

Anyone who has tried to deal with secrets sprawl at scale will tell you it feels like a daunting task. On the surface, at first glance, it can seem like it's just a simple matter of some grep and rotating a few keys. Admittedly, if you are a solo dev or working on a small project, that might be all you need. That is especially true if you have consistently been using a vault or secrets management service like CyberArk (GitGuardian and CyberArk have developed a joint solution for comprehensive secret security), Doppler or Akeyless since the beginning of that project.
But, if you are working with several dev teams, including subcontractors, or mountains of legacy spaghetti code across hundreds of repos, it is a different story. What that grep produces will likely end up as hundreds or thousands of rows in a CSV file full of file names and, commonly, the secret it found.
Now what?
This is where the true gravity of the situation kicks in for many teams. What other data do we need? Who is in charge of what? Do we put this in Jira? What about the developer? How do we approach this with them?
GitGuardian built the Secrets Detection Platform dashboard to help teams of any size answer those questions and more, helping you get a handle on secrets sprawl. Let's look at how users leverage the platform to respond to incidents and clean secrets from legacy code.
On average, every developer commits around 3 secrets/year. For an org with 400 developers, that adds up to 1200 new secrets committed per year! The larger the company, the more security tech debt incurred over time. How many developers does your organization have? Check out the Secrets Detection Value Calculator to estimate the cost savings and productivity gains leveraging GitGuardian can bring.
Just the facts
If you do have a spreadsheet, then your next step will be to gather more information about the secrets incidents you have uncovered. Getting the most vital facts about these incidents will allow you to meaningfully sort the report and help you determine the next steps.
Here are some of the data points that we at GitGuardian think are important:
- Date of the incident - How much time has passed since the secret was added to a repo or messaging channel?
- Type of secret - Was this a generic password for an internal tool with no sensitive data, or was it the root credentials for your AWS account?
- Location - What repo or channel is it in?
- Developer involved - Who signed the commit and can provide feedback on this incident?
- Publicly exposed - Does this secret also exist publicly on GitHub.com?
- Number of occurrences - is this limited to one file or commit?
- Validity - Does this credential still work?
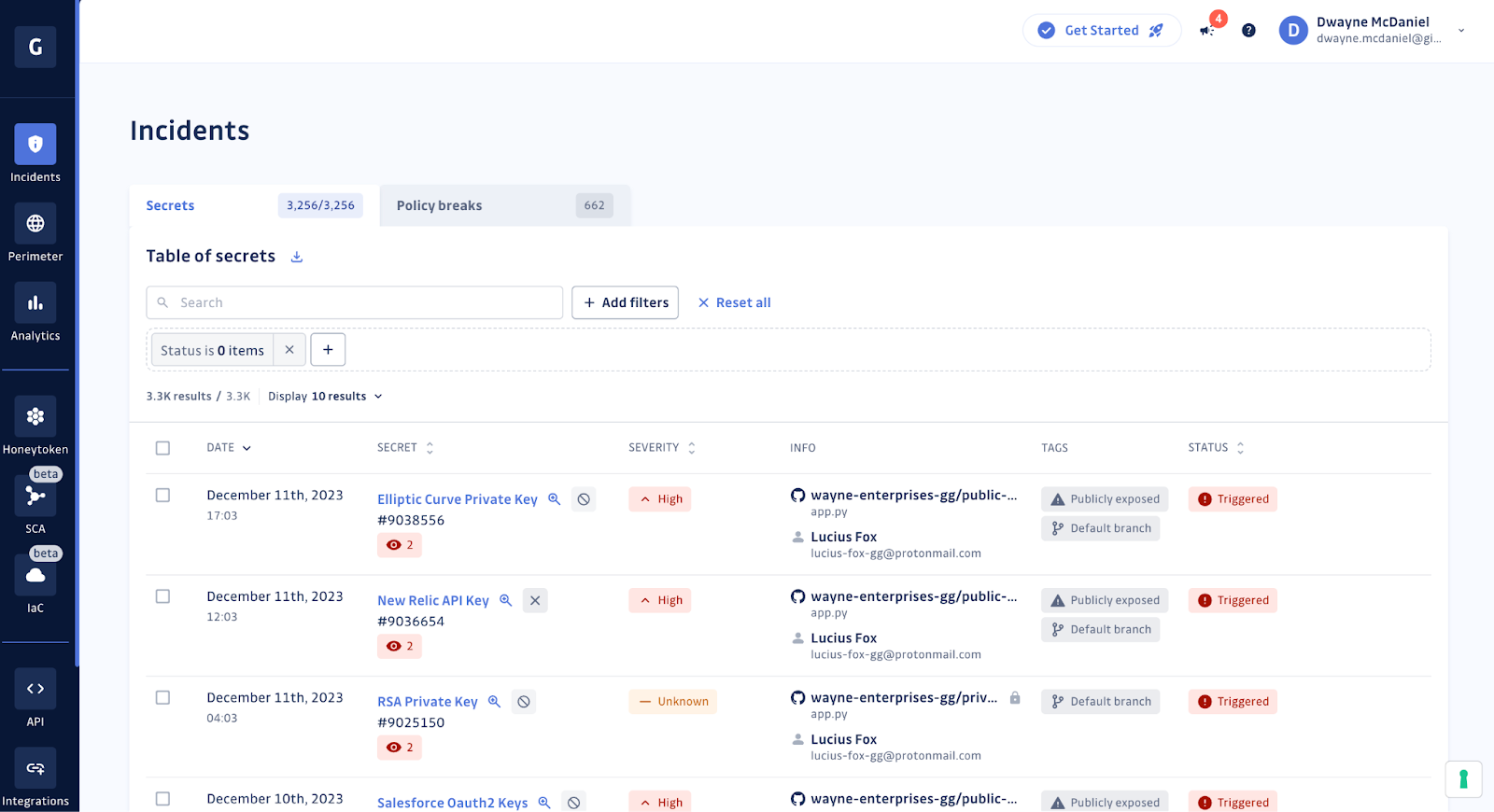
Validity checks reduce the noise
