


Open-source vulnerabilities are arguably the most ubiquitous part of application security. Software developers are constantly plagued by an endless stream of vulnerabilities in the packages their applications are built upon. It would be impossible to keep track of every vulnerability that needs to be addressed if we didn’t have some sort of standard cataloging system. That’s where vulnerability databases come in.
Over time, multiple vulnerability databases have been introduced that do seemingly similar things. Their intents and purposes are obscured by acronyms like CVE, NVD, OSS, and OSV. Collectively, they provide a wealth of information about software vulnerabilities. But the slow sprawl of the vulnerability database ecosystem has started to make things a bit unclear.
In this blog post, we will cover many vulnerability databases and supplementary systems to help you cut through the noise. We will focus on databases that have high relevance to vulnerabilities in open-source software. At the end, you will find a Venn diagram that roughly summarizes the overall coverage of each database as well as some recommendations on how we can improve vulnerability tracking in the future.
Foundations of vulnerability management
Before comparing different databases, we need to understand a bit of history about the tracking of vulnerabilities. MITRE and NIST were the first to implement widely adopted standards for vulnerability enumeration and tracking.

CVE: a vulnerability identification standard
In 1999, MITRE introduced the CVE (Common Vulnerabilities and Exposures) standard, which, at the time, was like the Rosetta Stone for security issues in software. It enabled software vendors and consumers to clearly reference specific vulnerabilities and their patches. CVE is still the most widely recognized standard for vulnerability identification.
The key thing to understand about CVE is that it is solely an identification system. MITRE maintains a list of CVE IDs, but each entry only contains information that will identify the vulnerability.
NVD: a comprehensive vulnerability database
The CVE list maintained by MITRE is continuously synchronized to the NVD (National Vulnerability Database), which is run by the US government organization NIST. The NVD is the first true “vulnerability database” that we have covered so far. It was created to add additional context to each CVE. This context includes vulnerability categories in the form of CWE IDs, CVSS severity scores, a CPE ID to identify the vulnerable software, and details on whether the software vendor has released a fix for the vulnerability.
The NVD is a long-established vulnerability database with a large ecosystem of standards built around it, but using the NVD alone for open-source vulnerability tracking isn’t ideal for multiple reasons.
First and foremost, the NVD has been experiencing issues the last six months (possibly due to its reliance on human analysis for enrichment data). The issues began with missing details in some CVEs, and now the situation has devolved into spurts of missing CVEs and incomplete analysis of what does come through. If you want to learn more about the recent NVD issues, you can read more here.
Another area where the NVD is lacking coverage is for malicious packages. Technically, a malicious open-source package isn’t a vulnerability – it’s intentionally backdoored. Since these packages aren’t assigned CVEs, the NVD doesn’t provide a way for them to be tracked and detected using the NVD alone.
One final distinction that we have glossed over so far is that CVEs are assigned to both open-source and commercial software. Commercial software vulnerabilities are important to corporate security (CorpSec), but they aren’t as relevant to software developers who are mainly concerned about the open-source dependencies that they use in their code. Open-source vulnerabilities have far-reaching consequences due to their incorporation into other software.
Open-source vulnerability databases
Open-source vulnerability databases have emerged to help developers overcome the challenges of monitoring software dependencies with the NVD. These databases aggregate vulnerability information from multiple sources, including the NVD. This culmination of sources makes them more comprehensive and up-to-date than the NVD when it comes to tracking open-source libraries.
OSV: an open schema and vulnerability database
The Open Source Vulnerability (OSV) project was launched in 2021 with the release of the OSV data format. The OSV format was created with the goal of providing vulnerability information that was as actionable as possible in a machine-readable format. Providing additional context in a structured format allows for more automated triage and fixes. The OSV data format was donated to the OpenSSF, which works with the open-source software community on adoption of the OSV format.
The OSV project also maintains an open-source database called OSV.dev. This database is sponsored by Google who payrolls engineers on their open-source security team and hosts the infrastructure for the database. Despite being maintained by a private company, the project and its API are completely free and open-sourced under the Apache 2.0 license.
