

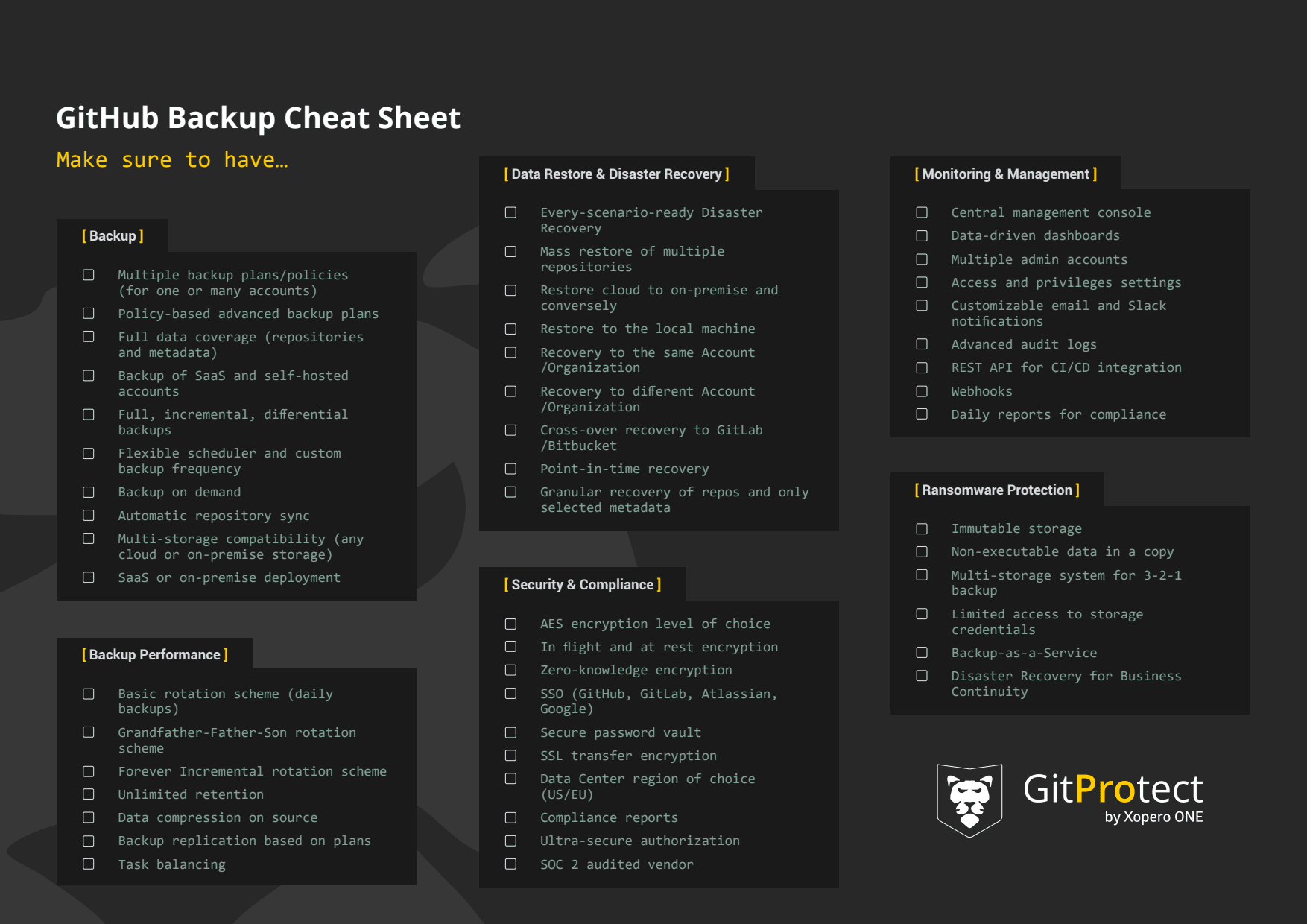
- Effective strategies require automated, comprehensive backups—including all repositories and metadata—with strong encryption, access controls, and compliance-ready retention.
- Integrate backup into CI/CD pipelines and disaster recovery plans to ensure rapid restoration and business continuity.
- Neglecting GitHub backup exposes organizations to significant operational and security risks.
In such a fast-developing world, it becomes more and more important to make sure the source code and its metadata are backed up in case of an emergency. Learn everything you need to know about how to backup a GitHub repository.

Learn more about why backup GitHub data, how to ensure GitHub data accessibility and recoverability even during serious failures, and meet the best backup and Disaster Recovery practices. Check our short guidelines on how to protect your source code, thousands of hours of work (and money), and ensure an uninterrupted development process.
