

Worried about GitHub Copilot’s security and privacy concerns? Learn about potential risks and best practices to protect yourself and your organization while leveraging AI.
AI-powered code completion tools like GitHub Copilot, co-developed by GitHub and OpenAI, likely need no introduction. Developers are rapidly embracing this evolving technology to aid them in their work. Copilot and other Large Language Model (LLM) based coding assistants suggest lines of code and entire functions, saving a lot of time looking up specific formulations or helping scaffold common structures in the code. It is also great for helping a team write documentation.
However, is Copilot secure? As beneficial as it may be, it also comes with significant security and privacy concerns that individual developers and organizations must be aware of. As Frank Herbert put it in "God Emperor of Dune" (the 4th book in the Dune saga):
"What do such machines really do? They increase the number of things we can do without thinking. Things we do without thinking–there's the real danger."
The first step in protecting yourself and your team is to understand the pitfalls to avoid as we leverage these handy tools to help us all work more efficiently.
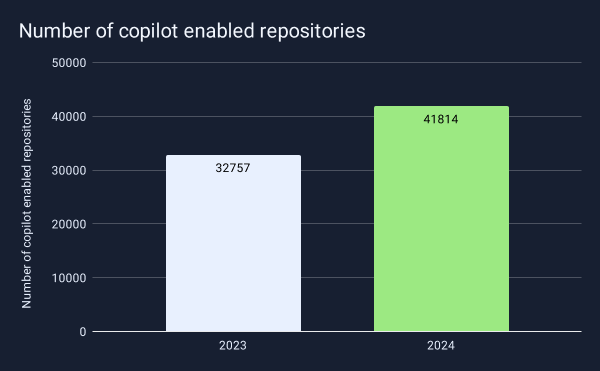
2024 confirmed the progression of AI-powered development tools across all industries. Application development has followed this trend to the point where GitHub now offers Copilot as part of its free offering. Between 2023 and 2024, the number of repositories using Copilot increased by 27%, indicating developers are increasingly relying on AI tools to improve their productivity. This rapid adoption makes understanding the security implications even more critical.
How GitHub Copilot is trained
To better understand what to guard against, it is important to remember how data ends up in these LLMs. GitHub Copilot ingests a large amount of training data from a wide variety of sources. This is the data it is referencing as it answers user prompts. These training sources include all public GitHub repositories' code and, essentially, the whole of the public internet.
Importantly, Copilot also learns from the prompts users input when asking questions. If you copy/paste code or data into any public LLM, you are encouraging the AI to share your work. For open-source projects or public information, there is not a lot of danger here on the surface, as it has likely trained on this already. But here is where the danger really starts for internal and private code and data.
Security concerns with GitHub Copilot
Here are just a few of the issues to be aware of and to watch out for as you leverage any code assist tool in your development workflow.
Potential Leakage of secrets and private code
GitHub Copilot may suggest code snippets that contain sensitive information, including keys to your data and machine resources. This is at the top of our list as it means an attacker can potentially leverage Copilot to gain an initial foothold.
While some safeguards are in place, clever prompt rewording can yield suggestions that contain valid credentials. This is a very attractive path for attackers looking for ways to gain access for malicious purposes.
