procedures.
Critical implementation considerations include setting appropriate detection thresholds to minimize false positives while maintaining comprehensive coverage, integrating with existing secrets management infrastructure to provide developers with secure alternatives, and establishing regular review cycles to assess detection effectiveness. Organizations should also implement complementary pre-commit scanning using tools like ggshield to catch secrets before they enter Git history, creating multiple layers of protection that address the limitations of push-time detection alone.
GitHub's Push Protection: A Step Forward with Limitations
In February 2024, GitHub took a significant step toward enhancing open-source security by enabling push protection by default for all public repositories. This proactive measure aims to prevent the accidental exposure of secrets by scanning code for known credential patterns before 'git push' operations are accepted.
Benefits of GitHub's Push Protection
Push protection offers several compelling advantages in the fight against credential exposure:
- Preventative Security: Push protection acts as a frontline defense by scanning code at the time of push, catching potential issues before they enter a shared repository. The commits with the secret will still exist locally but is prevented from entering the shared repo.
- Immediate Feedback: Developers receive instant notifications if a potential secret is detected, allowing for quick remediation and reducing the likelihood of sensitive information exposure.
- Reduced Risk: By blocking commits containing sensitive information, push protection significantly reduces the risk of accidental data leaks that could lead to unauthorized access to infrastructure, services, and data.
- Integration Capabilities: Push protection can be integrated into CI/CD pipelines, ensuring that every push is scanned for secrets before deployment, adding an extra layer of security to DevOps practices.
Key Limitations for Generic Secret Detection
Despite its benefits, GitHub's push protection has important limitations when it comes to detecting generic secrets:
- Limited Coverage of Generic Patterns: GitHub's secrets scanning works with approximately 254 token types, of which only 97 have push protection enabled. By embracing a specific detector-only approach, we know that this service is never going to be able to address the much broader category of generic secrets fully.
- Pattern-Based Detection Limitations: The effectiveness of push protection varies significantly depending on the secret type. While it has successfully reduced leaks of credentials with consistent prefixes (like OpenAI's 'sk-' and GitHub App's 'ghu_' keys), it has shown limited impact on credentials lacking standardized prefixes, such as MySQL and MongoDB credentials. There is also a gap for any legacy tokens.
- No Contextual Understanding: GitHub's solution relies primarily on pattern matching rather than semantic code understanding, making it ineffective for detecting secrets that depend heavily on context for proper identification.
- No Historical Detection: Push protection is a real-time detection mechanism that cannot detect secrets hardcoded in the past. GitGuardian's research indicates that 70% of valid secrets detected in public repositories in 2022 remain active today.
- Push Size Limitation: The feature imposes a size limit, typically processing for up to 5 seconds before timing out. If a push exceeds this threshold, scans may be missed, allowing secrets to slip through during large pushes. Pushes larger than 50MB are skipped (50 MB is enormous, but it can happen, for example, when you push existing repositories if you move the repo from GitLab to GitHub.
Addressing GitHub Secret Protection Limitations in Enterprise Environments
While GitHub's native secret protection provides valuable baseline security, enterprise environments often require additional capabilities to address comprehensive secrets management challenges. The platform's 50MB push size limitation can create blind spots during large repository migrations or bulk updates, potentially allowing secrets to bypass detection during critical operations.
The system's focus on specific token patterns, covering approximately 254 token types with only 97 having push protection enabled, leaves significant gaps in detecting custom authentication schemes and internal API credentials commonly used in enterprise microservices architectures. Additionally, the real-time-only detection approach means historical secrets embedded in existing codebases remain unaddressed, creating persistent security vulnerabilities.
Enterprise organizations should complement GitHub's protection with comprehensive secrets management strategies that include vault-based credential storage, dynamic secret generation, and encrypted GitOps approaches with decryption keys stored securely. As noted in GitGuardian's research, striking the right balance between security and accessibility is crucial—overly restrictive systems often lead to protective layer bypassing and increased hardcoding practices. Organizations must implement solutions that provide developers with convenient, secure alternatives while maintaining robust detection and prevention capabilities across their entire development ecosystem.
Advanced Protection with GitGuardian: Tackling the Generic Secrets Challenge
While GitHub's push protection offers a valuable baseline level of security, GitGuardian provides a more comprehensive approach specifically designed to address the challenge of generic secrets through advanced machine learning and contextual analysis.
