

Static and dynamic app testing are cornerstones for any comprehensive AppSec program, yet they rarely rise up to the challenges of fully securing modern software. Discover what are their weaknesses and how they can be complemented.
Introduction to static and dynamic testing
The need for application security testing has existed for almost as long as software development itself, with the most famous approaches being known as Static and Dynamic Analysis Security Testing. Both are often presented as two complementary solutions, providing the necessary safeguards to produce vulnerability-free software. They establish rigorous protocols at the very beginning and near the end of the SDLC.
The ever-growing list of SAST offerings should be a pretty good indicator of the high demand existing for security automation tools in the SDLC. Acting as safeguards, they help developers produce better, safer code by peeking into source code for potential issues. While left shifting on their testing, software companies were also pushing to implement quality controls or even better, to enforce compliance rules as early as possible in the software development cycle.
On the other hand, DAST was designed to be used near the very end of the SDLC, in a complementary approach. Because it needs to be as close to production as possible, this kind of analysis happens last in the SDLC, and is, therefore, the costliest. Nevertheless, it has become mandatory to help protect exposed software, like internet-facing services where malicious behavior is common.
In this article, we will see that, in a DevOps world, a lot of vulnerabilities may fall through the cracks if application security is limited to these classical approaches. Moving towards DevSecOps requires a new set of automated testing procedures.
SAST & DAST: benefits and shortcomings
Static Application Security Testing is the most commonly used scanning technique. Often referred to as “white box testing”, it consists of scans performed on source code to identify the maximum number of potential vulnerabilities, before the resulting artifact could be even built.
SAST is performed without actually executing the program, and it needs to be syntactically aware of the code and the program’s inner mechanisms: everything from language, dependencies, method calls, execution order has to be extensively scanned and compared against a database of known vulnerabilities.
When correctly implemented, it can protect against most of the OWASP TOP 10 web application vulnerabilities, such as memory leaks, cross-site scripting (XSS), SQL injection, authentication and access control misconfigurations. It is common to find SAST tools directly baked in modern IDEs, or distributed as extensible plugins, because the closer to source code it is, the shorter the feedback loop for developers and the easier it is to remediate.
This faculty explains why SAST is often praised by managers, and, because the tool needs to be very precisely tuned to the stack it is used on, why so many different solutions exist.
Unfortunately, static analysis can also generate a very high number of false positives and has the reputation of quickly becoming a source of alert fatigue for developers.
Dynamic Application Security Testing - also known as “black box” testing - doesn’t find vulnerabilities in source code like SAST. Instead, it finds vulnerabilities by employing fault injection techniques on an app. The idea is to test from outside, with no knowledge of the app internals similar to what Red teams or Pentesters are doing to test for breaches.
It can also cast a spotlight on runtime problems that can’t be identified by static analysis, like authentication and server configuration issues, as well as flaws visible only when a known user logs in. Because they try to mimic adversarial behavior, they are agnostic to the underlying used technologies.
Their popularity has been rising at the same pace as web applications, handling more sensitive data and extending the number of serving endpoints, that is to say their attack surface.
An expanding set of tools to better fit into the modern SDLC
The SDLC has seen great acceleration fueled by DevOps and Agile frameworks. New paradigms requiring new and more flexible tools, innovative approaches combining multiple aspects have surfaced. We can mention:
- Software Composition Analysis, which specializes in tracking open source components vulnerabilities.
- Interactive Application Security Testing, which stands as a modernized, hybrid approach "grey box" testing, implemented using an agent within the test runtime environment that observes operations or attacks and identifies vulnerabilities.
- Runtime Application Self Protection, which is a new kind of protection relying on both real-time attack detection capability and application behavior awareness. By using the app to continuously monitor its own behavior, attacks can be identified and mitigated immediately without human intervention.
These hybrid techniques highlight the fact that the dichotomic approach to application security offered by SAST/DAST is quickly being deprecated. Having two big security staples stretched out over the SDLC is not enough to be able to adapt to the new threats’ categories around software code. In fact, when it comes to hardcoded credentials, a whole new aspect has to be taken into account.