Why backup GitHub data?
If you've ever asked yourself this question, you can probably imagine how much it will cost your business to lose your source code hosted on GitHub. Hard to imagine these numbers? Let's try differently: how much does one hour of GitHub downtime cost your company? Now let's take a look at the most common threats to your repositories and metadata.
But before, let’s mention that GitHub follows the so-called Shared Responsibility Model according to which the company is responsible for infrastructure-level security while data protection of the single account stays among the user’s duties. That’s why even GitHub itself recommends having third-party backup software in place.
Outages - an unpredictable threat?
Believe us or check it on yourself but longer or shorter outages occur on GitHub on a regular basis. Only mentioning March 2022, we could spot the outages that affected about 73 million users.
There was a series of outages that GitHub explained as an issue due to the “health of their database”. Most of the complaints were connected to push and pull requests that developers failed to complete. Keith Ballinger, GitHub’s Senior Vice President of Engineering even posted a blog post saying “We know this impacts many of our customers’ productivity and we take that seriously.” Finally, GitHub has made improvements to its MySQL database cluster to address this issue and eliminate the further possibility of failure. But… who knows when another similar problem will appear on the horizon.
Long-lasting GitHub outages result in limited or disabled access to the account and data. This also results in high downtime costs for your business. In such situations, GitHub backup should enable you to instantly restore your entire GitHub environment to another git hosting service (i.e. Bitbucket or GitLab), to your self-hosted GitHub or local machine, and let your team work uninterruptedly.
If you want to stay up to date, we recommend monitoring the GitHub status page for failures and incidents updates.
Human errors - insider threats
Human error is another problem that is difficult to control but highly probable—it is considered the most common cybersecurity threat of all time. It can be an intentional (e.g., malicious activity of an ex-employee) or unintentional mistake that could lead to failures and data breaches. I think we can agree with the GitGuardian team here—secret exposure is a great human mistake example. What are the others? Let’s name just a few:
- branch deletion
- old repository deletion
- push force to master
- losing/or not having a local copy
According to TechCrunch, even a GitLab sysadmin accidentally deleted a folder containing nearly 300GB of live production data, making the service unavailable for long hours. If it can happen to the biggest ones, it can happen to anyone.
Cyberattacks and ransomware - the rising threat
Do you know that ransomware attack attempts happen every 11 seconds, making a data breach response plan essential for every organization? Recently, Dropbox suffered a data breach as a result of a phishing attack. Bad actors gained access to credentials, data, and other secrets inside their internal GitHub repositories. In the last few months, the list of companies that fell victim to attacks on GitHub repositories, and as a result of a data leak, includes brands such as Toyota, Uber, Samsung, Twitch, and more.
We discussed how GitHub enterprise backup helps reduce the scale of ransomware attacks and their effects during a joint GitProtect and GitGuardian webinar, the recording of which you can watch on YouTube.
How to backup a GitHub repository
Once we understand the importance of automated backup in terms of all mentioned threats, we need to build a reliable backup and restore strategy that will allow us to restore data without affecting workflow continuity. Here we have two options. First - we can write our own, internal GitHub backup script and delegate someone from our team to monitor it on a daily basis. As it might seem a little investment of resources, in a long-term perspective it turns out to be both time and money-consuming. Oh, and did we mention we’ll need to test our restore strategy?
The second option is to use an automated, professional, third-party GitHub backup and Disaster Recovery software, like GitProtect, which enables you to set a backup policy on schedule and gives access to many professional security features.
Get 95% OFF after the 14-day free trial with the promo code: BACKUPDAY95 (valid until June 1, 2023)
Now, let’s check how to set up an efficient GitHub backup policy and what features are a must.
What data to include in your GitHub backup?
To get full assurance that the GitHub organization is secure and has the strongest protection, an enterprise should consider including all their GitHub repositories and metadata in their backup policy. To be precise, the backup should cover all the repositories, wiki, issues, projects, milestones, pipelines, issue comments, pull requests, deployment keys, webhooks, labels, pull request comments, or even Large File Storage (LFS).
Moreover, the backup software should permit the company to create different custom backup plans to meet the enterprise’s needs, workflow, structure, and safety requirements.
Unlimited retention
GitHub provides its customers with limited retention for deleted data - up to 90 days for public repos and a maximum of 400 days for private ones. Though, what if an organization needs that data for a longer period of time to meet its legal or security compliance requirements? For example, to meet SOC 2 or ISO 27001 standards? GitHub backup software should ensure you with unlimited retention, which you can use even to archive old, unused repositories for future reference, overcome GitHub storage limits, restore data from any point in time and keep your data as long as your legal recommendations require so.
