
![Best Practices for Managing and Storing Secrets Including API Keys and Other Credentials [cheat sheet included]](/content/images/size/w2000/2020/06/20W22-BLOG-Banner-BestPractices-Final@2x.png)
Storing and managing secrets like API keys and other credentials can be challenging. Even the most careful policies can sometimes be circumvented in exchange for convenience. We have compiled a list of some of the best practices to prevent API key leakage and keep secrets and credentials safe.
Secrets management doesn’t have a one-size-fits-all approach, so this list considers multiple perspectives so you can be informed in deciding to or not to implement strategies.

Directory
- Never store unencrypted secrets in .git repositories
- Don’t share your secrets unencrypted in messaging systems like Slack
- Store secrets safely
- Use encryption to store secrets within .git repositories
- Use environment variables
- Use "Secrets as a service" solutions
- Restrict API keys access and permissions
Never store unencrypted secrets in .git repositories
It is common to wrongly assume that private repositories are secure vaults that are safe places to store secrets. Private repositories are not appropriate places to store secrets.
Private repositories are high-value targets for bad actors because it is common practice to store secrets within them.
In addition, .git is designed to sprawl. Repositories get cloned onto new machines, forked into new projects and new developers regularly enter and exit a project with access to complete history. Any hard-coded secrets that exist within a private repository's history will exist in all new repositories born from that source.
If a secret enters a repository, private or public, then it should be considered compromised.
A secret in a private repo is like a password written on a $20 bill, you might trust the person you gave it to, but that bill can end up in hundreds of peoples hands as a part of multiple transactions and within multiple cash registers.
If already committed and want to remove an API key from the git history, follow the guidelines below:
 Guest Expert
Guest Expert
Avoid git add * commands on git
Using wildcard commands like git add * or git add . can easily capture files that should not enter a git repository. This includes generated files, config files, and temporary source code.
To avoid that, when making a commit, you should preferably add each file by name and use git status to list tracked and untracked files. According to git-scm:
“Remember that each file in your working directory can be in one of two states: tracked or untracked.
Tracked files are files that were in the last snapshot; they can be unmodified, modified, or staged. In short, tracked files are files that Git knows about.
Untracked files are everything else.”
Advantages
- Complete control and visibility over what files are committed
- Reduces the risk of unwanted files entering source control and API key leak
- Requires thought and consideration when adding files
Disadvantages
- Takes additional time when making a commit
- Can mistakenly miss files when committing
TIP: Committing early and committing often will not only help navigate file history and break up otherwise large tasks, in addition it will reduce the temptation to use wildcard commands.
Add sensitive files in .gitignore
To prevent sensitive files from ending up within git repositories a comprehensive .gitignore file should be included with all repositories and include:
- Files with environment variables like
.envor configuration files like.zshrc,application.propertiesor.config - Files generated by another process (such as application logs or checkpoints, unit tests/coverage reports)
- Files containing “real” data (other than test data) like database extracts.
GitHub published a collection of useful .gitignore templates. See these examples for Python or Go.
Don’t rely on code reviews to discover secrets
It is extremely important to understand that code reviews will not always detect hard-coded secrets, especially if they are hidden in previous versions of code. The reason code reviews are not adequate protection is because reviewers are only concerned with the difference between the current and proposed states of the code; they do not consider the entire history of the project.
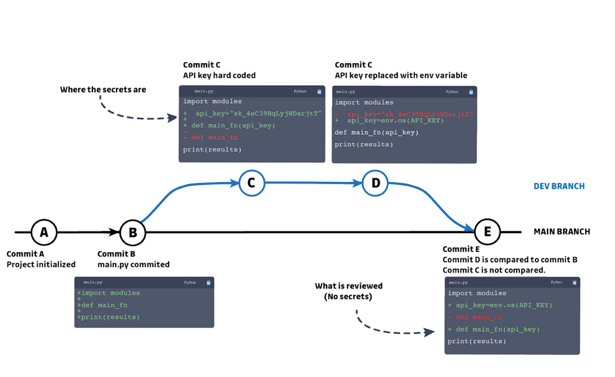
If secrets are committed to a development branch and later removed, these secrets won’t be visible or of importance to the reviewer. The nature of git means that if a secret gets overlooked in history it is exposed forever as anyone with access to the repository can find this secret in previous revisions of the codebase.
TIP: As a rule, automation should be implemented wherever predefined rules can be established, like secrets detection. Human reviews should be left to check code for errors that cannot be easily predefined, such as logic.
Use automated secrets scanning on repositories
Even when all best practices are followed, mistakes are common. When dealing with highly sensitive data, no chances should be taken. GitGuardian offers a free secrets scanning solution for developers to detect both generic API keys and specific secrets (more than 450 providers are supported!).
But the best is that it can be installed both on private and public repositories for free!
Visibility is the key to great secret management. If you don’t know you have a problem, you cannot take action to fix it. Secrets scanning provides essential visibility over your internal systems.
It is important to also consider that even the best secrets management systems and policies do not prevent newly generated secrets from entering the code base or old secrets from being extracted and included again.
Advantages
- Difficult to circumvent and ignore compared to tools that need to be manually run
- Much faster and more accurate than relying on human checking
- Can detect secrets buried within logs and history that manual reviews and searches will not uncover
- Live scanning ensures all active data leaks are captured
Don’t share your secrets unencrypted in messaging systems like Slack
A common secret sprawl enabler is sending secrets in plain text over messaging services. While these systems are intended to keep messages secure, they are not intended to hold sensitive information such as secrets.
These systems are high-value targets for attackers. It only takes one compromised email or Slack account to uncover a trove of sensitive information. If secrets are being sent over internal systems, it also makes it possible for bad actors to move laterally between services by ‘using secrets to find secrets’.
