


This is the first blog post in a series that will take a deep dive into DevSecOps program architecture. The goal of this series is to provide a holistic overview of DevSecOps as a collection of technology-driven, automated processes. What are the tools and technologies that play a role in DevSecOps? How can we use technology to set software engineering teams up for success? How do we align roles and responsibilities to ensure cohesion, safety, and velocity? These are some of the questions that will be answered as we progress through the series.
I’ve spent the last 3 years in my professional role building the DevSecOps program at my company from the ground up. There will be parts of this series that may not apply directly to your company, but the themes and overall approach may still be valuable to you. The following mission statement summarizes my approach to DevSecOps:
“My job is to implement a secure-by-design software development process that empowers engineering teams to own the security for their own digital products. We will ensure success through controls and training, and we will reduce friction and maintain velocity through a technology-driven, automated DevSecOps architecture.”
Vulnerability management overview
In this post, we will be examining how technology can support the “people and processes” side of DevSecOps. Controls and automation will increasingly play a role in this series, but we need to start by defining the roles and responsibilities of the humans involved.

At its core, DevSecOps is about managing vulnerabilities within software products. Some of these vulnerabilities are introduced by the software engineers creating the product, and others come from third-party dependencies that teams have little control over. The work needed to remediate these vulnerabilities must compete with other work like new features and bug fixes. In this blog post, we will look at a technology-driven vulnerability management lifecycle that allows informed decisions to be made about work selection.
Stages of vulnerability management
The vulnerability management process can be broken down into 3 stages: Identification, Observability, and Management. Each stage is critical for the success of the next one. Below is a simplified diagram that we will add to as we go through this article. Technology plays a central role in each stage, but humans are an important part of this process as well.

Identification
This probably goes without saying, but you can’t fix vulnerabilities that you aren’t aware of. Identifying vulnerabilities is a complex challenge, though. It’s not just a matter of scanning source code; there are many artifacts in the layers of a software product that require their own type of vulnerability scanner.
The first stage of our diagram is a list of places in the software development lifecycle (SDLC) where vulnerabilities or misconfigurations can arise, as well as the types of vulnerability scanning tools that can identify security issues in these areas. Here’s a quick rundown of each area:

Version Control System
GitHub is an example of a VCS, and it is often overlooked as an area that can create security risks. Things like misconfigured actions and poor access control can allow attackers to gain read access to internal code or even the ability to inject malicious code.
Code
In this context, “Code” refers to the custom code that was written by the software engineers at your own company. Vulnerability scanners such as SAST and DAST (Static/Dynamic Application Security Testing) can identify various vulnerabilities that were accidentally created in the code. But they can’t catch everything, which is why we have other specialized tools for vulnerability identification.
Secrets
Finding and preventing leaked secrets is what GitGuardian is all about. Hackers and red teamers regularly find secrets in plain text that allow them to elevate their access. Identifying leaks and prioritizing their cleanup is a critical piece of DevSecOps.
Dependencies/SBOM
SBOM stands for Software Bill of Materials, and it refers to a document containing all the third-party dependencies in your code. Why would you want to track software dependencies? New vulnerabilities emerge every day in open-source code. If your software uses a vulnerable dependency, it may also be exploitable. Software Composition Analysis (SCA) tools identify vulnerabilities in the dependencies you use.
IaC
Infrastructure-as-Code (IaC) refers to deployment code such as Terraform or Kubernetes that declaratively defines how your deployment will be configured. IaC scanners identify security misconfigurations and unsafe exposure in your planned deployments.
Containers
Containers add another layer of dependencies to your software, because they provide all the operating system programs that your code needs to run. These added dependencies can also introduce security issues into the runtime of your application. Container image scanners help you identify these kinds of issues.
Deployment
Application deployments are the final area that we will cover. If you run your app in the cloud, you can use Cloud-Native Application Protection Platform (CNAPP) or Cloud Security Posture Management (CSPM) tools to identify misconfigurations and known vulnerabilities in your deployed application. Pentesting your live applications is another way to find previously undiscovered vulnerabilities. Human-operated security testing is the only way to find some kinds of vulnerabilities, such as business logic flaws.