Ransomware Protection
We have already mentioned that ransomware is one of the main threats the DevOps world is facing nowadays so it is worth considering a backup software equipped with some ransomware protection package. This should include immutable storage that prevents data in copies to be modified or erased.
What else? Take a look if your backup provides you with AES encryption (in flight and at rest) using your own encryption key, Data Center region of choice (for compliance purposes), and complete Disaster Recovery technology.
3-2-1 backup rule - multi-storage and replication
GitHub backup should follow the best “traditional” backup practices, and undeniably, the 3-2-1 backup rule is one of them. It states to maintain at least 3 copies of the data, keep 2 of them stored at separate locations, including 1 off-site.
To achieve this, your repository and metadata backup software should allow you to replicate the copy and add multiple data stores - both on-premise and cloud. Ideally, you can use the storage you already use, whether it's AWS Storage, Azure Blob Storage, Google Cloud, NFS, SMB, local disk resources, or others.
Backup monitoring
As mentioned before, one of the biggest pain points when it comes to GitHub backup scripts is… very time-consuming management. Third-party software has the advantage that it provides organizations with a central management console and intuitive data-driven dashboards. It should be easy to add additional admins, set roles and grant permissions to have more control over access yet share responsibilities of data protection among the team.
All automatic tools for ongoing monitoring are also important - audit logs, Slack notifications, e-mail reports with the most important data on backup processes, or compliance reports for the purposes of audits and security controls.
Proper backup monitoring can empower the DevSecOps team with appropriate control and give them the possibility to react immediately to any problem related to data protection, backup, and restore.
GitHub Enterprise Backup Considerations
GitHub Enterprise environments require specialized backup approaches that differ significantly from standard GitHub.com repositories. Enterprise deployments often involve self-hosted instances with unique infrastructure requirements, compliance mandates, and integration complexities that standard backup solutions cannot address.
Enterprise backup strategies must account for GitHub Enterprise Server's database architecture, including Git repositories, MySQL databases, and Elasticsearch indices. Organizations typically need to backup not only source code but also enterprise-specific configurations like LDAP integrations, custom authentication systems, and organizational policies. The backup process should include both hot backups for minimal downtime and cold backups for complete system snapshots.
Critical considerations include maintaining backup compatibility across GitHub Enterprise Server versions, ensuring proper encryption of sensitive organizational data, and implementing role-based access controls for backup management. Many enterprises also require geographically distributed backup storage to meet disaster recovery SLAs and regulatory compliance requirements. Unlike public GitHub repositories, enterprise backups must preserve complex permission structures, audit trails, and integration configurations that are essential for business continuity.
Automated GitHub Backup Scripts and Tools
While third-party solutions offer comprehensive features, many organizations prefer developing custom automated backup scripts tailored to their specific workflows and security requirements. These scripts can leverage GitHub's REST and GraphQL APIs to systematically backup repositories, issues, pull requests, and organizational metadata on scheduled intervals.
Effective backup automation requires implementing proper error handling, retry mechanisms, and progress tracking to ensure reliable data protection. Scripts should include functionality for incremental backups to minimize bandwidth usage and storage costs, while maintaining complete backup integrity through checksums and verification processes. Rate limiting considerations are crucial when designing automated solutions to avoid hitting GitHub's API limits during large-scale backup operations.
Popular open-source tools like github-backup-utils and custom Python scripts using PyGithub provide flexible foundations for automated backup systems. These solutions can be integrated with existing CI/CD pipelines, allowing backup processes to trigger automatically after significant repository changes or on predetermined schedules. Organizations should implement comprehensive logging and alerting mechanisms to monitor backup success rates and quickly identify potential failures in their automated backup infrastructure.
Security Implications of GitHub Backup Storage
GitHub backup storage introduces significant security considerations that organizations must address to protect sensitive source code and intellectual property. Backup repositories often contain the same secrets, API keys, and sensitive configuration data as production systems, making them attractive targets for malicious actors seeking to compromise organizational security.
Encryption at rest and in transit becomes critical when storing GitHub backups, particularly for organizations handling sensitive data or operating in regulated industries. Backup storage solutions should implement strong access controls, multi-factor authentication, and audit logging to track who accesses backup data and when. Organizations must also consider the geographic location of backup storage to comply with data sovereignty requirements and regulatory frameworks.
