


This article is the first in a series on performance @GitGuardian.
Introduction
Speed is a crucial component in secret detection, because of the sheer volume of data to scan. In the 2020 State of the Octoverse, GitHub reports nearly 2 billion contributions. Around one-third of those contributions are commits and each commit contains multiple patches. In 2020, at GitGuardian, we scanned 4.3 billions patches. Furthermore, we perform historical scans on the complete private git history of new clients, meaning we need to be able to scan decades of contributions in a few seconds. Secrets detection is a balancing act between speed, precision and recall.
This is a post on how we managed to make our engine 3 times faster while increasing by +25% the number of detectors, not to mention continuously improving existing ones. All of that since the beginning of the year.
The first step is to build a baseline: intuition and gut feeling are not enough, we need to be able to quantify improvement. To reach this goal, we need a way to run comparable benchmarks. The critical parts are:
- a static dataset to feed each of the engine's versions. In our case, the dataset is a collection of commits.
- a way to measure how long it takes for our engine to perform its task on the dataset.
Since a benchmark is only as good as its test bench, we need to take extra care when designing the test bench. In the first section, we will explain how we dealt with this task, and how we avoided common pitfalls.
1. Building a test bench
A good dataset needs to be representative of real-life data. Our method to produce a representative dataset of commits is to gather every commit from GitHub during a long enough timeframe: in our case, 2 weeks, which allows us to gather tens of millions of commits. Even with such a large dataset, you need to be careful because it is not unusual to see a single account commit hundreds of thousands of times in a few days. It is usually the result of a script updating every second a file in a repository. In order to filter out this noise, we add a limit of commits per GitHub user.
Every new dataset is inspected and statistics are computed to ensure its representativity and coherence with both previous ones and "real-life" stats. Every 6 months, we start over and generate a new dataset. It's a trade-off between staying up-to-date with secrets from the latest hyped services and being able to reliably compare benchmarks. Also, even if the generation of new datasets is largely automated, it’s still time-consuming.
A helpful realization is that a majority of performance problems can be detected within a subset of the main dataset: in other words, an abnormally slow detector will be significantly slower even on a small dataset.
Another important component of our test bench is the dedicated powerful server used to run the benchmarks. Each benchmark is run in the same conditions, otherwise, they wouldn’t be comparable.
Once a good test bench has been established, we can run benchmarks regularly in order to help us keep improving the performance of our engine.
2. Implementing benchmarking scripts
Benchmarking is not a trivial task, it can be easy to make mistakes and misinterpret results. It is even harder when the program you are benchmarking is running in parallel in multiple processes. It is also important to remember that the act of measuring time will in itself take time and consume memory.
We created a powerful tool able to run our detection engine’s benchmarking in parallel and gather statistics while handling both input and output from and to multiple sources (pipe, filesystem, MongoDB, ElasticSearch, and more). Every part of this tool can be instrumented with time measurement so we can have a very fine-grained benchmarking capacity.
We have two levels of details for our benchmarks:
- at the detector level to compare the performance of the detectors, rank them and know which one should be improved in priority.
- at the component level, more detailed, which gives us the time taken by each component of the secrets detection engine and is used to improve the performance of the engine as a whole.
For both types of benchmarks, we also developed comparison scripts to interpret the results. As said above, measuring time takes time, the result of the benchmark is the time taken by the detection engine + the benchmark overhead o:
Ti = ti + o (we assume the benchmark overhead is constant).
When comparing the performance evolution between two benchmarks the overhead is cancelled out:
Ti - Tj = ti + o - tj - o = ti - tj
This is enough for tracing gross evolution.
3. Leveraging benchmarks and monitoring performance
We run benchmarks at all steps of the development process. On every newly created branch, we run a quick detector-level benchmark on a sample dataset. This allows us to identify abnormally slow detectors, where we would expect similar detectors to have similar performance. A new detector should not rank among the slowest unless it is the only way to reach our standard of precision and recall, for example generic detectors are among our slowest detectors but they catch 45% of the secrets. We leverage GitLab’s metrics reports to show the results directly in the merge request. Reviewers can see code changes and their impact on performance in one place with it.
