

At its core, GitOps is code-based infrastructure and operational procedures that rely on git as a version control system. It’s an evolution of Infrastructure as Code (IaC) and a DevOps framework that leverages git as the single source of truth, and control mechanism for creating, updating, and deleting system architecture.
If you are primarily interested in Infrastructure as Code, I recommend you to start with this article: Infrastructure as Code — Everything You Need to Know
Understanding GitOps
With the demands made on today's infrastructure, it's becoming increasingly crucial to implement infrastructure automation. Modern infrastructure needs to be elastic so that it can effectively manage cloud resources that are needed for frequent deployments. The concept of GitOps was first hatched by WeaveWorks, an enterprise Kubernetes management platform, but has since proliferated throughout the DevOps world.
But what does GitOps look like practically and how does it help the development of modern applications?
Alexis Richardson, the CEO of WeaveWorks, says that by implementing a GitOps framework you are able to drastically increase productivity as you transition from deployments once or twice a week, to automated deployments multiple times a day.
“When you deploy more than once a day, you get the feeling of empowerment and control. You're no longer doing things manually, watching things break, having to fix them. You're moving with confidence.” Alexis Richardson
This is powerful because developers no longer need to stop and think about deployment, it frees up development time to spend on what you are really trying to achieve.
In one statement GitOps can be described as:
“The idea that git is a single source of truth for the whole system” Alexis Richardson
This is a really profound statement. It’s not been easy to do this until recently because we have only now created enough declarative infrastructure to be able to describe our whole system and then exposes it in git. But taken to the extreme, once you have your whole system described in git, you can make all changes to your running systems through git. This essentially means you no longer need to use tools like Kubectl for Kubernetes, instead you can control the infrastructure by making pull requests. “Any developer that understands how to do a pull request can also make operational changes which lowers the cost of entry.” By using git to control your infrastructure you benefit from additional aspects of git, such as an audit trail, comments on why changes were made and also it gives you the ability to go back and forwards in time.
“Using GitOps you can do things like blow up your entire system and recover in just minutes.” Alexis Richardson
What is declarative infrastructure?
Declarative infrastructure is at the core of GitOps and is infrastructure controlled by a set of statements that describe the desired state of the infrastructure. This is different from a set of instructions. Below is a config description of a Kubernetes app in a yaml file. The key point here is that this is a set of statements that you can verify and you could use these statements to reproduce a system.
Note: In addition to yaml files, HCL (hashicorp files), are also common filetypes to store declarative infrastructure within for Terraform.
# deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: example-application
spec:
replicas: 3
template:
metadata:
labels:
app: example-application
spec:
containers:
- name: example-application
image: gcr.io/gitops-255005/example-application:master-f7517f2
ports:
- containerPort: 8080
---
Declarative infrastructure including Kubernetes, Terraform, & more can be used for your entire system. This means you can store code, configs, monitoring rules, dashboards all within git, all with a full audit trail that developers can track. The entire running system can be observed and compared to what is described in git. Diff tools can then be implemented to alert when differences occur. This means that anyone in the team that can make a pull request can be productive extremely fast.
“The original devops concept was version control of your config. We are extending that by version controlling everything.”
“We respond to anything from full-on crisis to small change this way.” Alexis Richardson
The 3 Pillars of GitOps
GitOps is built upon three pillars:
- Pipelines
- Observability
- Control.
Control and observability go together, as you see things you can fix them and pipelines are the key to being able to automate your deployment. Everything needs to be joined together, pipelines is how you do this.
Creating pipelines is absolutely key when it comes to effective implementation of a GitOps framework so we will dive into exactly how pipelines work in workflow automation.
GitOps Pillar 1 - Pipelines
Deployments in GitOps are controlled using the operator pattern. This will be something familiar if you have worked with CI/CD in the past.