The shared responsibility model extends to backup security, where organizations remain responsible for protecting their backed-up data regardless of the storage provider. This includes implementing proper key management for encrypted backups, regularly testing backup integrity, and ensuring backup systems are isolated from production networks to prevent lateral movement during security incidents. Regular security assessments of backup infrastructure help identify vulnerabilities before they can be exploited by threat actors targeting valuable source code repositories.
Backup as part of the CI/CD process
The desirable DevSecOps approach is based on the need to integrate security measures throughout the entire process of software development, including securing your CI/CD pipeline against various threats. Let’s consider a backup, which enables you to quickly roll back to the previous version of the code under any circumstances—whether it is a human mistake or any other event of failure. Including backup in a well-structured CI/CD process ensures flawless and predictable delivery. It is a “set and forget” process to ensure your peace of mind.
Disaster Recovery - Warranty of DevOps continuity
And a final thing… backup is useless if you don’t have the possibility to recover your data fast. This is again one of the biggest downsides of backup scripts and DIY methods - if you need to restore the data, you need to write another script with no guarantee it will work. The advantage of the software is the fact that it guarantees Disaster Recovery technologies in case of any scenario (and as far as you know from this article, the list of them is pretty extensive).
In the event of failure, service downtime, or cyber-attack you should be able to restore your entire GitHub environment to the same or a new GitHub account, to another git hosting service provider—Bitbucket or GitLab (in case of GitHub's downtime or migration need)—or to your local machine as a file. The main goal of Disaster Recovery is to ensure your company with uninterrupted DevOps processes, guaranteeing the shortest possible downtime and avoiding financial and reputation loss.
It is also important to have a quick data recovery at hand in everyday work. Here comes a granular recovery of repositories and only selected metadata that enables you to get quick access to the data you want without the need to restore the entire GitHub environment. With point-in-time restore, you can restore data from any moment in time, from hours, a few days, or months ago.
Conclusion
DevOps security has ceased to be the responsibility of a few security specialists. More and more modern organizations aim to engage all team members and stakeholders to collaborate and proactively address security issues before software is developed and deployed. In terms of the growing cyber threat landscape and “shifting left” approach, GitHub backup of source code, as the most valuable Intellectual Property, should be considered as a key security measure to implement. But security works as a complete organism - so let's remember secret scanning, detection of security vulnerabilities, bugs, and more.
Security-first and “everyone is responsible for security” approach helps you to ship on time, increases developer productivity and as a result, provides your customers with a better and more secure experience.
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.
FAQs
Why is a dedicated GitHub backup necessary if GitHub already provides redundancy?
While GitHub maintains infrastructure-level redundancy, it operates under a shared responsibility model. Organizations are responsible for protecting their own data, including source code and metadata. Dedicated GitHub backup solutions ensure recoverability from outages, human error, ransomware, or accidental deletions—scenarios not covered by GitHub’s native redundancy.
What data should be included in a comprehensive GitHub backup strategy?
A robust backup should capture all repositories, wikis, issues, pull requests, metadata (labels, milestones, comments), deployment keys, webhooks, and LFS objects. For GitHub Enterprise, include configuration files, authentication integrations, and audit logs to ensure full recoverability and compliance.
How do backup requirements differ between GitHub.com and GitHub Enterprise Server?
GitHub Enterprise Server requires specialized backups that address self-hosted infrastructure, database snapshots, and enterprise-specific configurations such as LDAP, SSO, and custom policies. Backups must preserve permission structures, audit trails, and integration settings, while supporting both hot and cold backup methods for minimal downtime and disaster recovery.
What are the security risks associated with GitHub backup storage, and how can they be mitigated?
Backup storage often contains sensitive code and secrets, making it a high-value target. Mitigate risks by encrypting backups at rest and in transit, enforcing strict access controls, implementing MFA, and maintaining audit logs. Isolate backup systems from production networks and regularly test backup integrity to ensure resilience against compromise.
Can automated scripts provide reliable GitHub backup, or should organizations use third-party solutions?
Automated scripts using GitHub APIs can be effective for tailored workflows, but require rigorous error handling, incremental backup logic, and monitoring to ensure reliability. Third-party solutions offer advanced features like immutable storage, compliance reporting, and centralized management, reducing operational overhead for large-scale environments.
How does integrating GitHub backup into CI/CD pipelines benefit security and operational continuity?
Embedding backup processes into CI/CD pipelines ensures that critical code and metadata are captured after significant changes, reducing recovery point objectives. This integration supports rapid rollback during incidents, enhances DevSecOps practices, and helps maintain uninterrupted development workflows.