Before each release, we run the same benchmark on the complete tens-of-millions-commits wide dataset. It takes a few hours to run but it is more representative and less subject to random fluctuations. By comparing the results with the previous release benchmark, we can be confident that we are not degrading the performance. We've never been surprised by the results thanks to the smaller benchmarks.
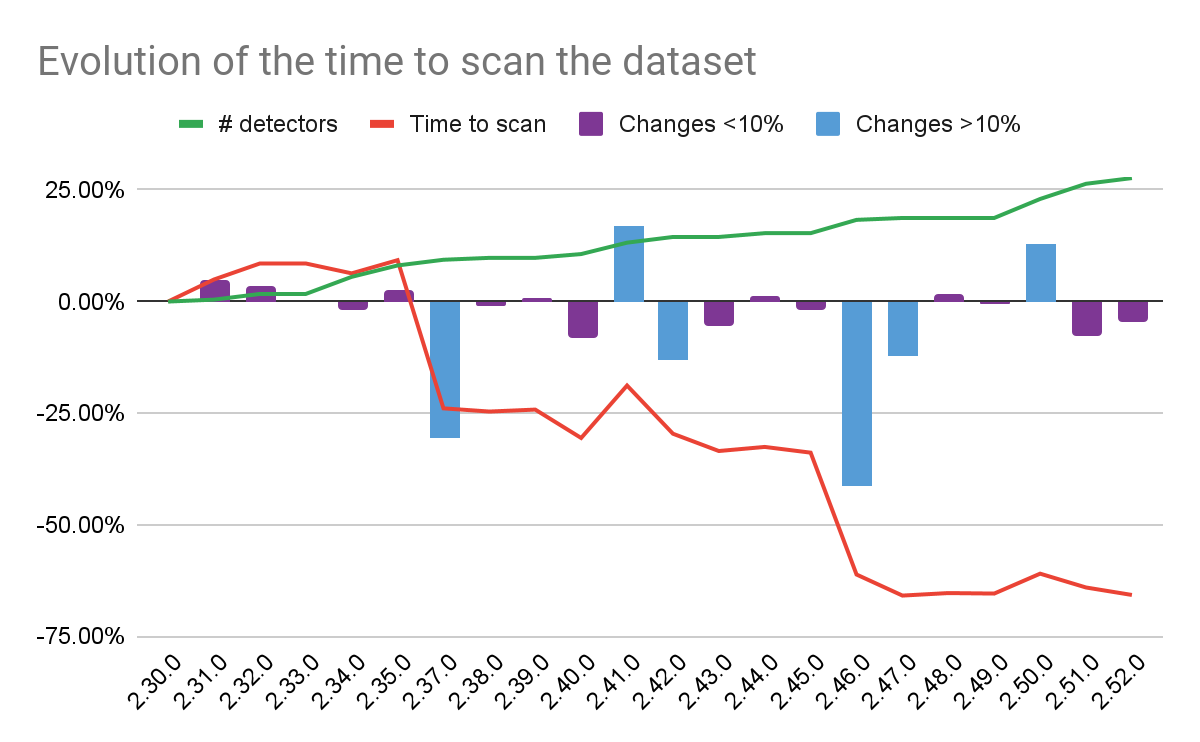
How to read it
We release a new version internally every 2 weeks, the 2.30.0 was released 10 months ago and the 2.52.0 was released a few days ago at the time of writing. The time it takes to run the secrets detection engine on our dataset was reduced by nearly 70%. Another way of saying it is that the engine speed has been multiplied by ~x3. The graph above shows this evolution, and you can notice that in the meantime the number of detectors (in green) steadily increases (+25%). We are doing more in less time! Significant variations are represented by blue bars while purples ones correspond to smaller (<10%) variations. A change of less than ~10% may be caused by outside factors.
The detailed benchmark on the other hand is significantly slower because it is timing a lot more components. It is only run before and after improvements to validate the performance gains. It allows us to know which part of the detection engine should be improved first. Detectors are made of three elements: pre-validators, matchers and post-validators. For example, post-validators represent less than 0.2% of the function calls and less than 1% of the scanning time (they are only called when a secret is found to validate it). Improving the speed of the post-validation, even making them a million times faster, would have almost no impact on the global speed of the engine.