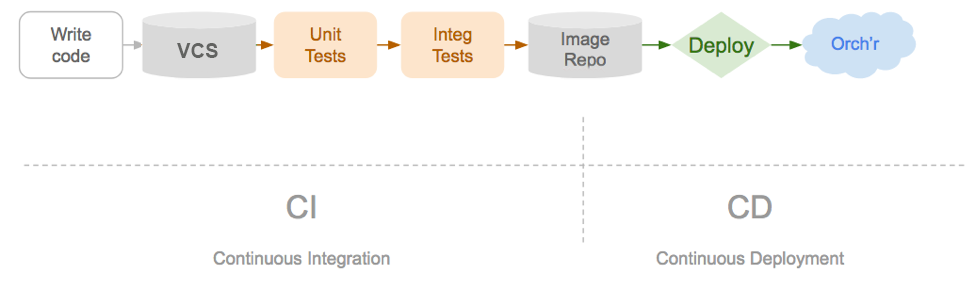
Image from WeaveWorks
The operator is responsible for taking the desired state and making it true for the observed running state. If you have a container and declare you want 100 replicas of that container, the operator is then responsible for driving the cluster towards this. Equally if you are sound asleep and a bunch of nodes disappear and the replica count drops, the operator is then driving that back up.
GitOps uses the same pattern of an operator that observes the desired state inside git.
To make this work, everything has to be inside git. All the config should be treated just like code. Anything that is not recording those changes inside git is effectively harmful to your system because the operator is only driving the observed state towards what you have described in git.
But what does the GitOps repository actually look like?
For this question we are referring to the config repository. This should be a separate repository to your code. The reason it should be kept separated is because if you have some continuous integration triggering on the code, you don’t want changes on the config always triggering a new image. It's also recommended to have one repository per logical application or service. Essentially anything that is tightly coupled together.
Each environment that you have: Staging, Test, Production, or any others, should have its own branch inside the git repository.
All changes that are then made to your infrastructure, you first make them in git. This means each time you make a change, for example bumping up the version number, you would make a pull request, submit it to staging and have it peer reviewed. Finally when it’s ready, you can roll it out to production by simply merging the staging branch to the production branch.
“The benefit of doing it this way, is that even though you are getting code reviewed on the final merge, you have already tested that exact configuration in staging.” William Denniss, Google
Example GitOps Pipeline
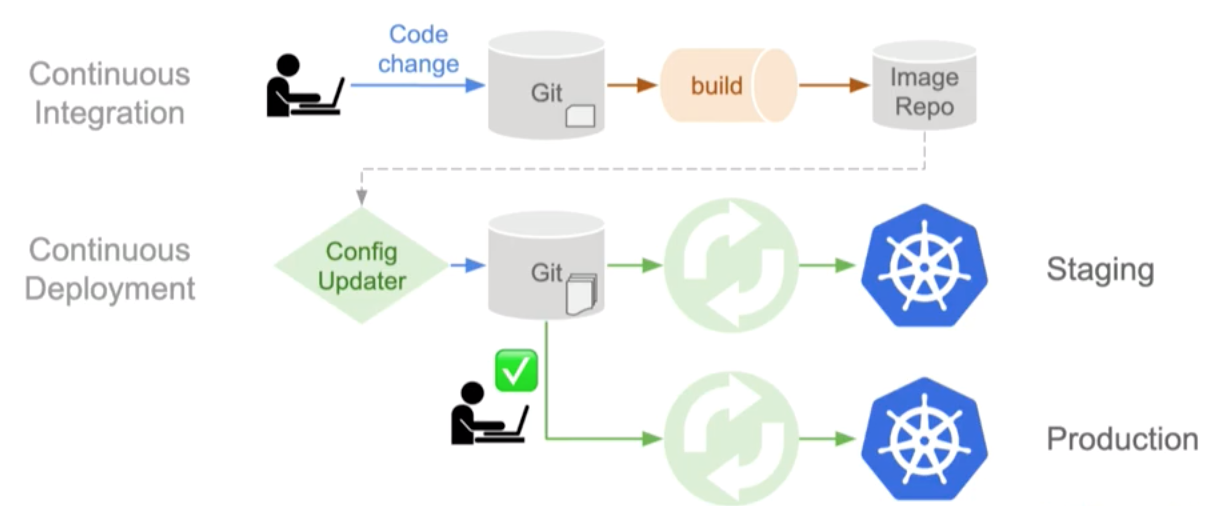
Images from WeaveWorks
Above we can see what the GitOps pipeline looks like:
A developer commits a change, the container builder creates an image uploading it to the image repo. It is at this point many developers add their CD (continuous deployment) but with GitOps, instead with edit our staging configuration in the staging repository. Effectively creating an automatic push. This now means that our current running state is different from what we have described our desired state to be so the operator needs to activate and to be able to make the desired state and the running state equal again. Once the environment in staging is running correctly the very last step is to more the staging configuration branch into the main branch again activating the operator to make the desired and running state match again.
in the above example the operator used is Weave Flux, this is an open source operator that follows this path.
