

Wake-up call: why it's urgent to deal with your hardcoded credentials and secrets
The figures are precise: stolen credentials remain the most common cause of a data breach. So how are there still thousands of hardcoded secrets hiding in source code, CI/CD pipelines, or Docker images, and, more importantly, how should we deal with them?
It is clear today that the year 2021 will go down in the annals of IT security as the year when organizations became aware of their inevitable dependence on open-source and, more importantly, of the risks posed by unsupervised supply chains.
High-profile security incidents like the SolarWinds, Kaseya, and Codecov data breaches have shaken enterprises’ confidence in the security practices of third-party service providers.
Today corporations, open source projects, nonprofit foundations, and even governments are all trying to figure out how to improve the global software supply chain security. While these efforts are more than welcome, for the moment, there is hardly any straightforward way for organizations to improve on that front.
On the other hand, despite being primarily acknowledged as one of the most common entry points for hackers, a vulnerability remains largely unwatched: hardcoded credentials in source code.
In this article, we want to defend a simple fact: focusing on what you can control now can significantly improve your organization's security posture.
You can and should start tackling hardcoded secrets now. Here's why.
Hardcoded secrets have never been easier to find
On July 3, 2022, the CEO of crypto-currency giant Binance warned of a massive breach:
Our threat intelligence detected 1 billion resident records for sell in the dark web, including name, address, national id, mobile, police and medical records from one asian country. Likely due to a bug in an Elastic Search deployment by a gov agency. This has impact on ...
— CZ 🔶 Binance (@cz_binance) July 3, 2022
The bug? A fragment of source code containing the secret for a titanic database of personal information was allegedly copied and pasted onto a developer's blog of the Chinese CSDN network. Source

Whether secrets have been left in code because of malintent or negligence, they are always a boon for hackers. All sorts of playbooks can be deployed upon finding leaked credentials, even the most innocuous ones, such as a Twitter API key: from phishing to privilege escalation and data exfiltration.
Secrets (username and passwords, API tokens, encryption keys, etc.) are the most sought-after digital assets for cybercriminals, and they have never been easier to find: last year, we detected that 6 million secrets were pushed (mostly inadvertently) as commits on public GitHub, twice the amount detected in 2020. According to the latest DBIR report, the “use of stolen credentials” is the most common way to breach web applications, with more than 80% of the breaches attributed to this attack vector. In comparison, “vulnerability exploitation” is directly responsible for less than 20% of the cases.
The tactic of using stolen credentials was particularly persistent in BWAA (Basic Web Application Attacks), which the DBIR team defined as an actor "directly" targeting exposed instances, such as web servers and email servers. They also referred to it as a "low-cost, high-pay-off strategy," which is attractive to an array of attackers.
Source
Of course, here, the term "stolen credentials" encompasses a variety of cases, including probably phishing and user info bought on the dark web. But if we consider an organization crafting digital services and products, this conclusion applies to hardcoded secrets. In fact, for a code-producing organization, keeping secrets out of source code should be as evident as implementing SSO and MFA.
In the same report, we can read that:
There’s been an almost 30% increase in stolen credentials since 2017, cementing it as one of the most tried-and-true methods to gain access to an organization for the past four years.
Another report from IBM came to the same conclusion:
Use of stolen or compromised credentials remains the most common cause of a data breach. Stolen or compromised credentials were the primary attack vector in 19% of breaches in the 2022 study and also the top attack vector in the 2021 study, having caused 20% of breaches. Breaches caused by stolen or compromised credentials had an average cost of USD 4.50 million. These breaches had the longest lifecycle — 243 days to identify the breach and another 84 days to contain the breach. Phishing was the second most common cause of a breach at 16% and also the costliest, averaging USD 4.91 million in breach costs.
How to explain then that hardcoded secrets is still one of the most overlooked vulnerabilities in the application security space? We have come to the conclusion that hardcoded secrets are still poorly understood compared to other application security vulnerabilities.
Understanding CWE-798: The Technical Classification of Hardcoded Credentials Vulnerability
The hardcoded credentials vulnerability is formally classified as CWE-798 in the Common Weakness Enumeration database, representing a Base-level weakness that affects authentication mechanisms across software systems. This classification distinguishes between two critical variants: inbound authentication, where products contain hard-coded credentials for user access (such as default administrative accounts), and outbound authentication, where applications store fixed credentials for connecting to backend services or APIs.
