


This is the third blog post in a series that is taking a deep dive into DevSecOps program architecture. The goal of this series is to provide a holistic overview of DevSecOps as a collection of technology-driven, automated processes. Make sure to check out the first and second parts too!
At this point in the series, we have covered how to manage existing vulnerabilities and how to prevent the introduction of new vulnerabilities. We now have a software development lifecycle (SDLC) that produces software that is secure-by-design. All we have left to cover is how to enforce and protect this architecture that we’ve built.
In this article, we will be learning how to add integrity and security to the systems involved in our SDLC. These processes should be invisible to our software engineers. They should simply exist as guardrails that ensure the rest of our architecture is utilized and not interfered with.
With that in mind, I want to reiterate my DevSecOps mission statement:
“My job is to implement a secure-by-design software development process that empowers engineering teams to own the security for their own digital products. We will ensure success through controls and training, and we will reduce friction and maintain velocity through a technology-driven, automated DevSecOps architecture.”
 Software Architect (51-1000 employees)
Software Architect (51-1000 employees)
Threat landscape
Whenever we talk about securing something, we need to answer the question, “From what?” Threat modeling is the practice of identifying things that could go wrong based on what we are trying to protect and who/what we are protecting it from. We can’t possibly cover every scenario, but in the context of our DevSecOps architecture there are a handful of threats that we should be considering broadly.
The diagram below is a threat model of the software development process that I like a lot:
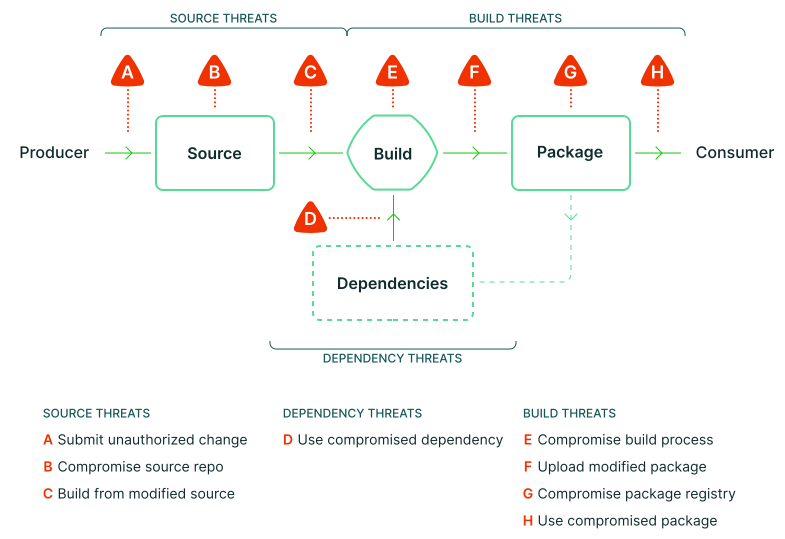
Of the threats listed above, “use compromised dependency” (Threat D) is the most challenging to mitigate. We usually have little control over the external dependencies that we use in our code. The xz utils backdoor was an eye-opening spotlight on the widespread impact that a single compromised dependency can have.
Unfortunately, malicious insiders in the open-source ecosystem are an unsolved problem at this time. Personally, I don’t think anything will improve until well-resourced consumers of open-source software become more involved in improving the security and support of their open-source dependencies.
In this article, we will be focusing on the things that we can control. For dependency threats, we can look out for malicious look-alike packages, and we can use SCA tools to identify when we are using outdated, vulnerable versions of our dependencies.
In the following sections, we will explore ways to mitigate source threats and build threats through integrity checks. Then, we will examine the assumptions we are making about the integrity checks and discuss how we can use security to build trust in those assumptions.
Pipeline integrity
When we think about integrity in software, we often default to thinking of it as signing binaries. In our DevSecOps architecture, we go beyond verifying individual software artifacts. We need to be able to verify the integrity of our pipeline. You might be wondering, “We set up the software development pipeline ourselves… Why would we need to verify its integrity?” It turns out that the assumptions we make about our SDLC can be wrong. We have security gates, but that doesn’t guarantee that we have no gaps.
In software development environments, there are usually ways to skip steps or bypass controls. For one, it’s common for software engineers to be able to publish artifacts like container images directly to our registry. Even innocent intentions can help vulnerabilities slip around security checks that would have otherwise caught them. In a worse scenario, a compromised developer account could allow a threat actor to push backdoored packages directly to our registry.
To verify that our software artifacts are the product of the DevSecOps systems that we have in place, we must improve the integrity of our software development pipeline.
Branch protection
One of the most important controls in our software development pipeline is branch protection. Branch protection rules protect our integrity against the source threats in our threat model (Figure 1).