This list may not be exhaustive, and new threats and tools are emerging all the time. But this highlights the plethora of vulnerability types that we’re dealing with. The complexity of security scanners is the first major challenge of vulnerability management. There are many things that need to be evaluated for security issues, and no single tool can do it all. If you have coverage in all these areas, you will likely end up with a mix of sources that identify vulnerabilities. This can get messy, which is what leads us to the next stage of our process.
Observability
Once we have identified vulnerabilities, we need to make sense of the noise. The observability stage is where the magic happens in our process diagram. In this stage, we are translating the technical security issues into higher-level metrics and scores to inform our decision-makers who are not security experts.
Before we get into the diagram, I want to take a moment to rant about my biggest pet peeve in security. “Critical” has lost all meaning thanks to poor moderation by vendors of security tools. Security scanners aren’t perfect, and there will always be some number of “false positive” findings because of the wide net that they cast. But I think the word “critical” is used so often that we no longer have a term that invokes a swift response without interpretation and guidance from a security professional. If we did have a more urgent term than “critical” it would probably become useless to us too.
This leads us to the second major challenge of vulnerability management: translating risk for non-security professionals and prioritizing vulnerability findings. The observability stage of our vulnerability management process is where we attempt to do that translation.

On the right side of our diagram, we see that observability mainly happens in the places where our software engineers do their work. By taking advantage of features like Pull Request checks and IDE plugins, we are making vulnerabilities relevant where they are relevant. Minimizing context switching is a key focus in DevSecOps architecture that aims to reduce friction for those involved.
On the management-focused side, there is a bit more going on. The Product Owners (POs) or Managers are the ones that make the decisions about what gets worked on. For these people to make informed decisions, we need to present existing vulnerabilities in a way that is digestible for someone who is not a security expert.
Informing POs and managers about vulnerabilities can be as simple as granting them access to the dashboards of our vulnerability scanning tools. All security scanners have their own severity scoring system that attempts to rank the findings, but some tools are better than others. GitGuardian allows you to tune the severities yourself, which is a great feature.
Using individual tools to inform our less technical decision-makers isn’t ideal, though. Decision-makers don’t want to go to a bunch of different dashboards and learn how each tool works. They want a single place they can go to get a clear view of the security risk in the digital products they are responsible for.
To set our decision-makers up for success, we need to distill the multitude of vulnerabilities into a prioritized list that is relevant to our business. A tool category that aims to do this is Application Security Posture Management (ASPM).
The term “ASPM” is relatively new. Garter defined in it May 2023 as a solution that “continuously manages application risk through collection, analysis, and prioritization of security issues across the software life cycle.” The main idea is that you ingest the findings from your vulnerability scanning tools into an ASPM, and it does the prioritization and metrics for you. If you want to read more about ASPM, check out this article from GitGuardian.
I’m not saying you need an ASPM for success, but you will need many of the capabilities that an ASPM provides. For the sake of our process diagram, “ASPM” can refer to a process or solution that provides the following benefits for the observability of security issues:
- “Single pane of glass” overview of your risk across multiple types of vulnerabilities
- Hierarchical grouping of projects, teams, product groups, etc.
- Context-based prioritization based on public exposure, known exploitation, business criticality, commit frequency, etc.
- Deduplication of vulnerabilities across multiple tools
- Generation of SLIs such as time-to-remediation, risk scores, etc.
- Team or developer-based metrics to identify training needs
- Corporate memory (who has fixed similar vulnerabilities that can help)
You may be able to build your own solution for some of these features, or your existing tools might get you close enough. You could also hire someone whose job it is to organize and track vulnerability findings. In the end, the most important outcomes of the observability stage are the metrics and prioritization of your open vulnerability findings. If your vulnerability management program feels like a mess of findings, you’re probably lacking some of the organizational capabilities listed above.
Lastly, as you tune the prioritization or scoring for your observability layer, remember the key warning from this section: if everything is critical, nothing is. Do your best to present the risk in a way that accurately reflects the likelihood and business impact of the vulnerabilities. In the next section, we will cover what it looks like for your product owners or business leaders to make decisions about vulnerability risk and remediation.