Unlike runtime vulnerabilities that require active exploitation of running software, CWE-798 represents a static weakness embedded directly in source code, configuration files, or compiled binaries. This fundamental difference makes hardcoded credentials particularly dangerous because they remain exploitable regardless of whether the application is actively running. The weakness spans multiple dimensions including behavior (authentication bypass), property (credential storage), and technology (affecting any system requiring authentication), making it one of the most persistent and widespread security vulnerabilities in modern software development.
Secrets are not a runtime vulnerability (they’re much worse)
Looking at the 2022 CWE Top 25 Most Dangerous Software Weaknesses list, we can see that "Use of Hard-coded Credentials" (CWE-798) is in position 15, up from 16 in the previous year. But the most interesting fact here is not so much the ranking: it is that, unlike all the other "weaknesses" on the list, the use of hardcoded secrets is not an execution vulnerability. In other words, it doesn't require running software to be a vulnerability.
When we hear about application vulnerabilities, we are used to thinking about Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), XML External Entity (XXE), logic flaws, etc. They all require the software to be running to be exploited. With hardcoded secrets, it's the source code itself that can be exploited. Therefore, your attack surface comprises your repositories and your entire software factory. This is a truly unique characteristic that has big implications.
First, hardcoded secrets go where source code goes, making tracking almost impossible. Source code is usually cloned, checked out, and forked multiple times a month on machines inside or outside an organization's perimeter—not to mention leakage incidents.
Leaks do happen. Last year, after their codebases were exposed publicly, we examined Twitch and Samsung’s repos with the same tool we use to protect our clients. In both cases, we found between 6,500 to 7,000 secrets ready to be employed: from company email passwords to cloud services API keys, third-party tokens, or internal services authentication. If this also happened to NVIDIA and Microsoft, do you think it can’t happen to your organization?
Second, let's not forget that code under VCS control has a permanent history. A VCS such as git will keep track of any modifications done to a codebase and is also used to propagate these changes. Coupled with the fact that hardcoded credentials will be exploitable as long as they are not revoked, it means that still-valid secrets can be hiding anywhere on the VCS historical timeline. This opens a new dimension to the attack surface that most security analyses will never see because they are only concerned with a codebase's current, ready-to-be-deployed state.
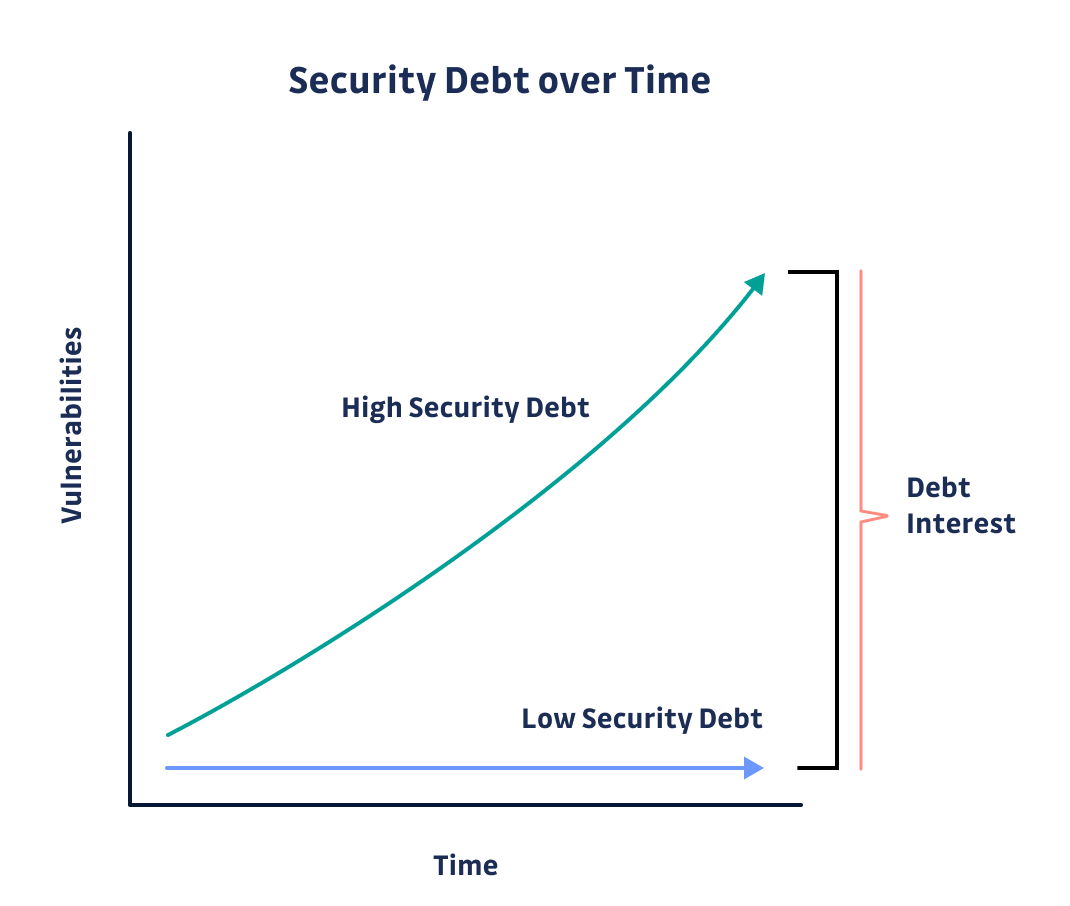
Hardcoded credentials accumulate in time, unlike any other kind of vulnerability. Much like technical debt, managing this vulnerability is a Tetris game: “It’s ok if it builds up a bit, as long as you plan to reduce it later.” Except you don’t see the bricks until you put detection in place. And the more developers (in the past, present, or future), the higher the probability that a secret has been or will be committed. The bigger the codebase, the higher the number of potentially exploitable secrets. Past a certain point, it simply becomes unmanageable.