By requiring a Pull Request (PR) to merge code into our production branch, we are ensuring that humans are authorizing changes (Threat A) and verifying that the source code is free from vulnerabilities and backdoors (Threat B). We can also trigger automatic builds when there are changes to our production branch, which will produce builds that come from the source code that has been reviewed (Threat C).
Reproducible builds
In the Solarwinds supply chain attack, it was the compromise of Solarwinds’ build servers that led to the injection of the Sunburst backdoor. Injecting malicious code late in the software development pipeline is an effective way to reduce the chance that a human will catch the backdoor.
In the long run, the best mitigation strategy we have against compromised builds (Threat E) is to make our software builds reproducible. Having reproducible builds means that we can run the same steps against the same source code on a different system and end up with the exact same binary result. We would then have a way to verify that a binary was not tampered with. If we rebuilt and the resulting binary was different, it would raise some questions and warrant investigation.
Artifact signing
Signing software has been a common practice for a long time because it provides a way for consumers to verify that the software came from us. This protects software consumers even if our package registry is compromised (Threat G).
Unfortunately, this still leaves us with a lot of assumptions because a binary signature doesn’t say anything about how the software was built. For example, a software engineer or threat actor might have write access to our container registry and the ability to sign container images. By pushing a locally built container image directly to our registry, they would still be bypassing the automated checks and human reviews that happen in our PRs.
SLSA framework
To provide a way for us to verify how and where a piece of software was built, the Open Source Security Foundation (OpenSSF) created the Supply-chain Levels for Software Artifacts (SLSA) framework. What does SLSA do for us in practice? If we reuse the earlier example of a software engineer pushing a container directly to our registry, we could have a verification step before deployment that would detect that the container wasn’t built in our CI pipeline.
SLSA ranks our software build process on a 0-3 scale to determine how verifiable it is. A whole article could be written about SLSA, but to keep things short, here is a summary of the 4 levels and what they aim to protect against:
Level 0 – Nothing is done to verify the build process. We don’t have any way to verify who built the software artifact nor how they built it.
Level 1 – Software artifacts are distributed with a provenance that contains detailed information about the build process. Before using or deploying the software, we can use the information in the provenance to make sure that the components, tools, and steps used in the build are what we expect.
Level 2 – The provenance is generated at build time by a dedicated build platform that also signs the provenance. Adding a signature to the provenance allows us to verify that the documentation came from our build platform and hasn’t been forged nor tampered with.
Level 3 – The build platform is hardened to prevent the build process from having access to the secret used to sign the provenance. This means that a tampered build process cannot modify the provenance in a way that would hide its anomalous characteristics.
At SLSA level 3, we have a way to verify that we aren’t falling for build threats E-H in our threat model (Figure 1). However, you might notice that we start placing some trust in the build platform to be hardened in an adequately secure way.
Trust in the platforms that make up our SDLC is one of the guiding principles of SLSA. The purpose of SLSA is to verify that our software artifacts came from the expected systems and processes rather than individuals with write access to our package registries. How do we build trust in the systems that produce our software? By securing them.
Pipeline security
Our DevSecOps architecture is technology-driven, which means there are multiple systems that compose our software development pipeline. At this point in our DevSecOps journey, we have confidence that our SDLC is producing reasonably secure software, and we have ways to verify that our pipeline is being used and not skipping steps. The final threat we have to deal with is the compromise of our deployed services or the systems involved in our software development pipeline.
Securing development systems
If a system involved in development or CI gets compromised by a threat actor, they may be able to inject backdoors into our software, steal secrets from our development environment, or even steal data from the downstream consumers of our software by injecting malicious logic. It’s common for us to put a lot of energy into securing the production systems that we deploy our software to, but we need to treat the systems that build our software like they are also production systems.
Workstation security
On the “left” side of our SDLC, our developers are writing code on their workstations. This isn’t an article about enterprise security, but endpoint protection solutions such as antivirus and EDR play an important role in securing these systems. If we are concerned about our source code being leaked or exfiltrated, we might also consider data-loss prevention (DLP) tools or user and entity behavior analytics (UEBA).
Remote development
If we want to go a step further in protecting our source code, we can create remote development environments that our developers use to write the code. Development tools like Visual Studio Code and Jetbrains IDEs support connecting to remote systems for remote development. This is not the same thing as dev containers which can run on our local host. Remote development refers to connecting our IDE to a completely separate development server that hosts our source code.
This isolation of the software development process separates our source code from high-risk activity like email and browsing the internet. We can combine remote development with a zero-trust networking solution that requires human verification (biometrics, hardware keys, etc) to connect to the remote development environment. If a developer’s main device gets compromised, remote development makes it much harder to steal or tamper with the source code they have access to.
Remote development obviously adds friction to the software development process, but if our threat model requires it, this is a very powerful way to protect our source code at the earliest stages of development.
Build platform hardening
The SolarWinds supply chain attack that we covered earlier is a prime example of why we need to treat build systems with great scrutiny. Reproducible builds are a way to verify the integrity of our build platform, but we still want to secure these systems to the best of our ability.