Writing regular expressions is pretty straightforward, though no one would call the process easy. However, just detecting the matching string might mean you have a live credential that could be exploited, or it could mean you found a test credential in a README that shows what form the credential should take. If you are working from a spreadsheet, this means part of your data collection means building a validation step. Now, your simple grep approach needs more logic added, and we have not even started the remediation process.
GitGuardian has built-in validation processes that can quickly tell if the most common and costly specific types of credentials allow access. In addition to just checking to see if the keys work, there are also extensive Pre-Validators and Post-Validators processes employed by the platform. You can dig into our documentation for full explanations of what we are testing, but the bottom line is this is all in the service of cutting through the noise and making sure any alerts GitGuardian raises are real and actionable.
Triaging secrets incidents
If you are filling in your spreadsheet and have gathered the data and validated the found credentials, you are just about ready to start the remediation process. Now, in what order should you attack the list? The valid ones first? Or the most critical systems?
Not all incidents are created equally. This is why GitGuardian includes logic that can help you quickly prioritize all incidents in a consistent and scalable way.
In addition to the incident data we already discussed, GitGuardian also provides:
- Severity scoring - GitGuardian's automated and tunable severity scoring quickly grades all incidents from Critical, meaning the incident needs to be dealt with immediately, to Low or Info, meaning they can likely wait for action.
- Presence in git - Is the secret still in the repo, or has it been removed already?
- Tagging - Our automatic tagging will help you quickly prioritize each incident.
There are eight different tags:- Default branch - This is most often triggered when the occurrence was in the main branch, most likely affecting production.
- Publicly exposed - The incident was discovered in a public repo on GitHub.com.
- Publicly leaked - The secret has been detected outside of your organization's repos.
- From historical scan - In addition to real-time monitoring, GitGuardian also cans each repo throughout each commit and branch to give you a snapshot of the secrets in the code history.
- Regression - At one point, this secret was resolved, but a new occurrence has been detected.
- Sensitive file - The incident involves a potentially sensitive file, like an
.envorsecrets.json. - Tagged as false positive in check runs - The secret was reported as a false positive by a developer.
- Test file - The secret was found in a likely test file or folder, such as
../testfolder/test.py.
