

Since day one, GitGuardian has been dedicated to alerting developers when they inadvertently expose their secrets on GitHub. To achieve this, we've been scanning public GitHub events in real-time for over five years, sending an email whenever we detect something suspicious (this is our Good Samaritan program).
However, to prevent bombarding developers with irrelevant notifications, we needed to be as certain as possible that the flagged code snippet posed a genuine threat to the committer.
For secrets like API keys and access tokens from well-known providers, this is straightforward: they often follow specific patterns or are prefixed with identifiable strings, giving us confidence when sending an alert.
Here's the kicker — those secrets account for less than 40% of all the secrets we uncover.
This means that most leaks don't adhere to a simple, recognizable pattern: they could be username and password combos, random strings for basic auth, bearer tokens, or any kind of sensitive string imaginable. This makes it impossible to raise alerts with confidence—until now!
Recently, the GitGuardian ML team has been rolling out its latest innovation to tackle this long-standing challenge: the confidence scorer. In this blog post, I'm going to introduce the model behind this advancement.
Scaling the Confidence Scorer Model
The confidence scorer is a machine learning model that assigns a score between 0 and 1 to the validity of each secret candidate. This score indicates the likelihood of a code snippet containing an actual secret:

Since the confidence scorer outputs a continuous value between 0 and 1, a threshold must be set to convert the score into a binary classification of 'Secret' or 'Not a Secret.' This threshold determines the trade-off between precision (the fraction of predicted secrets that are actual secrets) and recall (the fraction of actual secrets that are correctly identified). A higher threshold will increase precision but may miss some actual secrets, resulting in lower recall. Conversely, a lower threshold will increase recall but may also incorrectly flag more non-secrets, leading to lower precision and more noise for the developer community.
Striking the Perfect Threshold
To strike a balance between these two metrics, we aimed for a calibrated threshold that would provide very high precision (as close to 100% as possible) while still maintaining a reasonable recall rate. It’s worth noting that a somewhat lower recall is acceptable for this specific detection use case (as these secrets wouldn’t have been caught in the first place).
After evaluating various threshold values, we found that a threshold of 0.9 offered an optimal trade-off, providing high precision while flagging enough secrets to have a meaningful impact on our ability to alert developers about potential security risks.
Our new mechanism is already helping us flag around 1,000 generic leaks per day, enabling us to confidently say, "Hey, looks like your code has an issue." But that's just the beginning: with the help of this scorer, GitGuardian has the potential to triple the number of daily email alerts sent (reaching about 15K) while maintaining an impressive 99% precision!
In the graph below, we can see that the confidence scorer is already responsible for about 15% of the alerts we send:
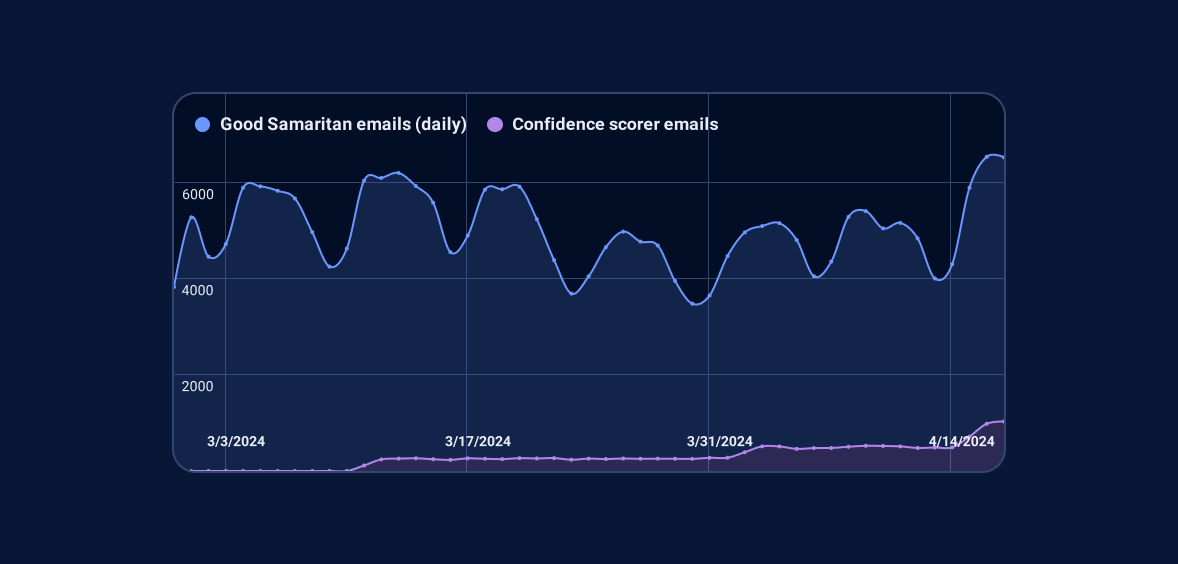
However, scaling this operation is no small feat. LLMs are computationally demanding, with models ranging from hundreds of millions to several billion parameters. As explained in the State of Secrets Sprawl, we scan about 10 million documents per day, or ~116 per second. Assuming a conservative average document size of 500 tokens, this would average out to 3M tokens processed per minute. This volume rules out from the start the hypothesis of using an external service such as OpenAI's GPTs.
Custom LLM Model for Secret Detection
To address this challenge, we decided to use a lightweight LLM model based on an open-source code-LLM carefully selected to balance performance and inference speed. We then fine-tuned this model with a custom classification head, allowing us to focus specifically on detecting secrets in source code. We trained our model using a balanced dataset of 100,000 secrets, including both manually annotated secrets and secrets detected by our internal detection engine, along with a proportion of false positives. By balancing the dataset and having a high diversity of examples, we managed to avoid over-fitting on some specific cases and to make the model generalize on unseen secrets.