From our own report, this is the average situation a typical software shop will be facing:
On average, in 2021, a typical company with 400 developers and 4 AppSec engineers would discover 1,050 unique secrets leaked upon scanning its repositories and commits. With each secret detected in 13 different places on average, the amount of work required for remediation far exceeds current AppSec teams' capabilities (1 AppSec engineer for 100 developers).
Attack Vectors and Exploitation Methods for Hardcoded Credentials
Attackers employ various sophisticated techniques to discover and exploit hardcoded credentials vulnerability instances across different attack surfaces. Source code repositories represent the primary target, where automated scanning tools can identify API keys, database passwords, and authentication tokens committed to version control systems. Beyond repositories, attackers examine compiled binaries through reverse engineering, configuration files in deployment packages, and even developer documentation that inadvertently exposes credential patterns.
The exploitation process often involves credential stuffing attacks, where discovered credentials are tested across multiple systems and services within an organization's infrastructure. Attackers leverage the fact that developers frequently reuse similar credential patterns or default values across different environments. Once valid credentials are identified, threat actors can escalate privileges, move laterally through networks, or establish persistent access through backdoor accounts. The attack surface extends beyond the immediate application to include CI/CD pipelines, container images, and infrastructure-as-code templates where hardcoded secrets commonly proliferate throughout the software development lifecycle.
How to avoid hardcoded secrets?
What actions can you take? Implement the proper controls to stop credentials from entering into the codebase in the first place (we often use the analogy “stop the bleeding”). Catching hardcoded secrets in real-time is the best way to curb the progress of secrets sprawl. Catch them before they leave the developer's workstation and reach shared repositories.
Let’s take a concrete example: a developer accidentally commits a secret in his local working environment. If he’s alerted at that moment, the unitary cost of remediation is less than a minute. The credential has only been exposed on the local workstation, and the developer can run a few commands to "amend" their commit. Conversely, if the credential reaches the central repository, it should be considered compromised since it became available to anyone with read access, unauthorized developers, and potential APTs. From that point, a complete remediation cycle should be triggered.
Revoking and rotating keys typically involve multiple teams. A developer will probably need to address a request to a Cloud Ops team, who will, in turn, have to halt a few workflows in the process, such as CI/CD pipelines or even production workers.
Time adds up quickly and in our experience average cost of remediation is often at least in the 2 man-hours ballpark.
