


While increasing both the precision and the recall of our secrets detection engine, we felt the need to keep a close eye on speed. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed. At roughly 10 thousand public documents scanned every minute, this eventually led to a bottleneck.

In a previous article, we explained how we built benchmarks to keep track of those three metrics: precision, recall and the most important here, speed. These benchmarks taught us a lot about the true internals of our engine at runtime and led to our first improvements.
In this article, we will go through the analysis of those benchmarks as well as the first improvements we made. Finally, we will make some recommendations to build efficient real-time data filtering pipelines.
Analysis of our initial benchmark
As a reminder, our secret detection engine is split into detectors catching different types of secrets. Each of these detectors is composed of three parts:
- Prevalidation filters documents that will surely not contain desired secrets
- Matching extracts potential candidates from the document
- Postvalidation filters those candidates based on their context or entropy.
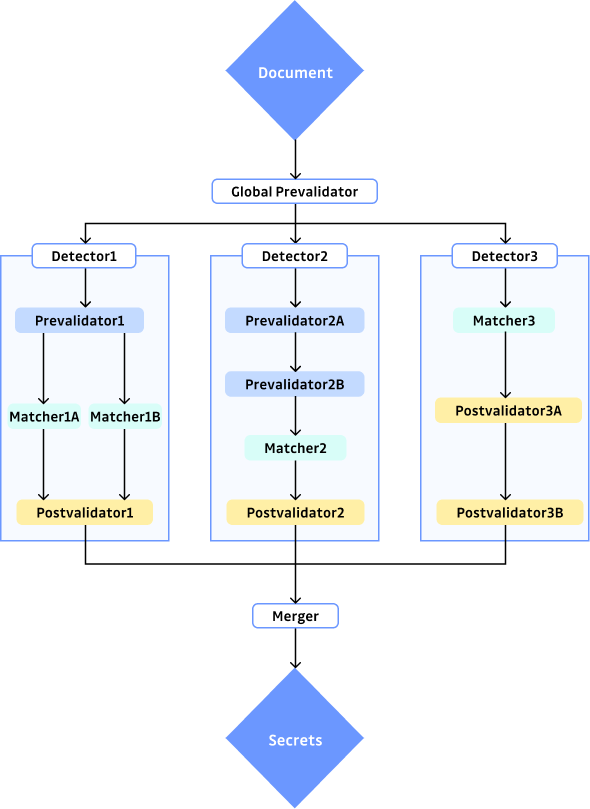
Those three parts are generic and tuned for each detector in order to match all secrets and only secrets.
| Name | Percentage call | Percentage time spent | Time per call (µs) |
|---|---|---|---|
| Prevalidators | 98.0 | 55.2 | 2 |
| Matchers | 1.8 | 43.8 | 73 |
| Postvalidators | 0.2 | 1.0 | 15 |
In the above table, we can already get insights about our engine’s performance for each of those parts.
First of all, prevalidation is the most time-consuming operation, taking an average of 55% of the time used to scan a document. However, it is also the fastest operation because each call to a prevalidator is only 2 microseconds. Being the fastest doesn’t mean it does not need improvements: with more than 98% of the calls, it is the most important one. Prevalidators are applied to all documents and are supposed to be fast, coarse filters to remove most documents. This is where any improvement can drastically change our performance. We will later focus on this step for the first basic improvements.
Then, Matchers take almost as much time (44%) but they only represent 2% of the function calls in our process. The extreme difference (30x slower) is mostly because this is where all the magic happens: from long and complex documents, we extract potential keys matching complex patterns. There is surely room for improvement but matchers are highly complex and customized, i.e. they are harder to optimize. Our research on this topic will be described in another article of this series.
Finally, post validation represents 1% of the scanning time. The main reason is that our matchers yield only very few candidates compared to the tremendous number of documents we receive as input. This benchmark confirms that post validation is not a step we should focus on if we want to improve the scanning time (even if removed, we would only be 1% faster...).
Prevalidation Performance Tuning
Every optimization presented below comes under the assumption that we don’t want to change the precision and recall performance of our scanner.