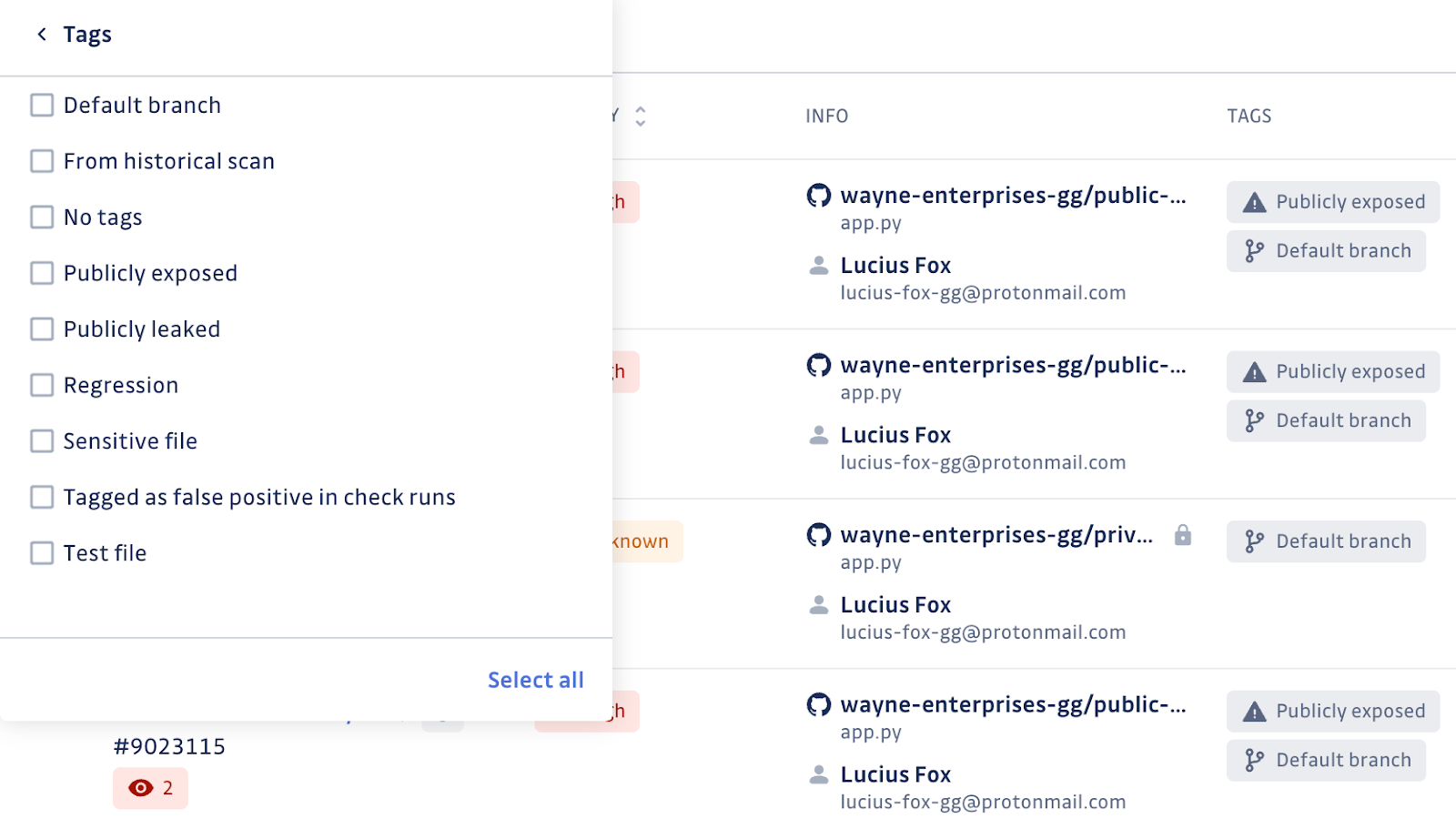
Who is working on this?
If you are still working on your shared spreadsheet and have gathered the data, tagged each row, and prioritized the work, it is time to get to remediating the critical and valid ones first. If you are working by yourself, it is easy to know who is working on what, as you can mark your progress however you prefer. If you are working at scale, you will have a whole team to coordinate and collaborate with. Time to add yet more columns?
Remediating an incident involves multiple steps and can take hours or days. It is not just a matter of hitting a magical "rotate the secret" button and closing the ticket. Resolving an incident often means checking if unauthorized access to data or systems has resulted in any exfiltration, engaging with the DevOps team to prepare for any downtime when the secret is rotated, and cleaning up any affected workflows once the old secret is revoked. Keeping track of your progress in a transparent way gets very tricky when multiple team members are working on multiple incidents at once.
