
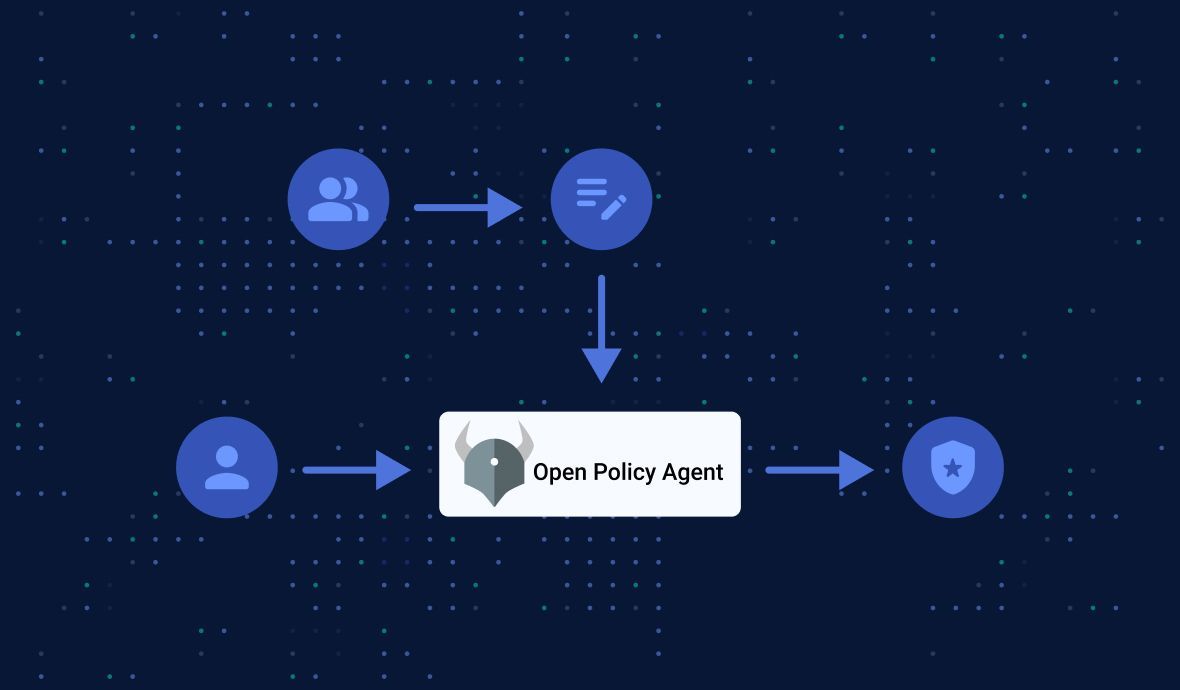

In the cloud-native era, we often hear that "security is job zero", which means it's even more important than any number one priority.
Modern infrastructure and methodologies bring us enormous benefits, but, at the same time, since there are more moving parts, there are more things to worry about: how to control access to your infrastructure? how to control access between services? who can access what? etc.
There are many questions to be answered, and these kinds of questions are policies: a bunch of security rules, criteria, and conditions. Examples:
- Who can access this resource?
- Which subnet egress traffic is allowed from?
- Which clusters a workload must be deployed to?
- Which protocols are not allowed for reachable servers from the Internet?
- Which registries binaries can be downloaded from?
- Which OS capabilities a container can execute with?
- Which times of day the system can be accessed?
All organizations have policies since they encode important knowledge about compliance with legal requirements, work within technical constraints, avoid repeating mistakes, etc.
Since policies are so important today, let's dive deeper into how to best handle them in the cloud-native era.
Why Policy-as-Code?
Policies are based on written or unwritten rules that permeate an organization's culture. For example, there might be a written rule in our organizations explicitly saying:
For servers accessible from the Internet on a public subnet, it's not a good practice to expose a port using the non-secure "HTTP" protocol.
How do we enforce it?
- If we create infrastructure manually, a four-eye principle may help. Always have a second guy together when doing something critical.
- If we do Infrastructure as Code and create our infrastructure automatically with tools like Terraform, a code review could help.
However, the traditional policy enforcement process has a few significant drawbacks:
- You can't be guaranteed this policy will never be broken. People can't be aware of all the policies at all times, and it's not practical to manually check against a list of policies. For code reviews, even senior engineers will not likely catch all potential issues every single time.
- Even though we've got the best teams in the world that can enforce policies with no exceptions, it's difficult, if possible, to scale. Modern organizations are more likely to be agile, which means many employees, services, and teams continue to grow. There is no way to physically staff a security team to protect all of those assets using traditional techniques.