Pre-validators, on the other hand, are applied to every commit. The ~40% performance gains in the 2.46.0 release are entirely due to pre-validators. The reasons for this improvement are only understandable with the detailed benchmark.
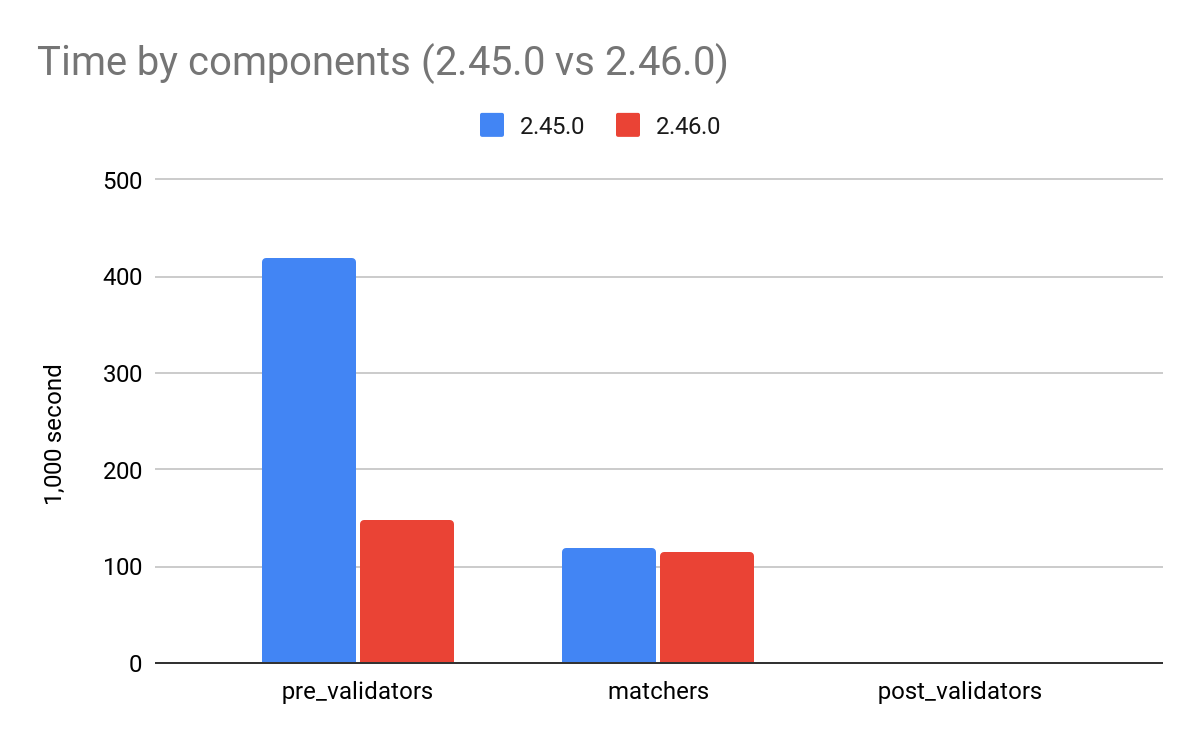
As you can see, pre-validators went from dominating the scanning time to almost taking as much time as the matchers. After the 2.46.0, the pre-validators became nearly 3 times faster, making the whole engine nearly 2 times faster. If you’re curious about how we managed to achieve such a feat, we will go into further details in the next article.
Conclusion
With precision and recall, speed is part of our main objectives when developing our secret detection engine. I hope you now have a better understanding of how we structured our benchmarking tools to gain a clearer vision on the places where we could quickly improve the engine performance as a whole. Without it, we surely wouldn't have been able to add detectors while actually decreasing the scanning time of our sample dataset.
If you are interested in learning more about the crucial pre-validation step, and what key decisions were made about our regex engine, hit subscribe to stay tuned for the next article.