Store secrets safely
There is no silver bullet solution for secrets management. Different factors such as project size, team geography, and project scope, must be considered. Multiple solutions may need to coexist. Carefully consider each option, not just to meet your current needs but also to consider how each solution will scale with the growth of your project.
Use encryption to store secrets within .git repositories
Encrypting your secrets using common tools such as git secret or SOPS and storing them within a git repository can be beneficial when working in teams as it keeps secrets synced.
However, it's important to note that this approach introduces a new challenge—managing additional security keys for encryption and decryption, as well as securely sharing them. This aspect may seem like an ongoing concern, but it's a vital aspect to address for robust security practices.
Advantages
- Your secrets are synced
Disadvantages
- You have to deal with your encryption keys securely
- No audit logs (who accessed which secret and when)
- No role-based access control (RBAC)
- Hard to rotate access. Rotating access implies revoking the key and redistributing it. The distribution part is not easy to handle with git repositories when dealing with multiple developers
Use local environment variables when feasible
An environment variable is a dynamic object whose value is set outside of the application. This makes them easier to rotate without having to make changes within the application itself. It also removes the need to have these written within source code, making them more appropriate for handling sensitive data.
Advantages
- They are easy to change between deployed versions without changing any code
- They are less likely to be checked into the repository
- Simple and clean
Disadvantages
- This approach may not be feasible at scale when working in teams because there is no way to easily keep developers, applications, and/or infrastructure in sync.
Use Secrets Management Tools to Enhance API Security
Secrets management systems such as Hashicorp Vault or AWS Key Management Service are encrypted systems that can safely store your secrets and tightly control access. Vaults and other managed secrets solutions are not appropriate in all cases because they are complicated to set up and need to be well maintained. Both take a considerable investment of resources.
Advantages
- It prevents secrets from sprawling
- It provides audit logs
Disadvantages
- As they introduce a single point of failure, they must be hosted on a highly-available and secure infrastructure
- All the codebase must be changed to integrate with them
- Keys giving access to the system must be carefully protected
Restrict API access and permissions
It can be difficult to detect when an attacker is using secrets like API keys maliciously because they are often using them within their scope. By restricting the access and permissions of the API key you not only limit damage and restrict lateral movement but also provide greater visibility over when the API key is being used outside of its scope.
Default to minimal permission scope for APIs
When using external services, make sure the permissions of that API match the task it is fulfilling. This includes making sure you have separate APIs for read-only and read/write permissions as needed.
Many APIs also allow you to have increased control over what data can be accessed. For example, the Slack API has a large range of scopes, and restricting these scopes to meet the task's minimal requirements of the task is important to prevent an attacker from accessing sensitive data. It is common for inexperienced developers to use API keys with excessive permissions allowing them to use one key throughout their project. But this increases the potential damage of a data breach. Learn about Identity and Access Management best practices here:
Dwayne McDaniel
Whitelist IP addresses where appropriate
IP whitelisting provides an additional layer of security against bad actors attempting to use APIs nefariously. By providing a whitelist of IP addresses from your private network, your external services will only accept requests from those trusted sources. It is common to include a range of acceptable IP addresses or a network IP address.
In an example from GitHub, you can use IP whitelisting to prevent any untrusted sources from accessing your GitHub repositories. “The allow list for IP addresses will block access via the web, API, and Git from any IP addresses that are not on the allow list.”
Advantages
- Limited requests to select trusted sources and prevents attacks from external sources even with secret keys
Disadvantages
- Not always feasible depending on the traffic the source is expecting
- Can prevent legitimate information requests
- Needs to be maintained constantly
Use short-lived secrets
It is common for APIs to typically provide long-lasting (or long-lived) access tokens. These tokens could last indefinitely. While this is convenient for developers, it means that a secret poses the same security risks for its entire life and increases the chances of them being used in an attack. By using short-lived secrets, the risk of undetected leaked API keys is mitigated, ensuring that even if an attacker gains access to a secret, it would be harmless.
It is also good practice to make sure you revoke and rotate all API keys often, particularly if it is not possible to introduce a validity period on APIs.
Imagine you own a company with hundreds of employees that all have keys to your office, keys will inevitably get lost, employees will leave the company, new keys will get cut and you will soon lose visibility over where each key is. It would be widely considered good practice to change the locks from time to time.
Advantages
- Enforces good secret hygiene
- Reduces the risk of long-term threats
Disadvantages
- Requires an active secrets management strategy
Conclusion
Managing secrets and storing secrets is a challenge that requires vigilance from even the most experienced developer, who needs to carefully consider how they are using, storing, sharing, and distributing secrets. Unfortunately, there is no perfect checklist that a developer can follow.
Policies, tools, and strategies will differ from projects, but it is crucial for developers to understand the consequences of policies so that secrets management can be an informed, active strategy throughout the entire development process.