Policies could be (and will be) breached sooner or later because of human error. It's not a question of "if" but "when". And that's precisely why most organizations (if not all) do regular security checks and compliance reviews, before a major release for example. We violate policies first and then create ex post facto fixes.
I know, this doesn't sound right. What's the proper way of managing and enforcing policies, then? You've probably already guessed the answer, and you are right. Read on.
What is Policy-as-Code (PaC)?
As business, teams, and maturity progress, we'll want to shift from manual policy definition to something more manageable and repeatable at the enterprise scale.
How do we do that? We can learn from successful experiments in managing systems at scale:
- Infrastructure-as-Code (IaC): treat the content that defines your environments and infrastructure as source code.
- DevOps: the combination of people, process, and automation to achieve "continuous everything", continuously delivering value to end users.
Policy-as-Code (PaC) is born from these ideas.
Policy as code uses code to define and manage policies, which are rules and conditions. Policies are defined, updated, shared, and enforced using code, and leveraging Source Code Management (SCM) tools. By keeping policy definitions in source code control, whenever a change is made, it can be tested, validated, and then executed. The goal of PaC is not to detect policy violations but to prevent them. This leverages the DevOps automation capabilities instead of relying on manual processes, allowing teams to move more quickly and reducing the potential for mistakes due to human error.
Policy-as-Code vs Infrastructure-as-Code
The "as code" movement isn't new anymore; it aims at "continuous everything". The concept of PaC may sound similar to Infrastructure as Code (IaC), but while IaC focuses on infrastructure and provisioning, PaC improves security operations, compliance management, data management, and beyond.
PaC can be integrated with IaC to automatically enforce infrastructural policies.
Now that we've got the PaC vs IaC question sorted out, let's look at the tools for implementing PaC.
Introduction to Open Policy Agent (OPA)
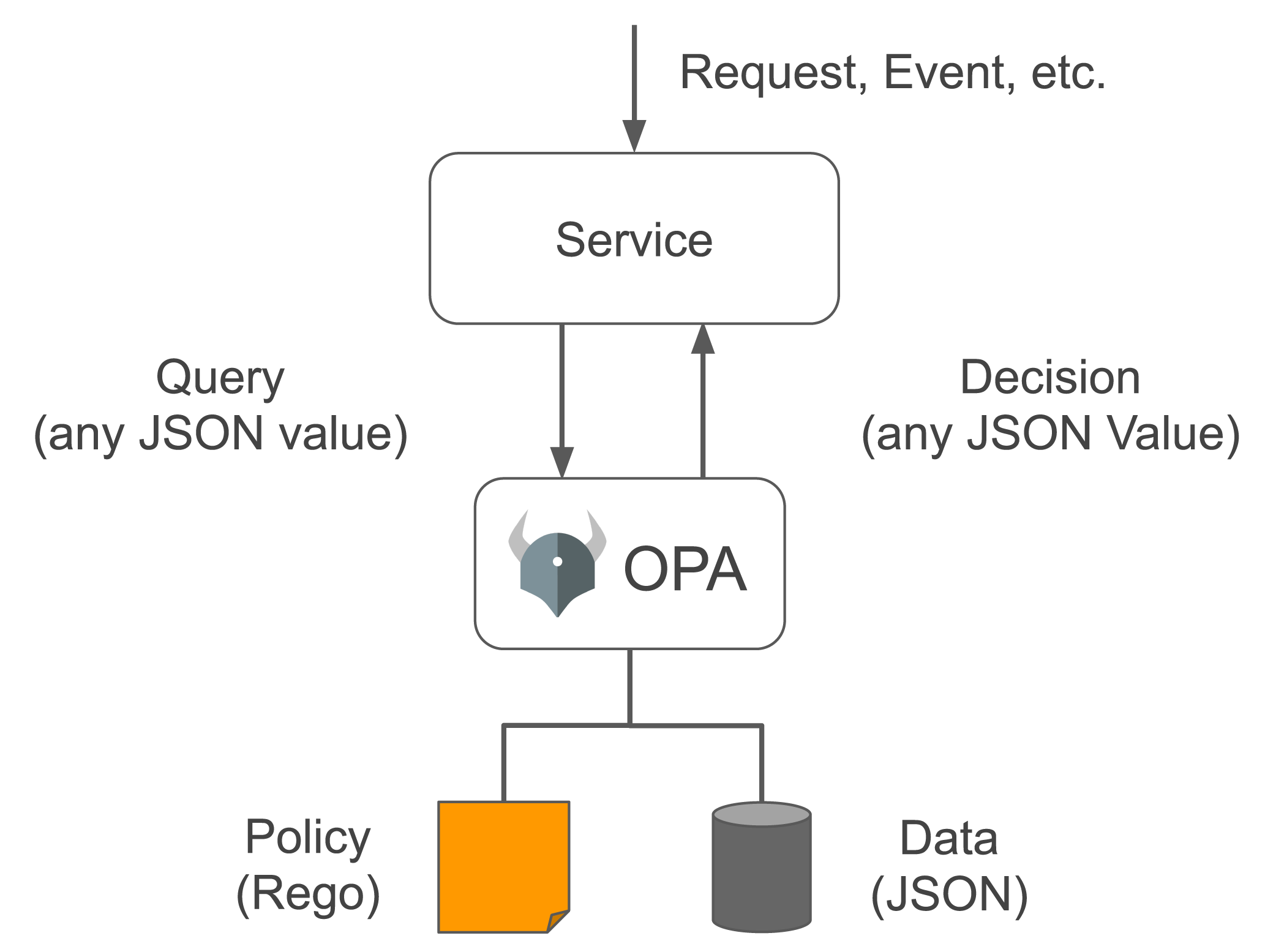
The Open Policy Agent (OPA, pronounced "oh-pa") is a Cloud Native Computing Foundation incubating project. It is an open-source, general-purpose policy engine that aims to provide a common framework for applying policy-as-code to any domain.
OPA provides a high-level declarative language (Rego, pronounced "ray-go", purpose-built for policies) that lets you specify policy as code. You can define, implement and enforce policies in microservices, Kubernetes, CI/CD pipelines, API gateways, and more.
In short, OPA works in a way that decouples decision-making from policy enforcement. When a policy decision needs to be made, you query OPA with structured data (e.g., JSON) as input, then OPA returns the decision:
OK, less talk, more work: show me the code.