This time is different: an invisible threat surface
Secrets come in all kinds of forms but they are all designed to be used programmatically. No wonder they end up so often being hardcoded into source code. Many types of files are susceptible to hold secrets (source code, configuration files, environment files…) but, even more worrying, code is copied and transferred everywhere, because git is designed in a way that allows, even promotes, the free distribution of code.
Projects can be cloned onto multiple machines, forked into new projects, distributed to customers, made public – you get the picture. Each time it’s duplicated, it means the entire history of that project is also duplicated.
The fact is, for static analysis tools, this huge threat surface is invisible because only the current state of your codebase is scanned. On the other hand, secrets detection needs to be done on the entire history to prevent and remediate potential breaches. Indeed, even a hardcoded secret hiding deep in a never-deployed commit could be exploited by an attacker.
Simply put, secrets detection literally requires a new dimension to be added to the common scope of static analysis.
Where SAST fails to convey the idea of probable “dormant” threats inside the git history, new concepts and methods need to emerge. This is why at GitGuardian we believe secrets detection deserves its very own category, and work towards raising the general awareness around its benefits. Older concepts are too narrow to encompass these new and actively exploited kinds of threats. But that’s not the end of the story: code reviews are a flawed mechanism, too.
Code reviews are flawed: why one missed secret is enough
One great advantage of git is the ability to quickly and clearly see changes made, and compare previous and proposed code states. Therefore, it’s common to believe that if secrets are leaked in source code, they will almost certainly be detected within a code review or in a pull request.
Conducting code reviews is a great way to detect logic flaws and keep code quality high by enforcing good coding practices. But they are not a reliable way to detect when secrets have leaked into source code.
This is because reviews are generally only concerned with the net difference between the current state and the proposed state. Code reviews do not consider the complete history of a development branch. This is problematic because branches are often cleaned before a review, temporary code used for testing is removed, log files, and other unnecessary documents, or temporary hardcoded secrets, are removed so these don’t end up in the master branch.
The problem is that they stay in the history; unless the reviewer goes through the branches’ entire history, which could be extensive, any secrets previously committed will remain.
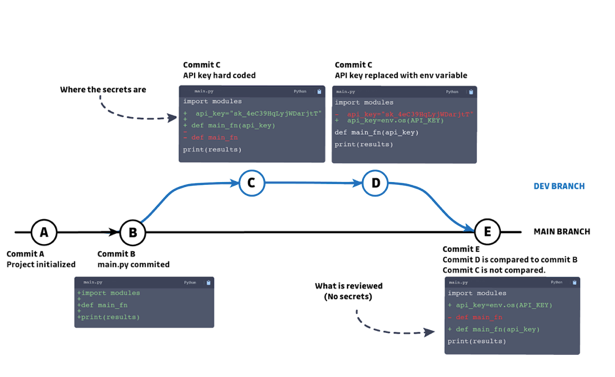
Above is a simplified version of a git tree that may paint a familiar story.
A new development branch is created and the developer, wanting to move quickly, hardcodes secrets into the source code (commit C). After finalizing the changes and getting the feature working as intended, he cleans his code, removing the hardcoded secrets and replacing them with environment variables.
This example is both representative of a typical task executed by most developers nowadays, because of the need to be given access to external resources thanks to secrets (like an API key), and of a “dormant” vulnerability that would not be caught by any SAST nor DAST solution.
Conclusion
The example of secrets hardcoded into source code has clearly shown the limit of SAST and DAST. Both are still necessary, but no more sufficient to shield application security from vulnerabilities. Unfortunately, the security landscape is moving at a great pace and the proliferation of intricate concepts makes it sometimes difficult to grasp the definitive scope of action and limitations of some tools.
Automated testing has proven to be necessary to provide solid foundations to any security program, but it has to evolve in order to fully embrace the new ways of building software. Meanwhile, one of the consequences of increased collaborative work and interdependent building blocks in modern software is secret sprawl.
This has given birth to a new category of application security called automated secrets detection. While conceptually simple, detecting secrets in source code is inherently difficult due to the probabilistic nature of secrets; additionally, secrets can sprawl into assets that organizations have no control over, such as employees’ git repositories. Take the test (no email required) to see how many secrets your developers have inadvertently leaked on public GitHub.
For these reasons, organizations need to be deliberate in making sure the solution they select not only has adequate detection capabilities, but also covers assets both internal and external to their perimeter.