Summary: Best Practices for API Key and Other Credentials Security
- Never store unencrypted secrets in .git repositories
- Avoid
git add *commands on git - Add sensitive files in .gitignore
- Don’t rely on code reviews to discover secrets
- Use automated secrets scanning on repositories
- Avoid
- Don’t share your secrets unencrypted in messaging systems like Slack
- Store secrets safely
- Use encryption to store secrets within .git repositories
- Use environment variables
- Use "Secrets as a service" solutions
- Restrict API keys access and permissions
- Default to minimal permission scope for APIs
- Whitelist IP addresses where appropriate
- Use short-lived secrets
If you want comprehensive guidelines on how to handle secrets with popular DevOps tools such as Docker, Jenkins, Python, AWS, or Kubernetes, have a look at this GitGuardian collection of articles:
Ziad Ghalleb
Finally, if you want to accelerate your learning journey in the world of code security, dive into our collection of cheat sheets: from how to correctly set up multiple GitHub accounts, using GitHub Actions, or manipulate secrets on the command line to understanding IAM best practices, securing infrastructure as code and Docker.
And much more!

![How to Handle Secrets at the Command Line [cheat sheet included]](/content/images/size/w600/2022/10/22W40-blog-SecretsAtTheCommandLine-Cheatsheet.jpg)

![Docker Security Best Practices [cheat sheet included]](/content/images/size/w600/2021/07/21W30-Blog-Docker-Security-Cheatsheet-Final.jpg)

![Using GitGuardian Honeytoken [cheat sheet included]](/content/images/size/w600/2023/07/Using-GitGuardian-Honeytoken-Cheat-Sheet-article.png)
![Secure Code Review Best Practices [cheat sheet included]](/content/images/size/w600/2023/07/Secure-Code-Review-Cheat-Sheet.jpg)