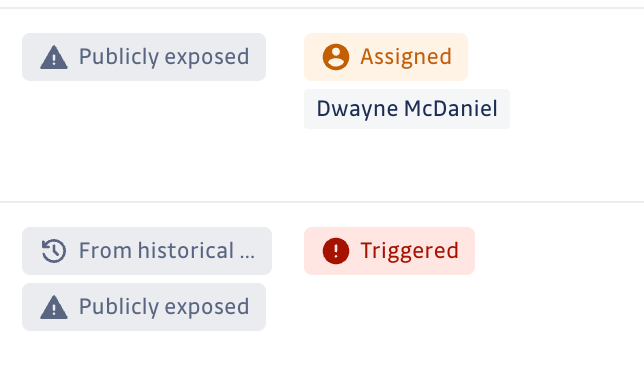
In the GitGuardian Incidents View, you can quickly tell if someone has been assigned to work on the ticket. A new incident without anyone yet working on it will have a status of Triggered. If someone has been assigned to work on the remediation, you will see that team member's name and the status of Assigned. If the incident has already been closed out, you will see a status of either Resolved or Ignored, letting you easily remove those from your filtered view.
Teams
Depending on the size and complexity of your organization, you might need to spread the remediation work across multiple teams with specific domain knowledge. GitGuardian helps you organize the work by creating logical Teams with granular access and specific member permissions. Creating teams is simple and makes it very easy to delegate to the right person or persons quickly.
Involving the developer
When investigating an incident, one of the first questions you will likely have is. "What was this developer thinking?" There might be a legitimate reason for including something that matches the patterns you are looking for, such as the case with test credentials or examples. If you are working from a spreadsheet, it is time to start crafting emails or Slack messages, explaining the issue, and asking for the right kind of feedback. All while the clock is ticking.
The GitGuardian Dashboard incident view has a handy "Share" button built right in. Pressing it opens up a modal with multiple options, including the ability to share this one incident with a trusted team member. You can grant full access, with the ability to edit and revolve the incident or limit their access to view only.
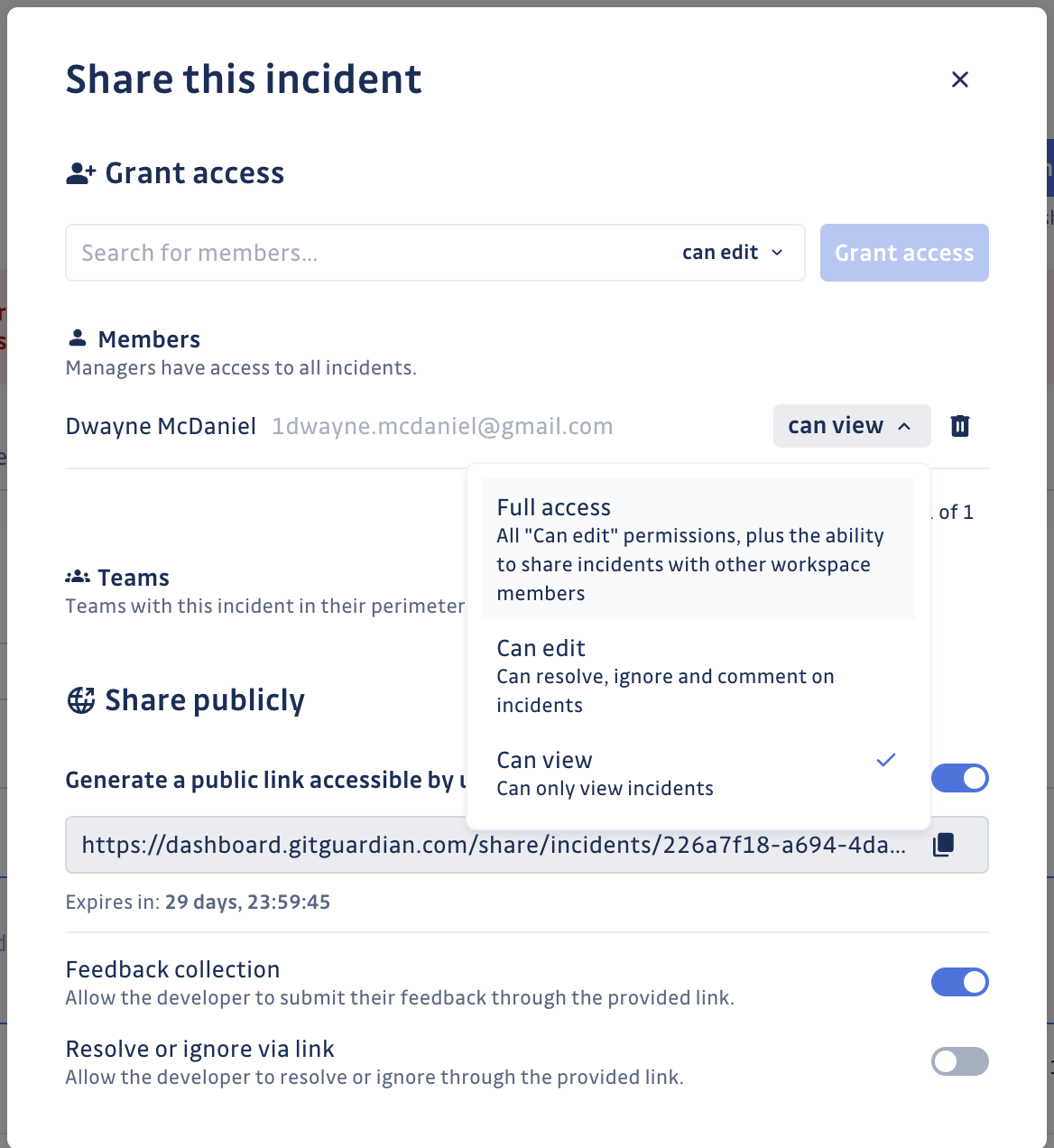