Prevalidation is 98% of function calls, so even small improvements in the call will lead to major speed increases. This should also be the easiest because we only have two types of pre validators: we either filter documents on their filenames or on the presence of keywords in their content. While the values are different for each detector, the logic remains the same.
Most of our detectors skip files known to contain a lot of random strings that are false positives. However, these files cannot be banned directly at the root of the engine (global prevalidator) because some specific detectors are designed to take a closer look at them.
One good example of that are the .lock files: they often contain innocuous hashes of packages, but there can still be credentials for a package manager or a git repository manager.
We have to scan the same file multiple times to determine if it is relevant to continue the process with the selected detector.
In order to speed up these repetitive lookups, we decided to implement a cache for a given property (such as “file is a dependency lock”) and retrieve the result later. We tried several “levels” of caching based on the popularity of the property across our detector’s database. We found that in some cases, retrieving the value was longer than scanning the filename. So we kept only the most common values (⅔ of our detectors were concerned). This has the benefit of being very light in code while reducing the number of computations done.
As a second operation, we found that our prevalidation steps were not ordered the same in all detectors. Some started by inspecting the filename while others started with the content. At first, we wanted to filter on filename first because it seemed to be more efficient to start with a really simple operation (filename is usually shorter than file content). However, a deeper analysis proved that content filtering was slower but would remove more documents hence reducing the overall scanning time. Therefore, we inverted the operations when necessary and this significantly increased the speed of our scans. This improvement was also very easy to achieve because we only had to invert the steps in the configurations of our detectors.
Third, we found out that some detectors had no prevalidation steps on the file content (ie looking for keywords related to the secrets). We were omitting this step in order to ensure maximum recall and precision when they were not necessary. The problem is that those detectors were almost every time the slowest ones among our database. This is because our matching patterns are highly customized to match only the secrets so the regex engine is slow to find matches. After some experimentation, we concluded that it was almost always beneficial to add a light version of the matcher’s pattern as prevalidator and that it would not reduce recall or precision.
Finally, our engine mostly relies on Python’s regex engine and a majority of the operations are done during pattern matching. Many improvements could be done by changing our regex engine. As many of our readers may know, improving regex performance is a topic by itself. Our regex engines’ experimentations will be discussed in a dedicated article.
The first steps in a filtering process are the most important: how you should optimize them
In the data analysis era, most companies have to handle data streams and filter them to extract valuable business insights. We think that our findings can be applied to any filtering process (and this is the main point of our article, not everyone builds secret detection engines). Here we try to describe key points for an efficient filtering process.
The first steps are executed on all documents so they are key for speed. These should require the most effort to be simple and to remove as many documents as possible. In case there is no tangible simple filter, a lighter version of the next steps can be used. In our case, we try to use a simplified version of the matchers rules if we haven’t anything else. While this is not ideal, it has proven its efficiency (up to twice the speed on the concerned detectors).
All steps need to have a defined job and do only one thing. This will allow the algorithm to be easily understandable and parameterizable. Interlaced tasks will be harder to evaluate and will blur functional benchmarks. In our engine, we have document filtering followed by candidates evaluator and finally candidates filtering: each task is independent of the previous one so we can change one without modifying the others to study its influence.
The final step is executed on a smaller sample of elements because most documents were removed by the previous steps. In the cases where you only keep a small fraction of the samples, this step will not have a great influence on the overall performance. Optimizing it will not change the overall speed of the process.
To scan millions of documents every day, all this process is parallelized on documents with multiple workers. Since our detectors have an independent behavior between global prevalidation and the merging of all secrets, we could run detectors in parallel. However, it is less efficient since processes would have had to wait for others to finish before being able to merge (synchronization time). It would also be harder to maintain since multiprocessing can be difficult to debug.
Conclusion
Writing detailed benchmarks allowed us to verify that our engine had the expected behavior, it also taught us which parts were the most sensitive and with the best efficiency.
Analyzing those, not only did we improve speed performance but we also learned a lot about the different components and their utility.
In the next article, we will dive deeper into the internals and see how we benchmarked different regex engines in several parts of our scanning library.