We also had to address the issue of inference speed, as large models are notoriously slow. To overcome this, we aimed to minimize the use of the confidence scorer by discarding as many candidates as possible early on.
Fortunately, we already have a very fast and reliable secrets detection engine built over years of careful engineering. By combining the two, we reduce the number of code snippets that need to be analyzed to 300,000 per day. In other words, the model effectively only needs to sift through 300,000 generic secrets daily to isolate those of the highest importance and confidence.
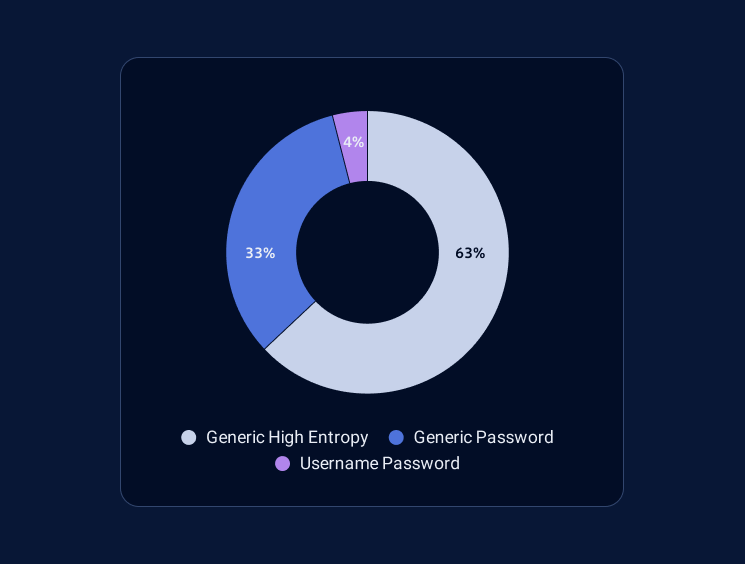
This is the distribution of the types of generic secrets we managed to detect until now:
Successful Deployment and Positive Impact
This powerful mix of probabilistic and deterministic techniques is already showing very good results as it has been smoothly rolled out for detecting secrets on GitHub.com. Our confidence scorer already scores all secrets detected on public GitHub. However, to avoid any noise for the developers receiving an email, we are rolling out the use of this score step by step to monitor the live quality of the email sent. The confidence scorer will allow us to more than double the number of daily email alerts sent.
The most critical KPI we track is the percentage of emails that resulted in a click to “Fix This Secret Leak,” which indicates that we successfully helped the developer acknowledge the vulnerability and begin remediating the issue.
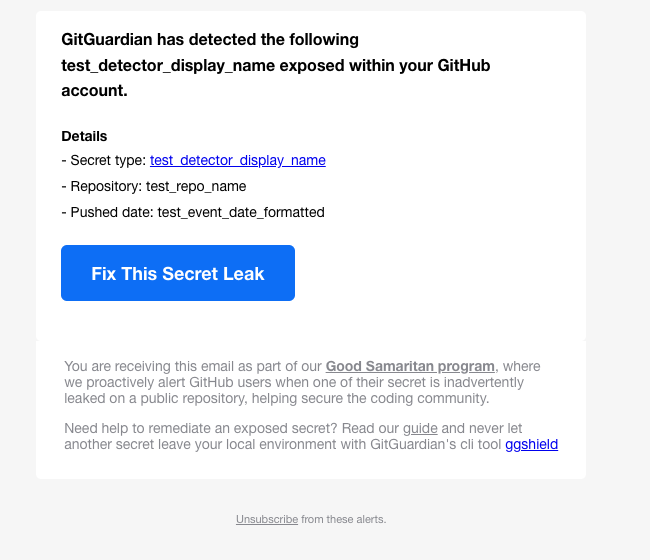
Historically, we notified developers about specific secrets whose validity we could confirm with certainty. We also sent alerts for generic secrets that our system could not definitively verify but were considered potentially harmful and should rarely be committed without caution (e.g., .zshrc files). With the introduction of the Confidence Scorer, we now have a third category: generic secrets that are validated by the machine learning model. Remarkably, the response rate for this category is as high as what we see for the specific secrets we are 100% confident about. This significant success demonstrates the importance and potential of machine learning in solving the general secret detection challenge.
Since the scores are readily available for all secrets and the monitored KPIs are more than satisfactory, we will proceed with fully rolling out the confidence scorer.
Next Steps: Enhancing Alert Features
This initial success in using a deep learning model to enhance our secret detection engine will pave the way for numerous other improvements. As a first step, we're already working on refining the model to achieve even higher precision and recall. This involves curating a more qualitative and comprehensive human-labeled dataset with finer-grained categories that go beyond a simple one-dimensional score.
Boosting the model's precision will also indirectly enable us to uncover even more secrets in the near future. Furthermore, we'll gain deeper insights into the characteristics of generic secrets, allowing us to better prioritize their remediation. Our focus remains on assisting developers in resolving issues as quickly and efficiently as possible. All of these enhancements will soon be integrated into the GitGuardian Platform, bolstering our already robust secret detection capabilities.
Users can expect improved prioritization and greater customization options in the dashboards. This also opens the door to even more exciting AI-powered features that leverage incident feedback collection. We're eager to work on these advancements to further strengthen GitGuardian's industry-leading detection, precision, and remediation workflows!