The maths are straightforward: for a 400 developers shop where we uncovered 1,050 unique secrets, we can approximate that at least 2,100 man-hours would be required to reach “zero hardcoded secrets”—assuming that no more secrets would leak in the future!
Remediating hardcoded secrets
The bottom line is that your ROI will be much better by starting small and tackling the most severe incidents than by trying to fix everything from the start (e.g., the entire stack of past incidents).
Once you feel ready to tackle this issue, look at the recommendations in the guide below on how application security teams can effectively prioritize, investigate and remediate hardcoded secrets incidents:
 Ziad Ghalleb
Ziad Ghalleb
Detection Strategies and Automated Scanning Approaches
Implementing comprehensive detection strategies for hardcoded credentials vulnerability requires a multi-layered approach that addresses both historical and real-time security concerns. Static analysis tools must scan entire codebases including commit history, as credentials embedded in previous versions remain exploitable even after removal from current code. Effective detection systems employ pattern recognition algorithms that identify high-entropy strings, common credential formats, and API key structures while minimizing false positives through contextual analysis.
Modern detection frameworks integrate directly into development workflows through pre-commit hooks, CI/CD pipeline scanning, and IDE plugins that alert developers before credentials reach shared repositories. Advanced scanning techniques include semantic analysis that understands code context, machine learning models trained on credential patterns, and behavioral analysis that identifies suspicious authentication flows. Organizations should implement continuous monitoring that extends beyond source code to include configuration management systems, deployment artifacts, and runtime environments where credentials might be inadvertently exposed through logging or error messages.
Don’t sleep on secrets
Keeping up with cybersecurity threats in real-time is not just tricky; it is impossible. Not only do new adversaries and TTP emerge daily, but in recent years the bar to a successful attack has been lowered so much that it is not a surprise anymore to see teenagers take over some of the biggest tech companies.
We reckon information security is a complex field, and no decision should be made based on opinions, intuition, or fear. But we think that too often, the basics can be overlooked, although they are consistently pointed out as the root cause of most breaches. For organizations where developers write code, secrets must be well supervised so as not to offer low-hanging fruits to malicious people.
There is an urgency to deal with hardcoded secrets because the more an organization waits, the riskier the situation gets and the costlier the security debt.
FAQ
Why is the hardcoded credentials vulnerability (CWE-798) considered more dangerous than typical runtime vulnerabilities?
The hardcoded credentials vulnerability is dangerous because it is embedded directly in source code or configuration files, making secrets exploitable even when the application is not running. Unlike runtime vulnerabilities, these credentials persist in version control history and deployment artifacts, significantly expanding the attack surface and increasing the risk of unauthorized access.
How do attackers typically discover and exploit hardcoded credentials in modern development environments?
Attackers use automated tools to scan source code repositories, binaries, and configuration files for secrets such as API keys and passwords. Once discovered, these credentials are leveraged in credential stuffing, privilege escalation, or lateral movement attacks. The proliferation of CI/CD pipelines and multi-cloud deployments further increases exposure points for exploitation.
What strategies can security teams implement to detect and remediate hardcoded credentials vulnerability at scale?
Effective strategies include integrating static analysis tools into CI/CD pipelines, scanning both current code and commit history, and deploying pre-commit hooks to catch secrets before they reach shared repositories. Automated detection should be complemented by robust remediation workflows, including secret rotation and incident response coordination across teams.
Why is it critical to address hardcoded secrets early in the development lifecycle?
Remediating hardcoded secrets at the developer workstation stage is far less costly and complex than after secrets reach central repositories. Early detection minimizes the risk of credential compromise, reduces incident response overhead, and prevents the accumulation of security debt that can overwhelm AppSec teams as organizations scale.
How does version control history contribute to the persistence of hardcoded credentials vulnerability?
Version control systems retain the full history of code changes, including any secrets that were ever committed—even if later removed. This means that valid credentials can remain accessible in historical commits, making comprehensive scanning and remediation of the entire repository history essential for effective risk mitigation.
What are the best practices for preventing hardcoded secrets from entering codebases?
Best practices include enforcing secrets management policies, leveraging dedicated vault solutions, integrating automated secrets detection into developer workflows, and providing developer education on secure authentication patterns. Continuous monitoring and incident response readiness are also key to maintaining a secrets-free codebase.