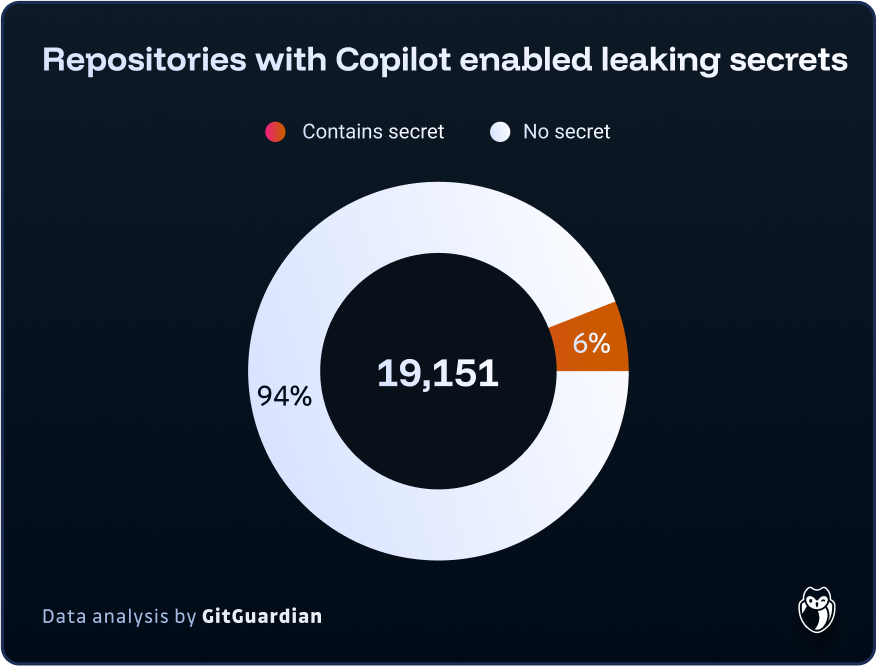
Recent research by GitGuardian quantifies these concerns. In a sample of approximately 20,000 repositories where Copilot is active, over 1,200 leaked at least one secret—representing 6.4% of the sampled repositories. This incidence rate is 40% higher than what was observed across all public repositories, which stands at 4.6%. This disparity can be attributed to two factors: first, the code generated by Large Language Models (LLMs) may inherently contain more security vulnerabilities; second, and perhaps more significantly, the use of coding assistants may be pushing developers to prioritize productivity over code quality and security. Despite the continuous improvement of coding assistants, this data underscores the ongoing need for robust security controls, particularly in the area of secret detection.
Attackers are also looking for clues about your applications and environments. If they learn you are using an outdated version of some software, especially a component in your application with a known, easily exploited flaw, then that is likely an attack path they will attempt to exploit. While more time-consuming to execute than using a discovered API key, this is still a serious concern for any enterprise.
Insecure Code Suggestions
While we would love to say ChatGPT and Copilot only ever suggest completely secure code and configurations, the reality is the suggestions will only ever be as good as the data they are trained on. By definition, Copilot is an average of all developers' shared work. Unfortunately, all the security failings added to all known public codebases are part of the corpus on which it bases its suggestions.
The data it is trained on is also aging rapidly and can't keep up with the latest advances in threats and vulnerabilities. Code that would have been fine even a couple of years ago, thanks to new CVEs and new attack techniques, is sometimes just not up to modern challenges.
Poisoned data can mean malicious code
Recently, a research team uncovered a method of injecting hard-to-detect malicious code samples used to poison code-completion AI assistants to suggest vulnerable code. Attackers working to lure developers into using purposefully insecure code is not a new phenomenon, but attackers are coming to rely on developers simply trusting the code suggestions from their friendly Copilot and not overly scrutinizing it for security holes. On the other hand, finding and using a random code sample on StackOverflow would likely give every developer pause, especially if heavily downvoted.
Package Hallucination Squatting
One of the more disturbing problems across all AIs is that they simply make things up. When asking trivial questions, these hallucinations can be rather entertaining at times. When writing code, this issue can be rather annoying and, increasingly, rather dangerous.
In the best of scenarios, the package that Copilot suggests simply does not exist, and you will need to find an alternative. This pulls you out of your flow and wastes your time. One researcher reported that as much as 30% of all packages suggested by ChatGPT were hallucinated.
Attackers are well aware of this issue and have begun leveraging it to find commonly suggested hallucinations and register those packages themselves. The most clever of them will clone similar packages that perform the functionality Copilot describes and then hide malicious code within, counting on the developer not to look too closely. This practice is similar to typosquatting; hence, the security community has dubbed this issue "hallucination squatting."
Lack of Attribution and Licensing
One of the more commonly overlooked issues with code suggested by any LLM is understanding the licensing of suggested code. When Copilot generates code, it does not always provide clear attribution to the original source. This does not pose an issue for permissive licenses like Apache or MIT. But what if you inject a copyleft-licensed bit of code, such as the GPL, which demands that the inclusion of this code makes the entire codebase open-source? What do your legal and compliance teams say about this? If you doubt whether you can include the code, it should likely be left out of your project.
Privacy Concerns with GitHub Copilot
In addition to the security concerns we have already covered, privacy is another class of concern to be addressed. Privacy laws differ between jurisdictions, but these issues affect our users, the very folks we want to work to keep safe.
Sharing private code
As mentioned before, GitHub Copilot collects data on user interactions, including the code that users write and how users respond to the suggestions it generates. While the goal is to help refine the model and give everyone a better experience, for developers working on sensitive or proprietary projects, it raises some very serious privacy concerns. Your organization may not want its code or development practices to be analyzed or stored by GitHub, even if it is for improving AI performance.