Storing secrets inside git repositories
There is however a big problem when advocating that everything should be stored inside git, that is secrets. Secrets inside git is a well documented security threat and if we are storing everything relating to infrastructure in git, we must also store related secrets inside the repository too. So how do we overcome this?
One of the common options to get around this is encrypting secrets inside the git repository. One such method of doing this is using an awesome open-source project called Sealed secrets by Bitnami. This package previsions a private key into the cluster and then stores a public key that developers can use to encrypt secrets and store them in git just like any other configuration. It then uses its own operator to decrypt these secrets with its private key. This allows you to manage your infrastructure secrets and still store them inside git securely. If you want to take this entire cluster and recreate it, in disaster recovery for example, you can bootstrap it with that one private key and then all other secrets will be pulled in and decrypted.
There is of course other methods of keeping secrets private without asymmetric encryption such as using secret as a service products like Hashicorp Vault. But always be careful, every time you use secrets with git, make sure you have secret scanning in place to alert you if an unencrypted secret enters the repository.
GitOps pillar 2 - Observability
Observability in its simplest is the property of a system that is observable. But it is also shorthand for getting your monitoring tracing and visualization right.
“If your system is not visible you will not be able to see what is happening when something does go wrong.”
Observability in GitOps and deployment can really be boiled down to a great statement from John Arundel.
Observability-driven development: never accept a pull request if you don't have a way to verify that it does what it's supposed to. https://t.co/DNCovCzMmc
— John Arundel (@bitfield) November 1, 2017
You need to have observability at a service level. Meaning anything from UX down to deep diagnostics.
You have to integrate your GitOps pipeline with your tools to observe things. If you do a service push you need to be able to observe the error rate, for example, as it is happening. And the more you adopt policies like canaries and staged deployments, the more important it becomes to see the stage's impact on the system early.
"This is ultimately how you gain confidence in your system and how you are able to go faster and faster to being able to have many deployments on your system a day. " Alexis Richardson
GitOps pillar 3 - Control
Control is the counterpart of observability and goes back to the principle of GitOps, which is to control your system through git, allowing you to have a consistent and correct running system relative to your desired state.
The more things we can describe using yamls the more efficiently we can run and control our system.
Control is convergence. Making sure the desired state and the observed state are the same.

Diff and sync tools which have been mentioned throughout this blog are sometimes crude but very important tools we can use to control convergence.
Once you get the three pillars of GitOps working together, Pipelines, Observability and Control, you will be able to move towards multiple deployments a day drastically increasing productivity and lowering the barrier of entry for developers.
Wrapup
GitOps is the idea that git is the central point of truth for your entire system. It takes the concept of DevOps which is version controlling your config and moves towards version controlling absolutely everything. Using declarative infrastructure, which is infrastructure that can be described and reproduced by a set of true or false states, you can describe all your infrastructure using yaml files inside a git repository. GitOps uses three pillars to increase productivity in your system: pipelines, observability and control.
Pipelines are then used to link up all your systems and operators to ensure that the observed state in the running system equals the desired state as described in git. Storing absolutely everything in git means you have to take extra care when storing secrets making sure they are encrypted using a public key and decrypted using a private key by the running state. Observability is shorthand monitoring and tracing your visualization right and could be boiled down to making sure you never accept a pull request unless you can observe the impact it will have. Finally control is the counterpart of observability and means convergence. Control can be achieved sometimes crudely by very effective tools like diffs which look at the current running state of the infrastructure and compare it to the desired state in git.
If there is a final statement to leave it is this.
Only what can be described and observed can be automated and controlled and accelerated.