OSV.dev automatically aggregates vulnerability information and alerts about malicious packages from 24 data sources. The data sources include the NVD as well as upstream sources like the GitHub Advisory Database, which support the OSV format and contain more timely information on vulnerabilities. When a vulnerability is referenced in multiple sources, it is automatically associated with its aliases.
The automated nature of OSV.dev makes it reliant on its data sources for some context, but it does automatically enrich vulnerabilities with some information. For example, they will automatically expand affected version ranges to an explicit list of affected versions. By doing this heavy lifting up front, OSV.dev takes away some of the calculations that would need to otherwise be done by the consumers of the database.
Commercially backed vulnerability databases
There are also commercial vulnerability databases that are focused on open-source packages. These databases are each backed by a private company, and they have varying levels of openness.
The most open commercial vulnerability database is Sonatype OSS Index. You can query the OSS Index API for free without an account. If you sign up for a free account, you can get higher rate limits. Like OSV.dev, Sonatype OSS index is aggregated from public sources and does not do additional human analysis. It is not open-source nor interoperable with the open OSV data format, but OSS Index is a great alternative to OSV.dev with similar levels of coverage.
Snyk is a commercial application security company that also maintains its own vulnerability database. Snyk aggregates vulnerability and malicious package info from public sources, and it is also backed by a team of security analysts that review some entries and add additional context. Features that are unique to Snyk’s database are potentially unpublished vulnerabilities (sourced from forums and commit history), container image analysis, and cloud misconfiguration information. Snyk’s database is not fully open, however. It can only be accessed through Snyk’s own tools (free for individuals) or its Enterprise-only API.
Vulncheck is a commercial database that, like Snyk, is backed by human analysts that provide additional context to vulnerabilities. However, in terms of software coverage it is more akin to the NVD. Vulncheck is focused on both open-source and commercial software tracked by CVE IDs. It claims to provide early access to unpublished vulnerabilities as well.
While Vulncheck’s vulnerability database is a closed and paid offering, they do offer some unique free offerings: Known Exploited Vulnerabilities catalog, NVD++, and XDB (a list of exploits in git repositories). NVD++ is notable for being an enhanced mirror of the NVD that contains some of the data that the NVD has been missing in recent months.
Other vulnerability databases
Some vulnerability databases were left out of the discussion in this blog post because they were more relevant to CorpSec than to open-source libraries and software development. There are two that are close enough to be worth mentioning though:
- Cloud Vulnerability Database: a database maintained by Wiz for tracking vulnerabilities in cloud hosting providers
- !CVE Project: a database of security issues that were denied or not acknowledged by vendors
Future improvements
While writing this blog post, I spoke to Andrew Pollock, an open-source maintainer and software engineer at Google who works on the OSV project. He answered some questions I had about the OSV project and the challenges of maintaining a vulnerability database. When discussing the challenges, he called out three things as opportunities for improvement in the future.
Vulnerable symbol disclosure
A common problem with open-source vulnerabilities is that they are prone to false positives. Let’s say you call FunctionA from a package in your code, but a critical vulnerability was found in FunctionB. If you are just basing your vulnerability triage on the version of the package you are using, then it looks like your project is vulnerable.
If there was a way to identify which functions or “symbols” are related to a vulnerability in a package, we could know for sure if our code is calling the vulnerable section. That’s exactly what vulnerable symbol disclosure is for. Goodbye false positives!
Vulnerable symbol disclosure is undergoing initial adoption and lacks a dedicated field in the current OSV schema. Right now, projects like the Go standard library include it in the “ecosystem_specific” field when publishing OSV disclosures (here’s an example).
Standardized released practices
A couple of challenges that vulnerability database maintainers face are discovering untracked vulnerabilities and providing enrichment to a vulnerability based on release notes or commit messages. If releases or commits that contain security fixes were clearly tagged, it could enhance the speed and quality of vulnerability database entries.
A counter-argument to this practice might be that this would also help bad actors discover and develop exploits for open-source vulnerabilities. However, a tagged security fix means that the vulnerability can be remediated. The sooner databases can track a vulnerability, the sooner software developers will fix the issue in their code. An open-source vulnerability will exist and be visible for the same amount of time whether the fix is tagged or not.