There is also the ability to share the incident publicly, which is handy when working with subcontractors or collaborators outside your organization. Simply turn the share publicly link on and decide if the person with the link can just see the info, share feedback, or close the incident from their seat.
Just remember to treat that link as a secret itself, as anyone with the link can see the secret involved. If you forget to turn off the link manually, every link automatically becomes invalid after 30 days.
Automating
Working from your spreadsheet, likely with multiple tabs to track communication and team assignments on top of your secrets sprawl incidents, you might think, "There must be a way to automate some of this process." After all, you found all these incidents with scripting; another script might help here. Spreadsheets are good with formulas. Right?
While Bash and Python scripts are magical, there are just a lot of hops you are going to need to make and systems to tie together to start automating any steps in the process. GitGuardian has had a lot of experience helping customers automate the remediation process, which is the basis for GitGuardian Playbooks. These automation scripts can easily be turned on in seconds, letting you share incidents with the involved developers upon discovering a new incident, grant access to the right team members even faster, or automatically close incidents when the secret has been invalidated.
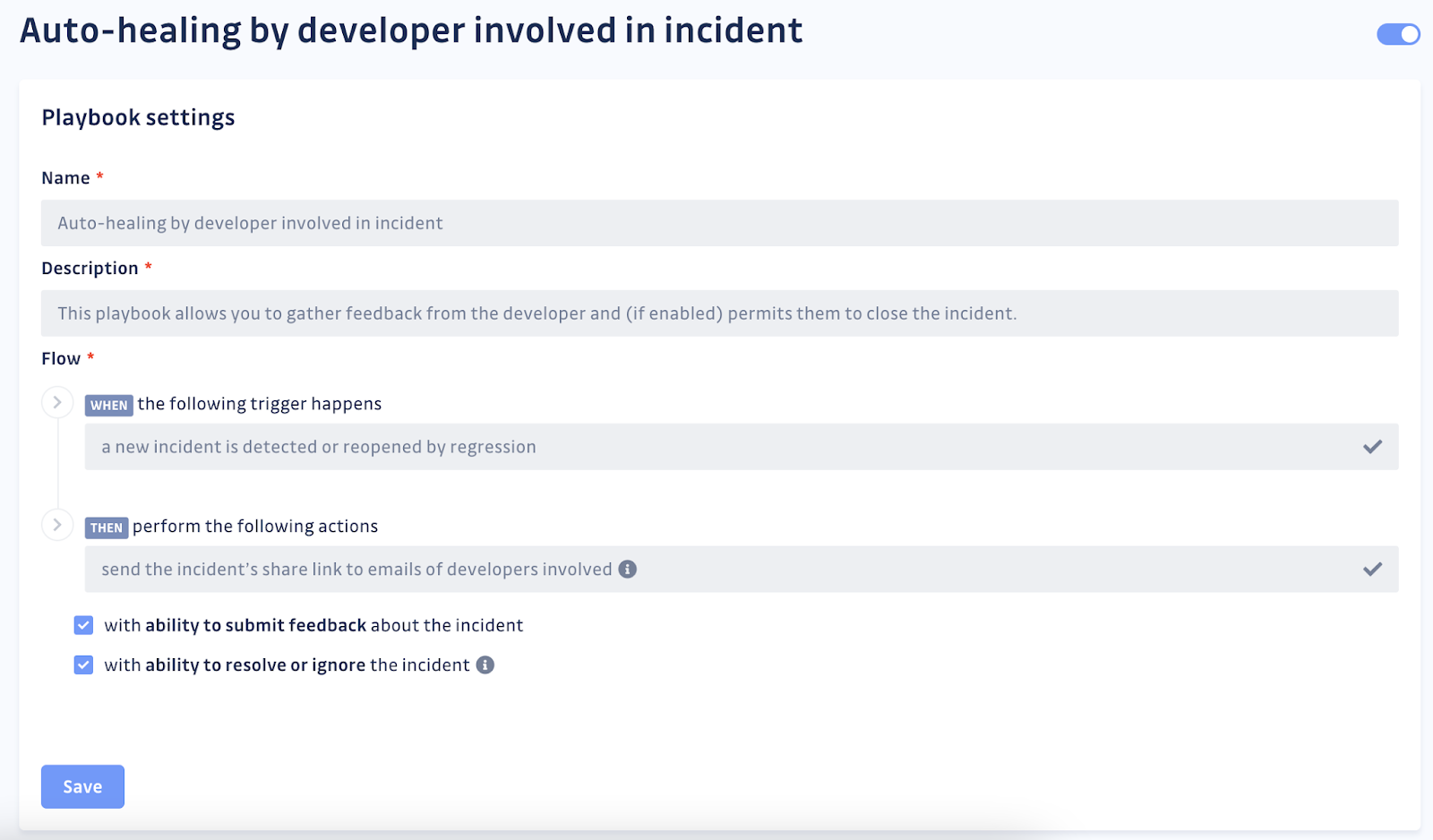
API
The entire GitGuardian Dashboard is API-driven. You can easily script against the platform or integrate GitGuardian capabilities with other tools with our secure, easy-to-use, and well-documented API. If you can perform the action through the dashboard, then you can do that action with an API call, opening up a whole world of possibilities to leverage other tools and platforms.