Similarly to workstation security, endpoint protection and other enterprise security solutions can help monitor and protect our build platform. We can also take additional steps like limiting administrator access to the build platform and restricting file system permissions.
Securing deployment systems
If our software is deployed as a service for others to use, we need to make sure that we are securing our deployment systems. A compromised service can leak information about our users and allow a threat actor to pivot to other systems.
Zero-trust networking
A powerful control against the successful exploitation of our applications is restricting outbound network access. Historically, it’s been very common for public-facing applications to be in a DMZ, a section of our internal network that can’t initiate outbound network connections to the internet or any other part of our network (except for maybe a few necessary services). Inbound connections from our users are allowed through, but in the event of a remote code execution exploit, the server is unable to download malware or run a reverse shell.
If we use Kubernetes for our container workloads, we can utilize modern zero-trust networking tools like Cilium to connect our services and disallow everything else. Cilium comes with a UI called Hubble that visualizes our services in a diagram to assist us in building and troubleshooting our network policies.
Privilege dropping and seccomp
If we run our services inside Linux containers, we can easily limit their access to various system resources. Seccomp is a Linux kernel feature that works with container runtimes to restrict the syscalls that can be made to the kernel. By default, most container deployments run using “Unconfined” (seccomp disabled) mode.
At a minimum, we can use the “RuntimeDefault” seccomp filter in Kubernetes workloads to utilize the default seccomp profile of our container runtime. Here is an example of the syscalls blocked by Docker’s default seccomp filter. The list of syscalls in a default filter are typically blocked to prevent privilege escalation from the container to the host. There may be certain low-level or observability workloads that do need to run “unconstrained,” but in general, the default seccomp filter is intended to be safe for most applications.
If we wanted to be even more restrictive, we could create our own seccomp filters that only allow the syscalls needed by our application. In some cases, restricting syscalls at this level could even prevent the successful exploitation of a vulnerable system. I did a talk on this back in 2022 that explains how to automate the creation of seccomp allowlist filters in a way that fits nicely into existing DevOps workflows. Be aware, however, that seccomp allowlist filters can introduce instability into our application if we aren’t performing the necessary testing when creating the filter.
Container drift monitoring
Another powerful security feature that container deployments enable is container drift monitoring. Many container applications are “stateless,” which means that we wouldn’t expect them to be changing in any way. We can take advantage of this expectation and monitor our stateless containers for any drift from their default state using tools like Falco. When a stateless container starts doing things that it wouldn’t normally do, it could indicate that our app has been exploited.
Identity
Lastly, let’s look at a few identity-related practices that can meaningfully improve the security of the systems in our software development pipeline.
Secrets management
There is a lot of complexity in DevSecOps around identity and access management because we are dealing with both human and machine identities at multiple stages of our SDLC. When our services talk to one another, they need access to credentials that will let them in.
Managing the lifecycle of these credentials is a bigger topic than what we will be covering here, but having a strategy for secret management is one of the most important things we can do for the security of the systems in our SDLC. For detailed advice on this topic, check out GitGuardian’s secret management maturity model whitepaper.
Leaked secret prevention
No matter how mature our secret management process is, secrets always seem to find a way into places they shouldn’t be. Whether they are in source code, Jira tickets, chats, or anywhere else, it’s impossible to prevent all our secrets from ever being exposed. For that reason, it’s important to be able to find secrets where they shouldn’t be and have a process to rotate leaked secrets so they are no longer valid.
Honeytokens
Leaked secrets are a very sought-after target for threat actors because of their prevalence and impact. We can take advantage of this temptation and intentionally leak special secrets called honeytokens that would never be used except by malicious hackers that are looking for them. By putting honeytokens in convincing locations like source code and Jira tickets, we are setting deceptive traps with high-fidelity alerts that catch even the stealthiest attackers.
Others
We could list more ways to secure our infrastructure, but, like I said earlier, this isn’t an article about enterprise security. The topics we covered were included because of the special considerations we must take in the context of the software development environment.
Ultimately, collaboration between product and enterprise security is an important factor in protecting the integrity of our DevSecOps architecture. It is our collective duty to prevent threats from impacting us and those downstream who use our software products.
Conclusion
DevSecOps architecture is driven by the technologies involved in the development process. Securing these systems builds trust in our software development pipeline, and adding ways to verify the integrity of our pipeline is what ultimately allows us to mitigate many of the supply-chain threats that we and our customers face.
There will always be new things to learn and new ways to iterate on these strategies. The DevSecOps architecture described in this series is meant to provide a holistic and modern approach to application security that can be built upon. I hope that you are leaving with goals that will set your development teams up for success in securing their digital products.
Read more articles from these series:
 Guest Expert
Guest Expert Guest Expert
Guest Expert
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.









{kind=link}