Management
Once the team leaders have access to high-fidelity data on their team’s security risk, they can make informed decisions about work selection, risk management, and training opportunities. Below is the last stage of our process diagram.

Most use Jira or another ticketing system to plan and track work. Product owners or managers can use these systems to create issues for vulnerabilities that need to be remediated. If the observability stage has been successful in prioritizing risks, team leaders should be equipped to make informed decisions about this work themselves.
If more guidance is desired, Service Level Objectives (SLOs) are another way to think about work selection. Examples of SLOs could be:
- Introducing no more than 1 preventable vulnerability per sprint cycle
- Remediating critical vulnerabilities within 7 days
- Remediating high vulnerabilities within 4 sprint cycles
These are just made-up examples. Security, product teams, and decision-makers should collaborate on the creation of SLOs to find a balance that works best for the business. Additionally, the security team will continue to play an important role in auditing open vulnerabilities for imminent threats.
There may be times when an SLO is not able to be met. In those cases, the security risk needs to be escalated to higher-level decision-makers along with the current workload of the product team. Security issues must fight for developer time with new features, bug fixes, and tech debt. Sometimes, business leaders may decide to accept the risk of a security issue or delay the fix because they believe it’s in the best interest of the company. Other times, a critical security issue may need to delay the launch of a new feature, and timelines need to be shifted.
The last piece of vulnerability management is an often-overlooked area: security training for non-security personnel. Insights from our observability stage can highlight which types of vulnerabilities a developer or team is struggling with. These insights help security teams and leaders identify training needs.
The most important part of security training is to create a positive learning culture. Security training shouldn’t feel like a punishment. If it does, then the implementation needs some work. A great example of security training is to have a regular security segment in a meeting dedicated to sharing and learning. The security topics covered should prioritize the needs of the audience and be presented in a way that is positive, not pointing fingers.
Final process diagram
Now that we’ve covered each stage of vulnerability management, this is the final process diagram. Here’s a link to a copyable version on Lucidchart that you can use to track your progress. You can color-code areas to mark them as having full, partial, or no coverage.
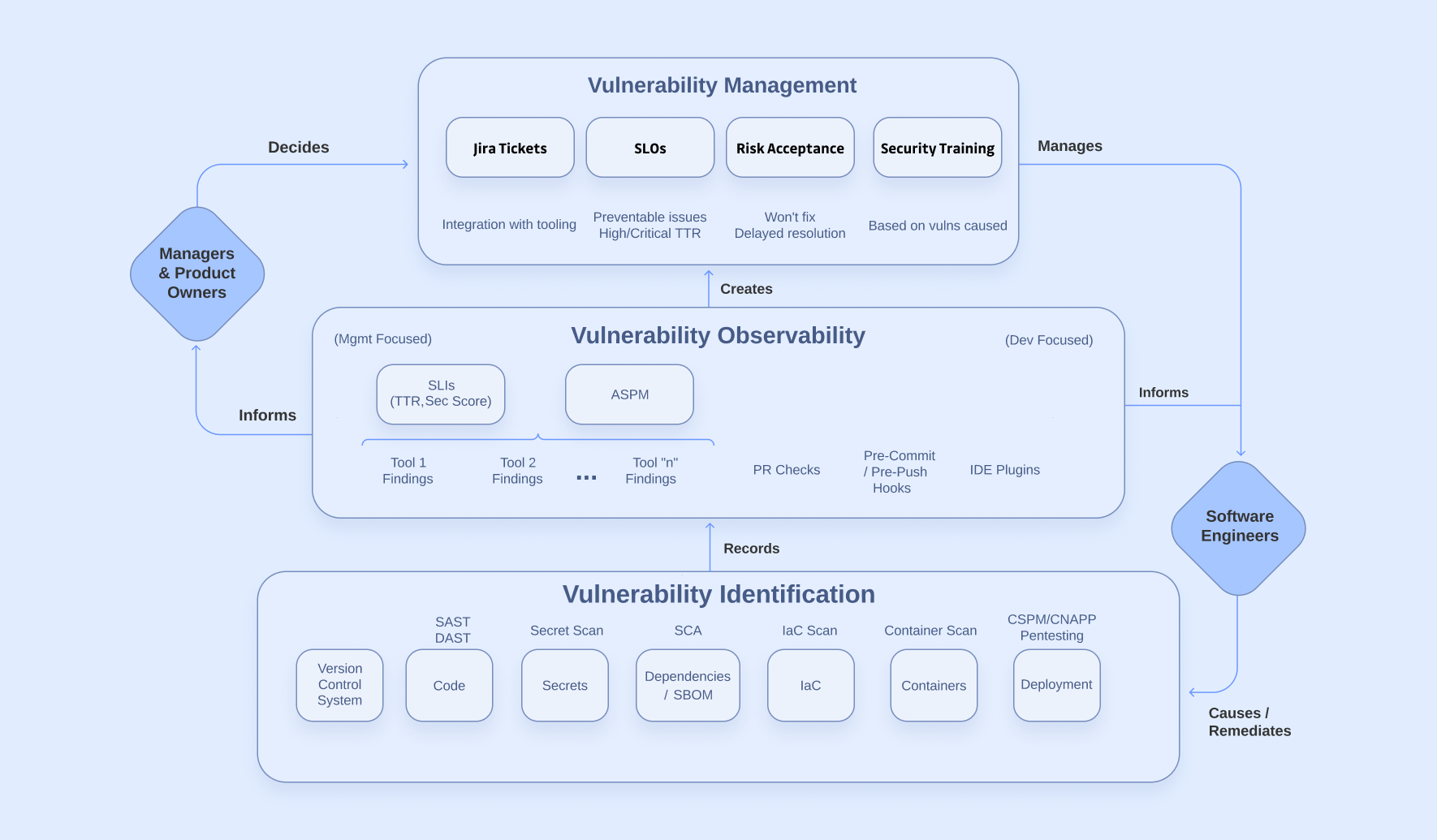
Roles and responsibilities
We’ve covered the whole process diagram, but we still need to define roles and responsibilities. The following section is my suggested role structure to support the success of the vulnerability management process that I’ve laid out in this article.