Planning for safety
For a lot of companies, the process of removing and replacing plaintext credentials is motivated by a security incident, adding an additional layer of stress. Trying to hand-assemble all the needed data points and manage your incidents from a spreadsheet makes a difficult situation all the harder. This is why so many teams evolving their secrets management maturity rely on the GitGuardian Secrets Detection platform as they work to improve their overall code hygiene.
In GitGuardian, all the needed data points are pre-assembled consistently and reliably. The platform provides logic with tagging and severity scoring to help you easily prioritize your found incidents in order to reduce the highest risks quickly. Our assignments and team management abilities reduce a lot of stress from the delegation side of things. Thanks to the incident-sharing capabilities, gathering feedback has never been more streamlined and scalable. And as you see ways to improve your process, the stability and reliability of our API mean you are only limited to your imagination.
Don't forget that detecting the secret is just the first step. Gathering all the needed data and going through the remediation process will likely take significant time and can become rather complex quickly. The larger the code base and the more developers involved, the more rapidly your technical debt accrues, taking more time to resolve and pulling focus and resources from other work.
If you spend more time and effort fighting Excel or Google Sheets than you are remediating your secrets sprawl, it might be time for a change. We invite you to join thousands of other developers and security professionals in leveraging the GitGuardian Secrets Detection platform today. We very much want to help you keep your secrets a secret.