ML-Powered Generic Secret Detection
GitGuardian has developed sophisticated machine learning models that revolutionize the detection of generic secrets while minimizing false positives. We call it FP Remover. This advanced ML model has reduced false positives by an impressive 80%, enabling security teams to focus on genuine threats rather than being overwhelmed by false alarms. The model uses transformer architecture to understand code semantics and context, identifying patterns that commonly trigger false positives while maintaining near-100% precision.
Pre-commit Protection for Frictionless Security
GitGuardian addresses one of the fundamental limitations of GitHub's push protection by introducing security at the pre-commit stage. By using ggshield or the GitGuardian VSCode extension, developers can detect secrets before they enter the Git history, eliminating the need for complex history rewrites when secrets are discovered. Developers can integrate these guardrails with little effort and in a non-blocking way, meeting them where they are.
Comprehensive Historical Scanning
While GitHub's push protection only scans new commits as they occur, GitGuardian automatically performs historical scans of repositories when integrated with your sources.
This ensures that secrets hardcoded in the past don't remain as vulnerabilities—a critical gap in GitHub's real-time-only detection approach.
Historical scanning is particularly important given GitGuardian's finding that 70% of valid secrets detected in public repositories in 2022 remain active today, representing a significant ongoing risk despite push protection measures.
Unlike GitHub's push protection, which primarily focuses on specific, easily identifiable secrets, GitGuardian's detection engine covers both specific and generic secrets. With over 450 detectors compared to GitHub's 254 (of which only 97 have push protection), GitGuardian offers significantly broader coverage that addresses the fastest-growing category of credential leaks.
Conclusion: A Comprehensive Approach to Secret Detection
As the landscape of secrets sprawl continues to evolve, with generic secrets now representing the majority of credential leaks, organizations need to adopt a multi-layered approach to security that addresses both specific and generic credential types.
The growing prevalence of generic secrets—driven by the proliferation of custom APIs, increased developer autonomy, and the rise of AI-assisted development—requires more sophisticated detection approaches that go beyond simple pattern matching. Machine learning-powered solutions that understand code semantics and context, such as those offered by GitGuardian, provide the necessary capabilities to address this evolving threat landscape.
We would love to work with you to improve your posture around secrets security, especially in a world of exponential growth of machine identities and agentic AI. We would be glad to help you build a free baseline for the secrets that have already been pushed and give you some real insight into the realities of your situation. Let's get a handle on the issues of securing secrets of non-human identities at scale sooner than later.
FAQ
What are generic secrets, and why are they challenging to detect?
Generic secrets are credentials such as database connection strings, custom tokens, and internal API keys that lack standardized patterns. Their detection is challenging because they depend heavily on code context and can appear in arbitrary formats, making them prone to both false positives and false negatives with traditional pattern-based scanning.
How does GitHub secret protection handle generic secrets?
GitHub secret protection primarily relies on pattern-based detection for known token types, with push protection enabled for a subset of these. While effective for standardized secrets, this approach has limited coverage for generic secrets, which often lack identifiable patterns and require contextual analysis for accurate detection.
What limitations should enterprises be aware of when relying solely on GitHub secret protection?
Enterprises should note that GitHub secret protection has push size limits (50MB), covers only around 254 token types (with push protection on 97), and lacks historical scanning. This leaves gaps for custom secrets, large repository pushes, and legacy credentials, requiring supplemental solutions for comprehensive coverage.
How does GitGuardian enhance detection of generic secrets compared to GitHub?
GitGuardian employs advanced machine learning models that analyze code semantics and context, significantly reducing false positives when detecting generic secrets. Its solution includes pre-commit scanning, historical repository analysis, and broader detector coverage, addressing the limitations of pattern-only approaches.
Why is pre-commit scanning important for secrets management?
Pre-commit scanning intercepts secrets before they enter Git history, preventing exposure at the earliest stage. This reduces remediation complexity, avoids history rewrites, and ensures that sensitive data never reaches shared repositories, strengthening overall secrets management posture.
What best practices should organizations follow when implementing GitHub secret protection?
Organizations should enable push protection across all repositories, configure bypass and alert policies, integrate with secrets management tools, and supplement with pre-commit scanning. Regularly reviewing detection effectiveness and ensuring developer-friendly workflows are key to minimizing risk and maintaining productivity.