Software Engineers and Product Owners
Product teams own the security work for the business’s software products. They are responsible for:
- Being aware of the existing vulnerabilities in their team's projects
- Managing and performing the work related to resolving vulnerabilities
- Adhering to security-related SLOs, if any
Managers, Directors, Tech Executives
The higher-level decision makers own or escalate the security risk for the business’s software products. They are responsible for:
- Being aware of critical severity vulnerabilities in the business’s digital products
- Accepting or escalating risk when prioritizing other work over vulnerability remediation
- Working with the business when prioritizing vulnerability remediation over other types of work
- Auditing security-related SLOs, if any
Security Team
The software security team owns the work that supports the success of the vulnerability management process. They are responsible for:
- Managing technical tools for vulnerability identification and prevention
- Providing conceptual and tool-based training for software engineers
- Managing technical tools for vulnerability observability
- Auditing open vulnerabilities for imminent threats
- Consulting for individual vulnerabilities as needed
- Human-operated penetration testing for additional vulnerability identification
- Working with other roles to establish security-related SLOs
Conclusion
We’ve covered a lot in this blog post, so let’s do a quick recap. This blog post showed how technology can support the “people and processes” side of the vulnerability management lifecycle. In the context of DevSecOps, our vulnerability management process includes 3 major stages: identification, observability, and management. In each stage, a considerate implementation of the technologies we covered is critical for setting ourselves up for success. In the end, our goal is to empower digital product teams to make informed decisions about how much work needs to be dedicated to remediating security risks.
After reading this blog post, I hope you’ve got a solid idea of how to approach DevSecOps from the vulnerability management side of software development. The next blog post in this series will cover the software engineering side of things, where we will look at the implementation of controls and automation to create a secure-by-design software development pipeline.
Read more blog posts from these series:
 Guest Expert
Guest Expert Guest Expert
Guest Expert
This article is a guest post. Views and opinions expressed in this publication are solely those of the author and do not reflect the official policy, position, or views of GitGuardian, The content is provided for informational purposes, GitGuardian assumes no responsibility for any errors, omissions, or outcomes resulting from the use of this information. Should you have any enquiry with regard to the content, please contact the author directly.