Retention of User Data
The community has many questions about how long LLMs retain user data, how it is stored, and what specifically is in there. Companies go to great lengths to secure user data and keep it safe. Using real data to build a query is a temptation for developers, especially if you can just upload a .zip folder and ask AI to generate the needed code to run analytics or transform it for another use. Sharing this data might also directly violate regulations like GDPR or CCPA.
Using GitHub Copilot safely
Despite all these concerns, GitHub Copilot can still be a very valuable tool if used cautiously. Here are our suggestions for avoiding these common security and privacy risks.
Review Code Suggestions Carefully
Just as you would probably not run random, untested code, even locally, you should scrutinize any suggested code from Copilot or any other AI assist tool. Remember to treat Copilot's suggestions as—suggestions. Read what is there carefully to see if it makes sense and with the intent to use it as a learning tool. We encourage you to always check if the suggested code lives up to your organization’s coding standards and security guidelines. Always remember it is your responsibility once the code is pushed.
Avoid using any secrets in your code
Acknowledging that, according to their documentation, GitHub Copilot for Business does not train on your private code, it’s still crucial not to share your secrets anywhere if possible. You might think it would be hard or intentional to copy/paste your credentials into an AI-assist tool. However, if you have integrated Copilot into your IDE or editor, it is always reading your code and trying to anticipate what you need next. The only true way to prevent any secrets from leaking into a code assist tool, or anywhere else, is to eliminate any plaintext credentials from the code.
Finding and helping teams eliminate secrets is exactly what the GitGuardian Secrets Detection Platform has been helping teams accomplish for years. While there are multiple approaches to how to best store and access secrets securely, the first step is to identify what secrets exist and plan your course of action to eliminate them.
Developers can leverage ggshield, the GitGuardian CLI, and pre-commit hooks to check for hardcoded secrets as they try to commit the code–before it can ever reach production. If they are leveraging Visual Studio Code, the GitGuardian VSCode extension can help them catch any plaintext credentials as they save the file.
Tune your Copilot privacy settings
GitHub provides settings that allow users to control some aspects of data sharing with Copilot. Review and configure these settings to minimize data sharing where possible, especially in environments where privacy is a significant concern.
Train developers on Security Best Practices
Developers are on the front lines, delivering features and applications at an ever-increasing rate. We must work to ensure that any developer using Copilot is aware of the threats and trained on your organization's security best practices. Developers, especially less experienced developers, need to understand the potential risks of relying too heavily on AI-generated code.
We need to find a balance, though, and not simply discourage all use of Copilot, as AI assist tools are not going away and are only likely to gain wider adoption in the near future. Security needs to get away from being the 'department of no,' needing to become known as the team that empowers developers to work more safely and efficiently overall.
Good Copilot practices are good code practices
GitHub Copilot is an increasingly valuable tool that can significantly speed up the coding experience and reduce some of the toil developers face daily. We need to remember it is not without its security and privacy challenges. Developers and organizations need to deliberate on how they adopt and use Copilot. As with any new technology, the key lies in balancing the benefits with the potential drawbacks, making informed decisions, and prioritizing security and privacy at every step.
Like with any code, you should always be careful not to include sensitive information, like customer data or plaintext credentials in your prompts. This is especially true when leveraging public LLMS.
No matter where it originated, teams should take steps to review and scan AI-generated suggestions to find issues before the code is committed. GitGuardian is here to help with our Secrets Detection.

GitHub Copilot Data Privacy Settings: A Comprehensive Configuration Guide
Understanding and properly configuring GitHub Copilot's data privacy settings is crucial for organizations concerned about code exposure and intellectual property protection. GitHub provides granular controls that allow administrators to manage how Copilot interacts with proprietary code and sensitive development practices.
For GitHub Copilot Business and Enterprise users, the most critical setting is the "Allow or block suggestions matching public code" toggle, which prevents Copilot from suggesting code snippets that closely match publicly available repositories. Organizations should also configure the "Block suggestions matching public code" filter to minimize the risk of inadvertently incorporating licensed code without proper attribution.
Enterprise administrators can implement organization-wide policies through the GitHub Enterprise settings panel, including disabling telemetry collection and restricting Copilot's access to specific repositories containing sensitive intellectual property. The "Content exclusion" feature allows teams to specify file patterns and directories that should never be processed by Copilot, providing an additional layer of protection for configuration files, deployment scripts, and other sensitive assets that might contain infrastructure details or proprietary business logic.