Detailed vulnerability disclosures
Lastly, the level of detail and actionability in vulnerability disclosures varies greatly between vendors. Some software publishers do a fantastic job of providing actionable detail and adhering to the OSV schema for automated ingestion. Others seem to be releasing vulnerability disclosures somewhat begrudgingly to make the security researcher who reported the vulnerability go away.
As a producer of software, it’s important to think about the consumers of your software and the implications of a security issue for them. Vulnerability management scales terribly if you are on the consuming side of software dependencies. But if you are an open-source maintainer, you can have an outsized impact by taking the extra time to write a thoughtful, structured, and actionable disclosure.
Conclusion
Vulnerability management would be impossible without vulnerability databases to provide a standard taxonomy and inventory of individual security issues. We took a comprehensive look at databases that are relevant to open-source software, and now we have enough information to make some rough comparisons.
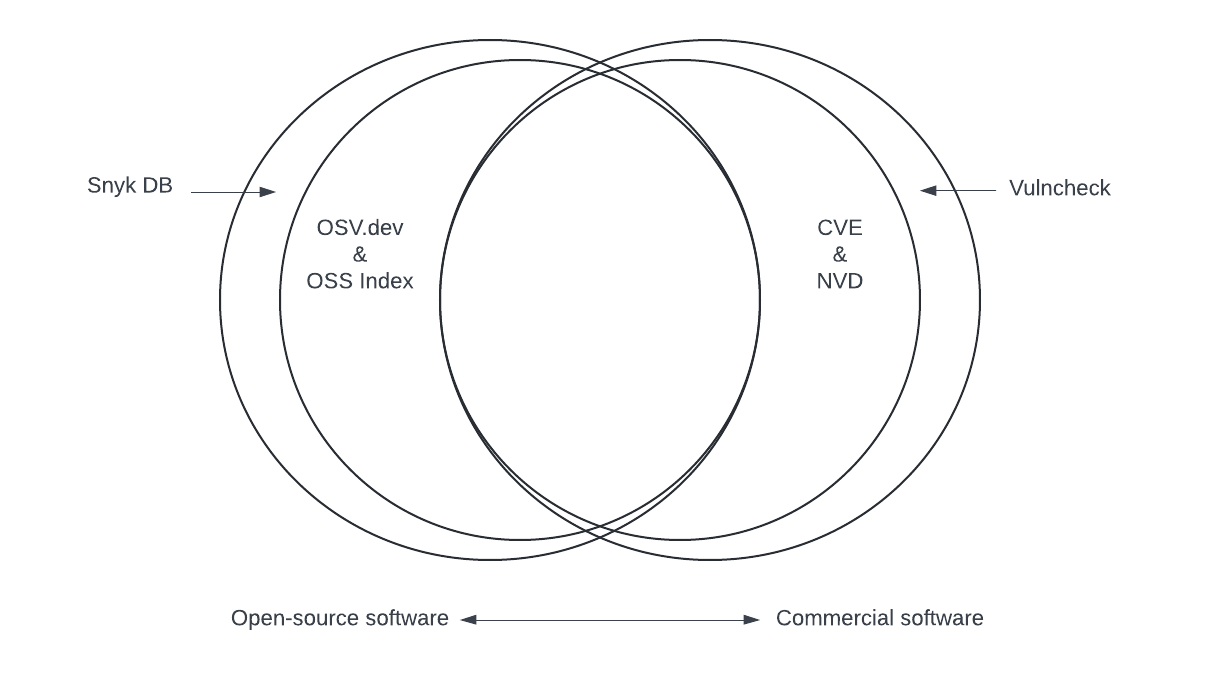
In terms of raw coverage, paid vulnerability databases have an edge due to the human analysis that happens behind the scenes. However, free projects like OSV and OSS Index still provide up-to-date and quality information on vulnerabilities that is at least as detailed as the original vulnerability disclosures.
In the long run, adoption and enhancement of open standards like the OSV format will strengthen all vulnerability databases, which will benefit the software developers and security professionals that consume the information. If you are an open-source software maintainer, please consider how you can update your release and disclosure processes to help your downstream consumers manage their vulnerable dependencies.
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.