Simple Demo: Open Policy Agent Example
Pre-requisite
To get started, download an OPA binary for your platform from GitHub releases:
On macOS (64-bit):
curl -L -o opa https://openpolicyagent.org/downloads/v0.46.1/opa_darwin_amd64
chmod 755 ./opaTested on M1 mac, works as well.
Spec
Let's start with a simple example to achieve an Access Based Access Control (ABAC) for a fictional Payroll microservice.
The rule is simple: you can only access your salary information or your subordinates', not anyone else's. So, if you are bob, and john is your subordinate, then you can access the following:
/getSalary/bob/getSalary/john
But accessing /getSalary/alice as user bob would not be possible.
Input Data and Rego File
Let's say we have the structured input data (input.json file):
{ "user": "bob",
"method": "GET",
"path": ["getSalary", "bob"],
"managers": {
"bob": ["john"]
}
}And let's create a Rego file. Here we won't bother too much with the syntax of Rego, but the comments would give you a good understanding of what this piece of code does:
File example.rego:
package example
default allow = false # default: not allow
allow = true { # allow if:
input.method == "GET" # method is GET
input.path = ["getSalary", person]
input.user == person # input user is the person
}
allow = true { # allow if:
input.method == "GET" # method is GET
input.path = ["getSalary", person]
managers := input.managers[input.user][_]
contains(managers, person) # input user is the person's manager
}Run
The following should evaluate to true:
./opa eval -i input.json -d example.rego "data.example"Changing the path in the input.json file to "path": ["getSalary", "john"], it still evaluates to true, since the second rule allows a manager to check their subordinates' salary.
However, if we change the path in the input.json file to "path": ["getSalary", "alice"], it would evaluate to false.
Here we go. Now we have a simple working solution of ABAC for microservices!
Policy as Code Integrations
The example above is very simple and only useful to grasp the basics of how OPA works. But OPA is much more powerful and can be integrated with many of today's mainstream tools and platforms, like:
- Kubernetes
- Envoy
- AWS CloudFormation
- Docker
- Terraform
- Kafka
- Ceph
And more.
To quickly demonstrate OPA's capabilities, here is an example of Terraform code defining an auto-scaling group and a server on AWS:
With this Rego code, we can calculate a score based on the Terraform plan and return a decision according to the policy. It's super easy to automate the process:
terraform plan -out tfplanto create the Terraform planterraform show -json tfplan | jq > tfplan.jsonto convert the plan into JSON formatopa exec --decision terraform/analysis/authz --bundle policy/ tfplan.jsonto get the result.
If you want to get started with OPA and Kubernetes, check out my two-part tutorial below. Hope to see you there!
 Guest Expert
Guest Expert
 Guest Expert
Guest Expert
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.