GitHub Copilot Enterprise Privacy: Advanced Governance for Large Organizations
GitHub Copilot Enterprise privacy controls extend beyond individual user settings to provide comprehensive governance frameworks for large-scale deployments. Enterprise customers gain access to advanced audit logging capabilities that track all Copilot interactions, including prompt submissions, code suggestions accepted or rejected, and user engagement patterns across the organization.
The Enterprise tier introduces "Private model customization," allowing organizations to fine-tune Copilot's suggestions based on their internal codebases without exposing proprietary code to GitHub's training pipeline. This feature maintains strict data isolation, ensuring that custom training data remains within the organization's security boundary while still benefiting from AI-powered code assistance.
Enterprise privacy controls also include advanced compliance reporting features that generate detailed logs for SOC 2, ISO 27001, and other regulatory frameworks. Organizations can implement role-based access controls that restrict Copilot usage to specific teams or projects, and configure data residency requirements to ensure that code processing occurs within approved geographic regions. These enterprise-grade privacy features address the complex compliance requirements that large organizations face when adopting AI-powered development tools.
GitHub Copilot Free Privacy: Understanding the Trade-offs
The introduction of GitHub Copilot's free tier has democratized access to AI-powered coding assistance, but users must understand the privacy implications of this offering. Unlike paid tiers, GitHub Copilot free operates with different data handling policies that may impact how user interactions are processed and stored.
Free tier users should be particularly cautious about the types of code they expose to Copilot, as the service may use prompts and interactions to improve the underlying model. While GitHub states that it doesn't train on private repository code for Business and Enterprise customers, the free tier operates under different terms that allow for broader data utilization in model improvement efforts.
Organizations evaluating the free tier should implement strict internal policies prohibiting the use of Copilot free for any proprietary or sensitive code development. Development teams should establish clear guidelines about when to upgrade to paid tiers, particularly when working on projects involving customer data, proprietary algorithms, or regulated industries. The free tier serves as an excellent evaluation tool for open-source projects and learning environments, but production enterprise development should leverage the enhanced privacy protections available in paid offerings.
FAQ
What are the primary security risks associated with GitHub Copilot in enterprise environments?
Key risks include potential leakage of secrets and proprietary code, insecure code suggestions due to outdated or vulnerable training data, and the risk of package hallucination squatting. Attackers may exploit these vectors to gain unauthorized access or introduce malicious code. Rigorous review and automated secrets detection are essential to mitigate these threats.
How does GitHub Copilot privacy differ between free, Business, and Enterprise tiers?
GitHub Copilot privacy controls are more robust in Business and Enterprise tiers, offering features like blocking suggestions matching public code, content exclusion, and audit logging. The free tier may use user interactions for model improvement, so it is not recommended for proprietary or regulated code. Enterprises benefit from advanced governance and compliance features.
Can Copilot suggestions inadvertently introduce licensed or copyleft code into our repositories?
Yes, Copilot may generate code snippets derived from public repositories without clear attribution or license information. This can inadvertently introduce code governed by restrictive licenses, such as GPL, potentially impacting your codebase's compliance status. Organizations should review all AI-generated code for licensing implications before integration.
What best practices should security teams implement to minimize GitHub Copilot privacy and security risks?
Security teams should enforce secrets scanning pre-commit, configure Copilot privacy settings to restrict data sharing, use content exclusion for sensitive files, and provide developer training on secure AI tool usage. Regular audits and leveraging enterprise controls for audit logging and access management are also recommended.
How can organizations configure GitHub Copilot to protect sensitive code and intellectual property?
Administrators should enable "Block suggestions matching public code," use content exclusion for sensitive directories, and restrict Copilot access to approved repositories. Enterprise customers can leverage private model customization and advanced audit logging to maintain strict data governance and compliance with regulatory requirements.
Does GitHub Copilot train on private code, and how does this impact data privacy?
For Business and Enterprise tiers, GitHub Copilot does not train on private code or prompts, maintaining a higher level of data privacy. However, free tier users should be aware that their interactions may be used for model improvement, making it unsuitable for sensitive or proprietary development.
What is package hallucination squatting, and why is it a concern with AI code assistants?
Package hallucination squatting occurs when Copilot or similar tools suggest non-existent packages, which attackers then register with malicious payloads. Developers may inadvertently introduce these into their environments, leading to supply chain compromise. Vigilant package validation and dependency management are critical defenses.







